溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何將JavaScript中數據結構的數組與對象進行比較,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
在編程中,如果你想繼續深入,數據結構是我們必須要懂的一塊, 學習/理解數據結構的動機可能會有所不同,一方面可能是為了面試,一方面可能單單是為了提高自己的技能或者是項目需要。無論動機是什么,如果不知道什么是數組結構及何時使用應用字們,那學數據結構是一項繁瑣且無趣的過程 ?
Big O notation 大零符號一般用于描述算法的復雜程度,比如執行的時間或占用內存(磁盤)的空間等,特指最壞時的情形。
數組
數組是使用最廣泛的數據結構之一。數組中的數據以有序的方式進行結構化,即數組中的第一個元素存儲在索引0中,第二個元素存儲在索引1中,依此類推。JavaScript為我們提供了一些內置的數據結構,數組就是其中之一 ?
在JavaScript中,定義數組最簡單的方法是:
let arr = []
上面的代碼行創建了一個動態數組(長度未知),為了了解如何將數組的元素存儲在內存中,我們來看一個示例:
let arr = ['John', 'Lily', 'William', 'Cindy']
在上面的示例中,我們創建一個包含一些人名的數組。內存中的名稱按以下方式存儲:
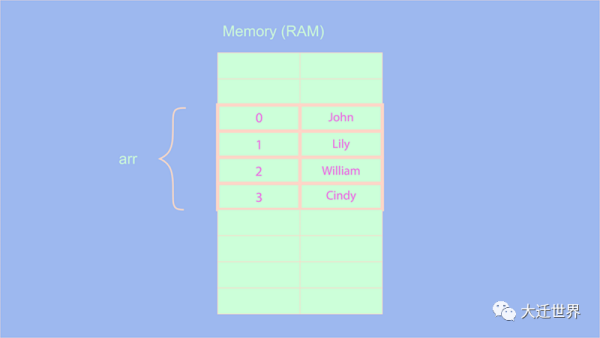
為了理解數組是如何工作的,我們需要執行一些操作:
添加元素:
在JavaScript數組中,我們有不同方式在數組結尾,開關以及特定索引處添加元素。
在數組的末尾添加一個元素:
JavaScript 中的數組有一個默認屬性 length,它表示數組的長度。除了length屬性外,JS還提供了 push() 方法。使用這個方法,我們可以直接在最后添加一個元素。
arr.push('Jake')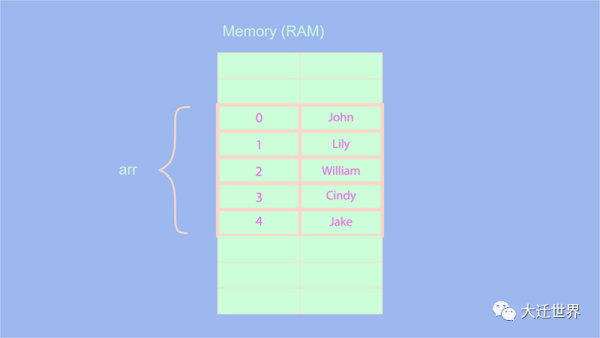
那么這個命令的復雜度是多少呢?我們知道,在默認情況下,JS提供了length屬性,push()相當于使用以下命令:
arr[arr.length - 1] = 'Jake'
因為我們總是可以訪問數組的長度屬性,所以無論數組有多大,在末尾添加一個元素的復雜度總是O(1) ?。
在數組的開頭添加一個元素:
對于此操作,JavaScript提供了一個稱為unshift()的默認方法,此方法將元素添加到數組的開頭。
let arr = ['John', 'Lily', 'William', 'Cindy'] arr.unshift('Robert') console.log(arr) // [ 'Robert', 'John', 'Lily', 'William', 'Cindy' ]unshift方法復雜度好像和push方法的復雜度一樣:O(1),因為我們只是在前面添加一個元素。事實并非如此,讓我們看一下使用unshift方法時會發生什么:
