溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何掌握正則表達式”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何掌握正則表達式”吧!
字符說明\轉義符\d[0-9]。表示是一位數字。\D[^0-9]。表示除數字外的任意字符。\w[0-9a-zA-Z_]。表示數字、大小寫字母和下劃線。\W[^0-9a-zA-Z_]。非單詞字符。\s[\t\v\n\r\f]。表示空白符,包括空格、水平制表符、
垂直制表符、換行符、回車符、換頁符。\S[^\t\v\n\r\f]。非空白符。.[^\n\r]。通配符,表示幾乎任意字符。
換行符、回車符、行分隔符和段分隔符除外。\uxxxx查找以十六進制數 xxxx 規定的 Unicode 字符。\f匹配一個換頁符 (U+000C)。\n匹配一個換行符 (U+000A)。\r匹配一個回車符 (U+000D)。\t匹配一個水平制表符 (U+0009)。\v匹配一個垂直制表符 (U+000B)。\0匹配 NULL(U+0000)字符, 不要在這后面跟其它小數,因為 \0是一個
八進制轉義序列。[\b]匹配一個退格(U+0008)。(不要和\b 混淆了。)[abc]any of a, b, or c[^abc]not a, b, or c[a-g]character between a & g
字符說明\b是單詞邊界,具體就是\w 和\W 之間的位置,也包括\w 和 ^ 之間的位置,
也包括\w 和之間的位置。具體說來就是與、與、與,與之間的位置。\B是\b 的反面的意思,非單詞邊界。例如在字符串中所有位置中,扣掉\b,
剩下的都是\B 的。^abc$字符串開始、結束的位置
字符說明(abc)capture group,捕獲組\nbackreference to group #n,分組引用,引用第 n 個捕獲組匹配的內容,
其中 n 是正整數(?:abc)non-capturing group,非捕獲組
字符說明a(?=b)positive lookahead,先行斷言,a 只有在 b 前面才匹配a(?!b)negative lookahead,先行否定斷言,a 只有不在 b 前面才匹配
字符說明(?<=b)apositive lookbehind,后行斷言,a 只有在 b 后面才匹配(?<!b)anegative lookbehind,后行否定斷言,a 只有不在 b 后面才匹配
字符說明a*0 or morea+1 or morea?0 or 1a{5}exactly fivea{2,}two or morea{1,3}between one & threea+?
a{2,}?match as few as possible,惰性匹配,就是盡可能少的匹配
以下都是惰性匹配:
{m,n}?
{m,}?
??
+?
*?
字符說明ab|cdmatch ab or cd,匹配'ab'或者'cd'字符子串
字符說明i執行對大小寫不敏感的匹配。g執行全局匹配(查找所有匹配而非在找到第一個匹配后停止)。m執行多行匹配。u開啟"Unicode 模式",用來正確處理大于\uFFFF 的 Unicode 字符。也就是說,會正確處理四個字節的 UTF-16 編碼。s允許 . 匹配換行符。yy 修飾符的作用與 g 修飾符類似,也是全局匹配,后一次匹配都從上一次匹配成功的下一個位置開始。不同之處在于,g 修飾符只要剩余位置中存在匹配就可,而 y 修飾符確保匹配必須從剩余的第一個位置開始,這也就是"粘連"的涵義
運算符描述\轉義符(), (?:), (?=), []圓括號和方括號*, +, ?, {n}, {n,}, {n,m}限定符^, $, \任何元字符、任何字符定位點和序列(即:位置和順序)|替換,"或"操作
字符具有高于替換運算符的優先級,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",請使用括號創建子表達式,從而產生"(m|f)ood"。
以下是來自摘自維基百科的部分解釋:
回溯法是一種通用的計算機算法,用于查找某些計算問題的所有(或某些)解決方案,特別是約束滿足問題,逐步構建候選解決方案,并在確定候選不可能時立即放棄候選("回溯")完成有效的解決方案。
回溯法通常用最簡單的遞歸方法來實現,在反復重復上述的步驟后可能出現兩種情況:
找到一個可能存在的正確的答案
在嘗試了所有可能的分步方法后宣告該問題沒有答案
在最壞的情況下,回溯法會導致一次復雜度為指數時間的計算。
正則引擎主要可以分為兩大類:一種是 DFA(Deterministic finite automaton 確定型有窮自動機),另一種是 NFA(NFA Non-deterministic finite automaton 非確定型有窮自動機)。NFA 速度較 DFA 更慢,并且實現復雜,但是它又有著比 DFA 強大的多的功能,比如支持反向引用等。像 javaScript、java、php、python、c#等語言的正則引擎都是 NFA 型,NFA 正則引擎的實現過程中使用了回溯。
舉一個網上常見的例子,正則表達式/ab{1,3}c/g 去匹配文本'abbc',我們接下來會通過 RegexBuddy 分析其中的匹配過程,后續的一個章節有關于 RegexBuddy 的使用介紹。
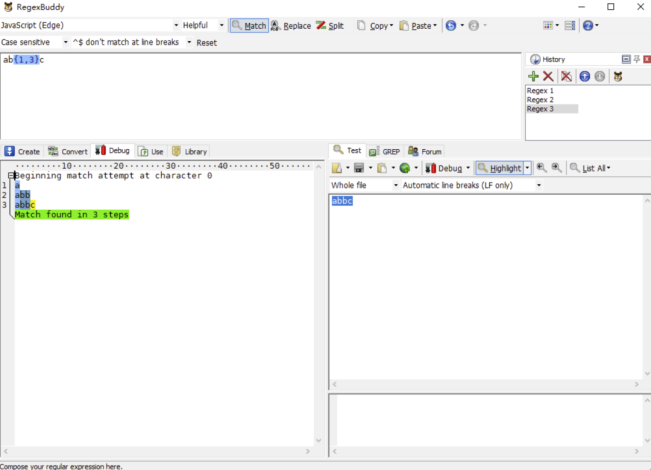
如上圖所示,讓我們一步一步分解匹配過程:
正則引擎先匹配 a。
正則引擎盡可能多地(貪婪)匹配 b。
正則引擎匹配 c,完成匹配。
在這之中,匹配過程都很順利,并沒發生意外(回溯)。
讓我們把上面的正則修改一下,/ab{1,3}c/g 改成/ab{1,3}bc/g,接下再通過 RegexBuddy 查看分析結果。
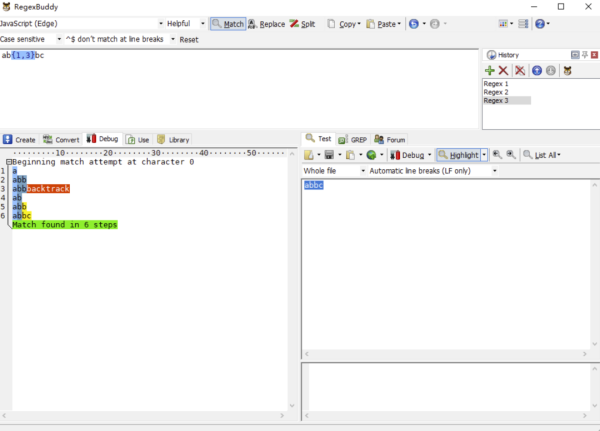
我們再一步一步分解匹配過程:
正則引擎先匹配 a。
正則引擎盡可能多地(貪婪)匹配 b{1,3}中的 b。
正則引擎去匹配 b,發現沒 b 了,糟糕!趕緊回溯!