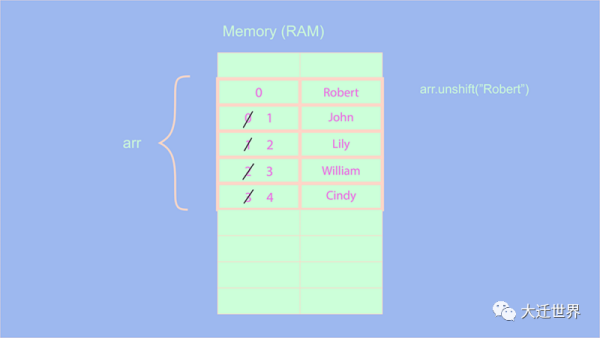
在上圖中,當我們使用unshift方法時,所有元素的索引應該增加1。這里我們的數組個數比較少,看不出存在的問題。想象一下使用一個相當長的數組,然后,使用unshift這樣的方法會導致延遲,因為我們必須移動數組中每個元素的索引。因此,unshift操作的復雜度為O(n) ?。
如果要處理較大長度的數組,請明智地使用unshift方法。在特定索引處添加元素,我們可以 splice() 方法,它的語法如下:
splice(startingIndex, deleteCount, elementToBeInserted)
因為我們要添加一個元素,所以deleteCount將為0。例如, 我們想要在數組索引為2的地方新加一個元素,可以這么用:
let arr = ['John', 'Lily', 'William', 'Cindy'] arr.splice(2, 0, 'Janice') console.log(arr) // [ 'John', 'Lily', 'Janice', 'William', 'Cindy' ]
你覺得這個操作的復雜性是多少?在上面的操作中,我們在索引2處添加了元素,因此,在索引2之后的所有后續元素都必須增加或移動1(包括之前在索引2處的元素)。
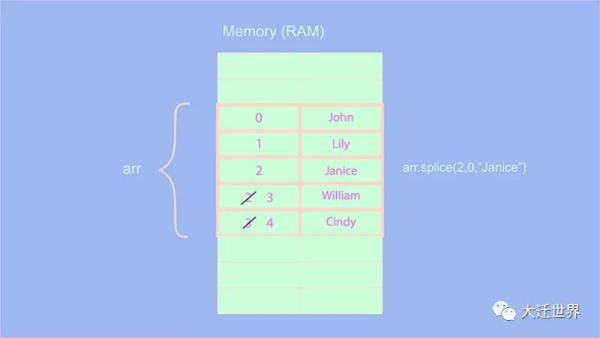
可以觀察到,我們不是在移動或遞增所有元素的索引,而是在索引2之后遞增元素的索引。這是否意味著該操作的復雜度為 `O(n/2)?不是 ?。根據Big O規則,常量可以從復雜性中刪除,而且,我們應該考慮最壞的情況。因此,該操作的復雜度為O(n) ?。
刪除元素:
就像添加元素一樣,刪除元素可以在不同的位置完成,在末尾、開始和特定索引處。
在數組的末尾刪除一個元素:
像 push( )一樣,JavaScript提供了一個默認方法pop(),用于刪除/刪除數組末尾的元素。
let arr = ['Janice', 'Gillian', 'Harvey', 'Tom'] arr.pop() console.log(arr) // [ 'Janice', 'Gillian', 'Harvey' ] arr.pop() console.log(arr) // [ 'Janice', 'Gillian' ]
該操作的復雜度為O(1)。因為,無論數組有多大,刪除最后一個元素都不需要改變數組中任何元素的索引。
在數組的開頭刪除一個元素:
JavaScript 提供了一個默認方法shift() 的默認方法,此方法刪除數組的第一個元素。
let arr = ['John', 'Lily','William','Cindy'] arr.shift() console.log(arr) // ['Lily','William','Cindy'] arr.shift() console.log(arr);// ['William','Cindy']
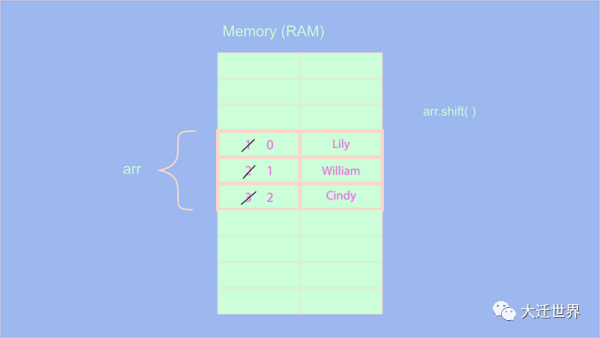