返回 b{1,3}這一步,不能這么貪婪,少匹配個 b。
正則引擎去匹配 b。
正則引擎去匹配 c,完成匹配。
以上,就是一個簡單的回溯過程。
從上面發生正則回溯的例子可以看出來,正則回溯的過程就是一個試錯的過程,這也是回溯算法的精髓所在。回溯會增加匹配的步驟,勢必會影響文本匹配的性能,所以,要想提升正則表達式的匹配性能,了解回溯出現的場景(形式)是非常關鍵的。
在 NFA 正則引擎中,量詞默認都是貪婪的。當正則表達式中使用了下表所示的量詞,正則引擎一開始會盡可能貪婪的去匹配滿足量詞的文本。當遇到匹配不下去的情況,就會發生回溯,不斷試錯,直至失敗或者成功。
量詞說明a*0 or morea+1 or morea?0 or 1a{5}exactly fivea{2,}two or morea{1,3}between one & three
當多個貪婪量詞挨著存在,并相互有沖突時,秉持的是"先到先得"的原則,如下所示:
let string = "12345"; let regex = /(\d{1,3})(\d{1,3})/; console.log( string.match(regex) ); // => ["12345", "123", "45", index: 0, input: "12345"]貪婪是導致回溯的重要原因,那我們盡量以懶惰匹配的方式去匹配文本,是否就能避免回溯了呢?答案是否定的。
讓我們還是看回最初的例子,/ab{1,3}c/g 去匹配 abbc。接下來,我們再把正則修改一下,改成/ab{1,3}?c/g 去匹配 abbc,以懶惰匹配的方式去匹配文本,RegexBuddy 執行步驟如下圖所示:
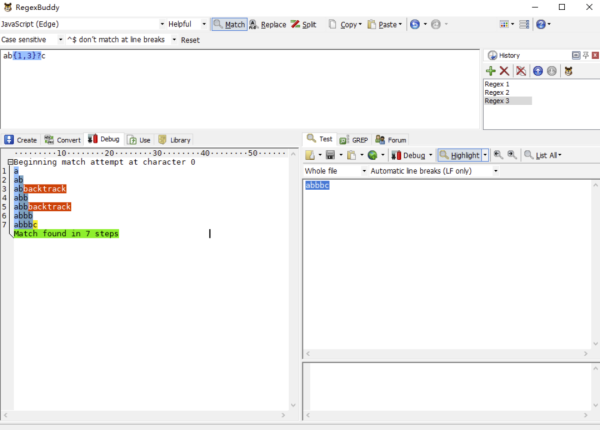
正則引擎先匹配 a。
正則引擎盡可能少地(懶惰)匹配 b{1,3}中的 b。
正則引擎去匹配 c,糟糕!怎么有個 b 擋著,匹配不了 c 啊!趕緊回溯!
返回 b{1,3}這一步,不能這么懶惰,多匹配個 b。
正則引擎再去匹配 c,糟糕!怎么還有 b 擋著,匹配不了 c 啊!趕緊回溯!
返回 b{1,3}這一步,不能這么懶惰,再多匹配個 b。
正則引擎再去匹配 c,匹配成功,棒棒噠!
本來是好端端不會發生回溯的正則,因為使用了惰性量詞進行懶惰匹配后,反而產生了回溯了。所以說,惰性量詞也不能瞎用,關鍵還是要看場景。
分支的匹配規則是:按照分支的順序逐個匹配,當前面的分支滿足要求了,則舍棄后面的分支。
舉個簡單的分支栗子,使用正則表達式去匹配 /abcde|abc/g 文本 abcd,還是通過 RegexBuddy 查看執行步驟:
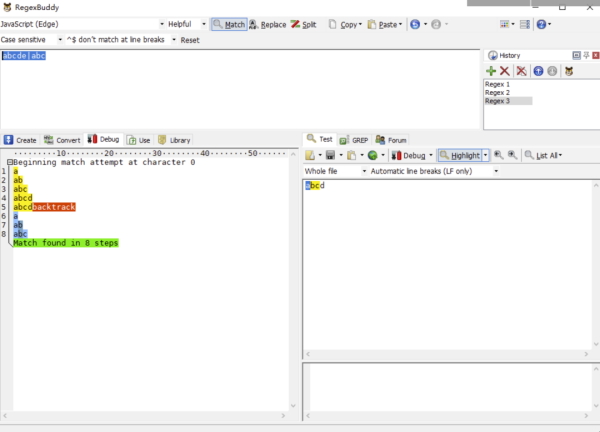
正則引擎匹配 a。
正則引擎匹配 b。
正則引擎匹配 c。
正則引擎匹配 d。
正則引擎匹配 e,糟糕!下一個并不是 e,趕緊回溯!
上一個分支走不通,切換分支,第二個分支正則引擎匹配 a。
第二個分支正則引擎匹配 b。
第二個分支正則引擎匹配 c,匹配成功!
由此,可以看出,分組匹配的過程,也是個試錯的過程,中間是可能產生回溯的。
RegexBuddy 是個十分強大的正則表達式學習、分析及調試工具。RegexBuddy 支持 C++、Java、JavaScript、Python 等十幾種主流編程語言。通過 RegexBuddy,能看到正則一步步創建的過程。結合測試文本,你能看到正則一步步執行匹配的過程,這對于理解正則回溯和對正則進行進一步優化,都有極大的幫助。
可以在 RegexBuddy 的官方網站下載及獲取 RegexBuddy。
下載完后,一步步點擊安裝即可。
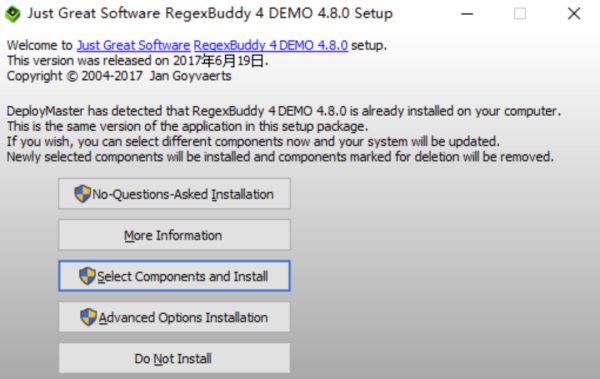
下圖便是 RegexBuddy 界面的各個面板及相關功能。
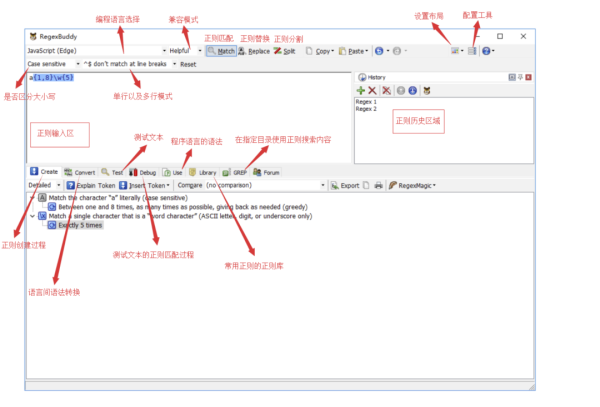
為了方便使用,可以在布局設置那里將布局設置成 Side by Side Layout。
在正則輸入區輸入你的正則 regex1,查看 Create 面板,就會發現面板上顯示了正則的創建過程(或者說是匹配規則),在 Test 面板區域輸入你的測試文本,滿足 regex1 匹配規則的部分會高亮顯示,如下圖所示。