從上面我們很容易可以看出 shift()操作的復雜度為O(n) ,因為刪除第一個元素后,我們必須將所有元素的索引移位或減量1。
在特定索引處刪除:
對于此操作,我們再次使用splice()方法,不過這一次,我們只使用前兩個參數,因為我們不打算在該索引處添加新元素。
let arr = ['Apple', 'Orange', 'Pear', 'Banana','Watermelon'] arr.splice(2,1) console.log(arr) // ['Apple', 'Orange', 'Banana','Watermelon']
與用splice添加元素操作類似,在此操作中,我們將遞減或移動索引2之后的元素索引,所以復雜度是O(n)。
查找元素:
查找只是訪問數組的一個元素,我們可以通過使用方括號符號(例如: arr[4])來訪問數組的元素。
你認為這個操作的復雜性是什么?我們通過一個例子來演示一下:
let fruits = ['Apple', 'Orange', 'Pear']
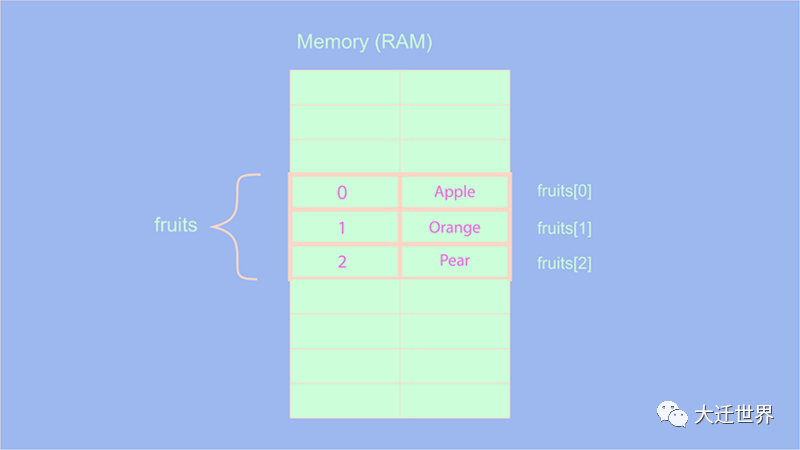
前面我們已經看到,數組的所有元素都按順序存儲,并且始終分組在一起。因此,如果執行fruits[1],它將告訴計算機找到名為fruits的數組并獲取第二個元素(數組從索引0開始)。
由于它們是按順序存儲的,因此計算機不必查看整個內存即可找到該元素,因為所有元素按順序分組在一起,因此它可以直接在fruits數組內部查看。因此,數組中的查找操作的復雜度為 O(1)。
我們已經完成了對數組的基本操作,我們先來小結一下什么時候可以使用數組:
當你要執行像push()(在末尾添加元素)和pop()(從末尾刪除元素)這樣的操作時,數組是合適的,因為這些操作的復雜度是O(1)。
除此之外,查找操作可以在數組中非常快地執行。
使用數組時,執行諸如在特定索引處或在開頭添加/刪除元素之類的操作可能會非常慢,因為它們的復雜度為O(n)。
對象
像數組一樣,對象也是最常用的數據結構之一。對象是一種哈希表,允許我們存儲鍵值對,而不是像在數組中看到的那樣將值存儲在編號索引處。
定義對象的最簡單方法是:
let obj1 = {}事例:
let student = { name: 'Vivek', age: 13, class: 8 }來看一下上面的對象是如何存儲在內存中的:
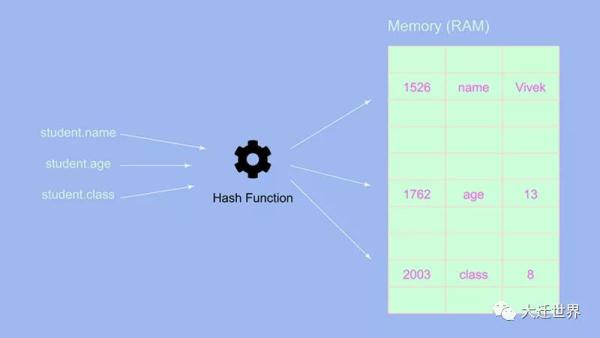
可以看到,對象的鍵-值對是隨機存儲的,不像數組中所有元素都存儲在一起。這也是數組與對象的主要區別,在對象中,鍵-值對隨機存儲在內存中。
我們還看到有一個哈希函數(hash function)。那么這個哈希函數做什么呢?哈希函數從對象中獲取每個鍵,并生成一個哈希值,然后將此哈希值轉換為地址空間,在該地址空間中存儲鍵值對。
例如,如果我們向學生對象添加以下鍵值對:
student.rollNumber = 322