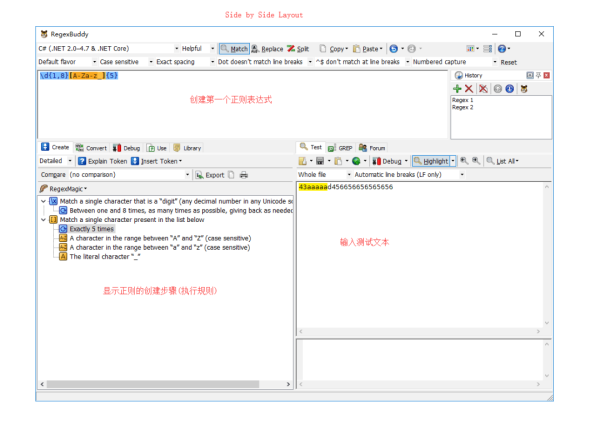
選中測試文本,點擊 debug 就可以進入 RegexBuddy 的 debug 模式,個人覺得這是 RegexBuddy 最強大地方,因為它可以讓你清楚地知道你輸入的正則對測試文本的匹配過程,執行了多少步,哪里發生了回溯,哪里需要優化,你都能一目了然。
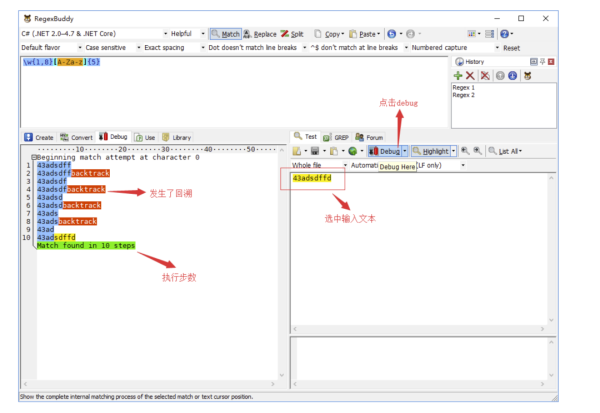
RegexBuddy 的正則庫內置了很多常用正則,日常編碼過程中需要的很多正則表達式都能在該正則庫中找到。
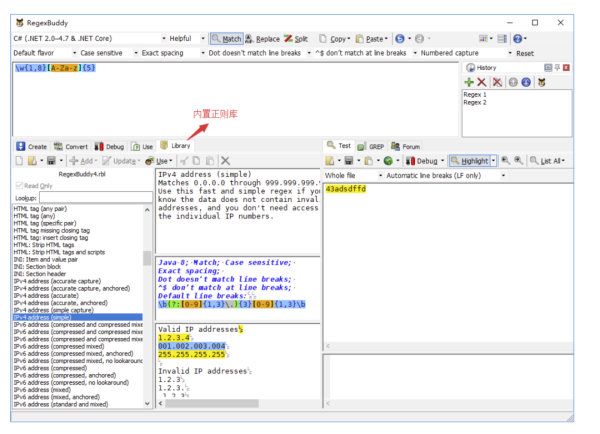
正則可視化-regexper
正則可視化-regulex
正則在線調試
正則是個很好用的利器,如果使用得當,如有神助,能省掉大量代碼。當如果使用不當,則是處處埋坑。所以,本章節的重點就是總結如何寫一個高性能的正則表達式。
舉個簡單的例子對比:
我們使用正則表達式/a*b/去匹配字符串 aaaaa,看下圖 RegexBuddy 的執行過程:

我們將以上正則修改成/(a*)*b/去匹配字符串 aaaaa,再看看 RegexBuddy 的執行結果過程:
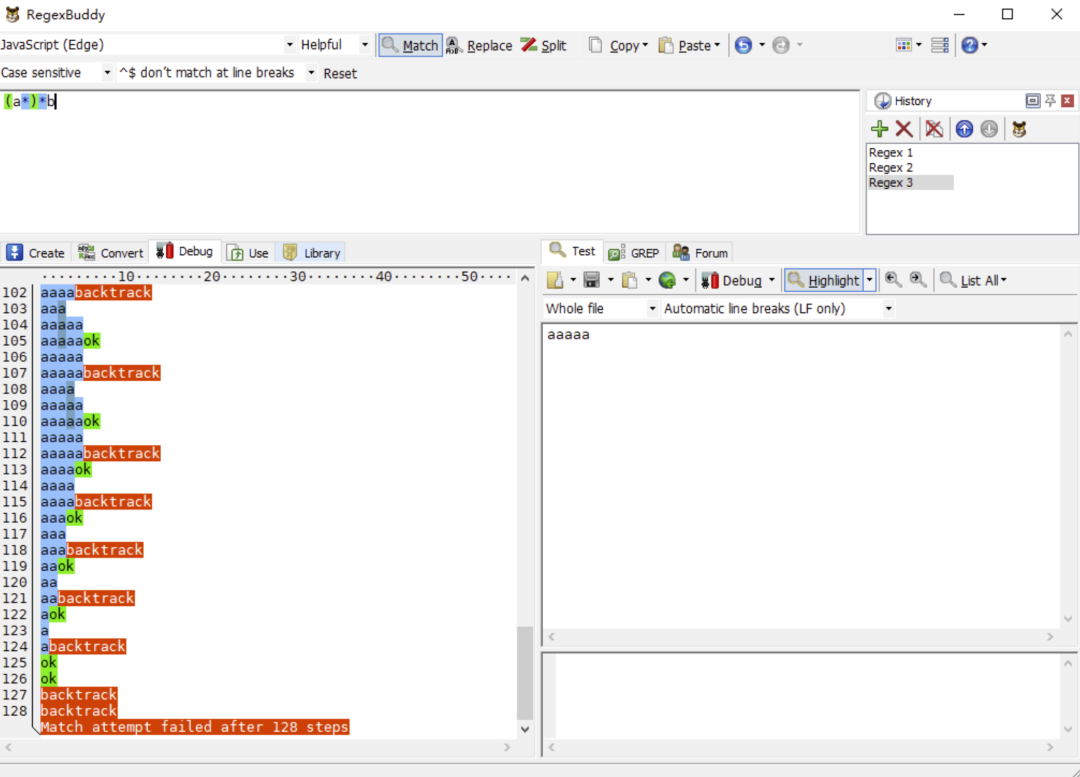
以上兩個正則的基本執行步驟可以簡單認為是:
貪婪匹配
回溯
直至發現匹配失敗
但令人驚奇的是,第一個正則的從開始匹配到匹配失敗這個過程只有 14 步。而第二個正則卻有 128 步之多。可想而知,嵌套量詞會大大增加正則的執行過程。因為這其中進行了兩層回溯,這個執行步驟增加的過程就如同算法復雜度從 O(n)上升到 O(n^2)的過程一般。
所以,面對量詞嵌套,我們需作出適當的轉化消除這些嵌套:
(a*)* <=> (a+)* <=> (a*)+ <=> a* (a+)+ <=> a+
NFA 正則引擎中的括號主要有兩個作用:
主流功能,提升括號中內容的運算優先級
反向引用
反向引用這個功能很強大,強大的代價是消耗性能。所以,當我們如果不需要用到括號反向引用的功能時,我們應該盡量使用非捕獲組,也就是:
// 捕獲組與非捕獲組 () => (?:)
分支也是導致正則回溯的重要原因,所以,針對正則分支,我們也需要作出必要的優化。
首先,需要減少分支數量。比如不少正則在匹配 http 和 https 的時候喜歡寫成:
/^http|https/
其實上面完全可以優化成:
/^https?/
這樣就能減少沒必要的分支回溯