rollNumber鍵通過哈希函數,然后轉換為存儲鍵和值的地址空間。現在我們已經對對象如何存儲在內存有了基本的了解,讓我們來執行一些操作。
添加
對于對象,我們沒有單獨的方法將元素添加到前面或后面,因為所有的鍵-值對都是隨機存儲的。只有一個操作是向對象添加一個新的鍵值對。
事例:
student.parentName = 'Narendra Singh Bisht'
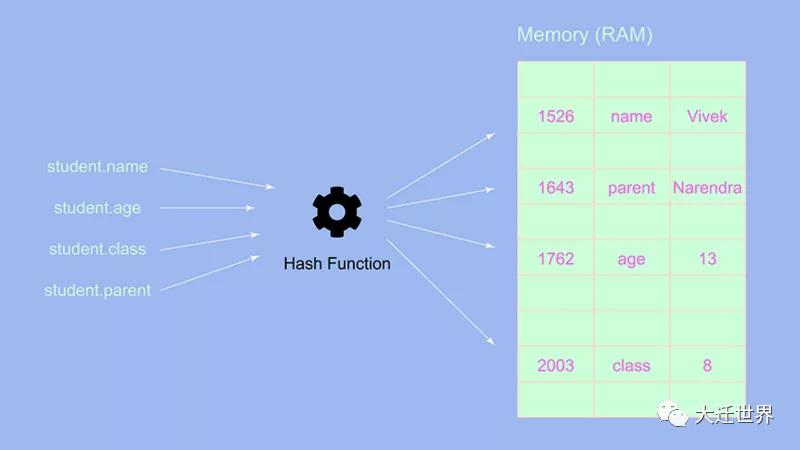
從上圖中我們可以得出結論,這個操作的復雜性總是O(1),因為我們不需要改變任何索引或操作對象本身,我們可以直接添加一個鍵-值對,它被存儲在一個隨機的地址空間。
刪除
與添加元素一樣,對象的刪除操作非常簡單,復雜度為O(1)。因為,我們不必在刪除時更改或操作對象。
delete student.parentName
查找
查找的復雜度O(1) ,因為在這里,我們也只是借助鍵來訪問值。訪問對象中的值的一種方法:
student.class
在對象中添加,刪除和查找的復雜度為O(1)???那么我們可以得出結論,我們應該每次都使用對象而不是數組嗎?答案是不。盡管對象很棒,但是在使用對象時需要考慮一些小的情況,就是哈希碰撞(Hash Collisions)。在使用對象時,并非始終應處理此情況,但了解該情況有助于我們更好地理解對象。
那么什么是哈希碰撞?
當我們定義一個對象時,我們的計算機會在內存中為該對象分配一些空間。我們需要記住,我們內存中的空間是有限的,因此有可能兩個或更多鍵值對可能具有相同的地址空間,這種情況稱為哈希碰撞。為了更好地理解它,我們看一個例子:
假設為下面的對象分配了5塊空間
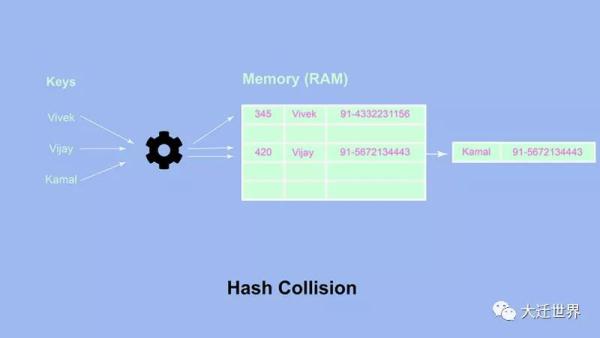
我們觀察到兩個鍵值對存儲在相同的地址空間中。怎么會這樣?當哈希函數返回一個哈希值,該哈希值轉換為多個鍵的相同地址空間時,就會發生這種情況。因此,多個 key 被映射到相同的地址空間。由于哈希碰撞,添加和訪問對象值的復雜度為O(n) ,因為要訪問特定值,我們可能必須遍歷各種鍵值對。
哈希碰撞并不是我們每次使用對象時都需要處理的東西。這只是一個特殊的情況,該情況也說明了對象不是完美的數據結構。
除了*哈希碰撞,使用對象時還必須注意另一種情況。JS 為我們提供了一個內置的keys()方法,用于遍歷對象的鍵。
我們可以將此方法應用于任何對象,例如:object1.keys()。keys()方法遍歷對象并返回所有鍵。盡管此方法看起來很簡單,但我們需要了解對象中的鍵值對是隨機存儲在內存中的,因此,遍歷對象的過程變得較慢,這與遍歷按順序將它們分組在一起的數組不同。
總結一下,當我們想執行諸如添加,刪除和訪問元素之類的操作時,可以使用對象,但是在使用對象時,我們需要謹慎地遍歷對象,因為這可能很耗時。除了進行遍歷外,我們還應該理解,有時由于哈希碰撞,訪問對象操作的復雜度可能會變為O(n)。
以上就是如何將JavaScript中數據結構的數組與對象進行比較,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