縮小分支中的內容也是很有必要的,例如我們需要匹配 this 和 that ,我們也許會寫成:
/this|that/
但上面其實完全可以優化成
/th(?:is|at)/
有人可能認為以上沒啥區別,實踐出真知,讓我們用以上兩個正則表達式去匹配一下 that。
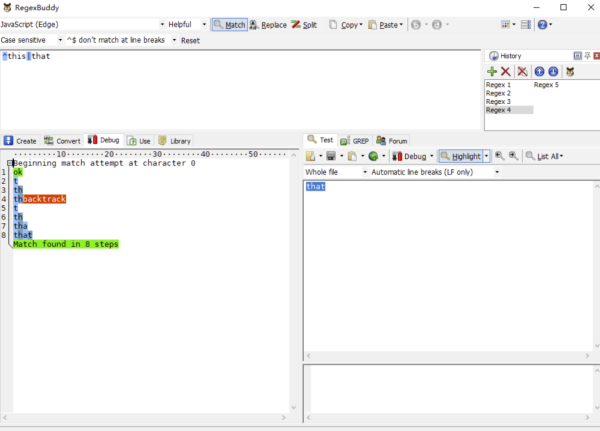
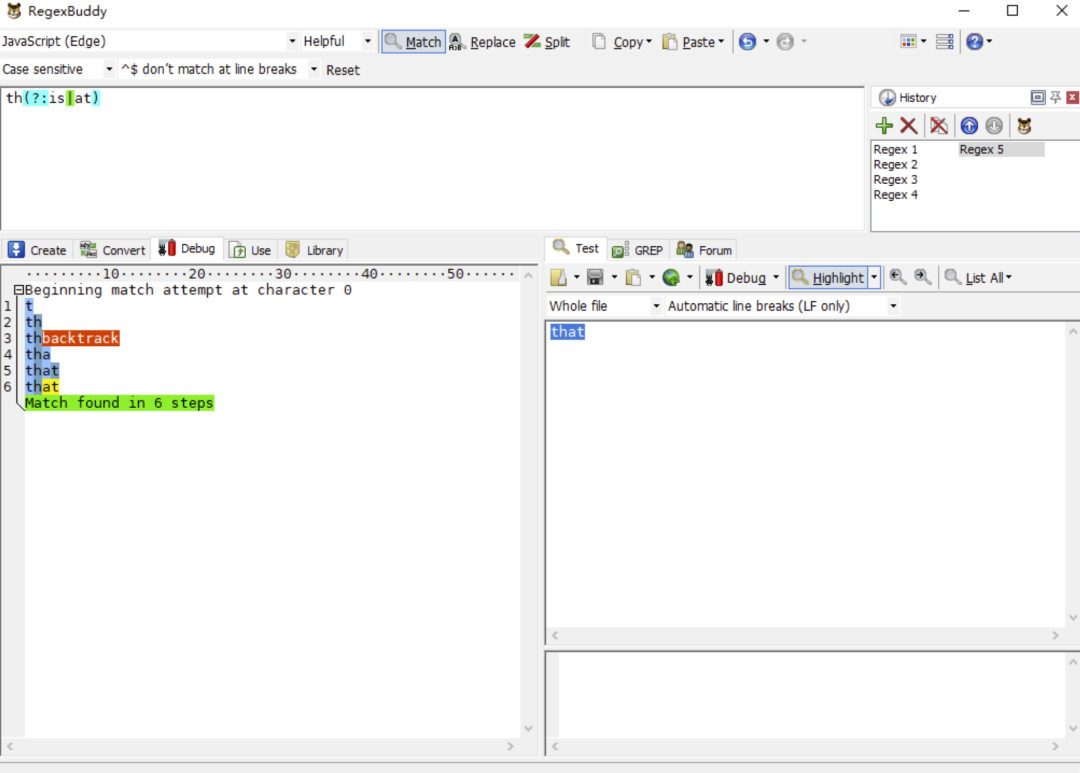
我們會發現第一個正則的執行步驟比第一個正則多兩步,那是因為第一個正則的回溯路徑比第二個正則的回溯路徑更長了,最終導致執行步驟變長。
在能使用錨點的情況下盡量使用錨點。大部分正則引擎會在編譯階段做些額外分析, 判斷是否存在成功匹配必須的字符或者字符串。類似^、$ 這類錨點匹配能給正則引擎更多的優化信息。
例如正則表達式 hello(hi)?$ 在匹配過程中只可能從字符串末尾倒數第 7 個字符開始, 所以正則引擎能夠分析跳到那個位置, 略過目標字符串中許多可能的字符, 大大提升匹配速度。
感謝各位的閱讀,以上就是“如何掌握正則表達式”的內容了,經過本文的學習后,相信大家對如何掌握正則表達式這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





