溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中怎么處理大數據,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
import pandas as pd import collections df = pd.read_excel("D:/Download/chrome/sample-salesv3.xlsx") #print (df.head(10)) df["date"] = pd.to_datetime(df["date"]) # print (df.head(10)) df1 = df.set_index("date").resample("M")['ext price'].sum() # print(df1.head())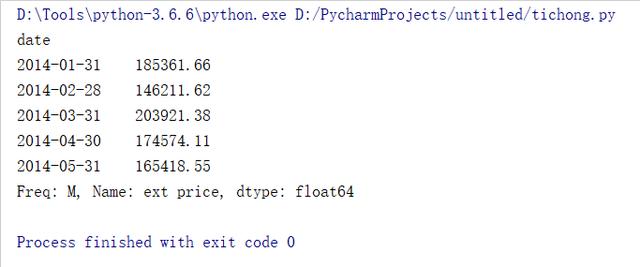
統計每個用戶每個月"ext price"這個屬性的sum值,利用Grouper
df2 = df.groupby(["name",pd.Grouper(key = "date",freq="M")])["ext price"] print(df2.head(10))

Agg
agg函數,它提供基于列的聚合操作。而groupby可以看做是基于行,或者說index的聚合操作。
從實現上看,groupby返回的是一個DataFrameGroupBy結構,這個結構必須調用聚合函數(如sum)之后,才會得到結構為Series的數據結果。
而agg是DataFrame的直接方法,返回的也是一個DataFrame。當然,很多功能用sum、mean等等也可以實現。但是agg更加簡潔, 而且傳給它的函數可以是字符串,也可以自定義,參數是column對應的子DataFrame
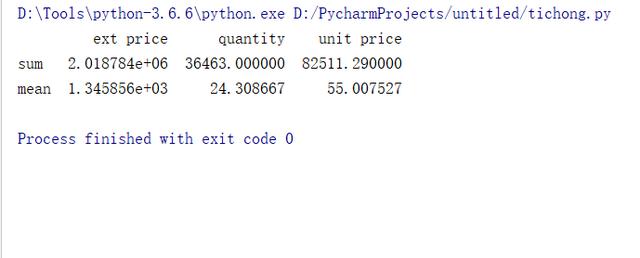
獲取"ext price","quantity","unit price"3列的各自的累計值和均值
df3 = df[["ext price","quantity","unit price"]].agg(["sum","mean"]) print(df3.head())
可以針對不同的列使用不同的聚合函數
df4 = df.agg({"ext price":["sum","mean"],"quantity":["sum","mean"],"unit price":["mean"]}) print(df4.head())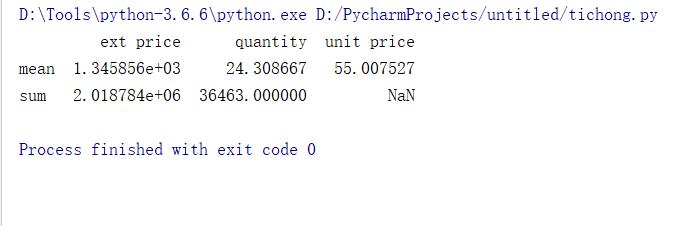
也可以自定義函數,比如,統計sku中,購買次數最多的產品編號,通過lambda表達式來做。
#統計sku中,購買次數最多的產品編號 get_max = lambda x:x.value_counts(dropna=False).index[0] get_max.__name__ = "most frequent" df5 = df.agg({"ext price":["sum","mean"], "quantity":["sum","mean"], "unit price":["mean"], "sku":[get_max] }) print(df5)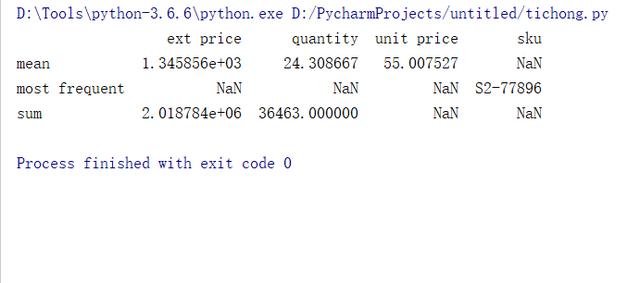
如果希望輸出的列按照某個順序排列,可以使用collections的OrderedDict
agg_dict = { "ext price":["sum","mean"], "quantity":["sum","mean"], "unit price":["mean"], "sku":[get_max] } #按照列名的長度排序。OrderedDict的順序是跟插入順序一致的 df6 = df.agg(collections.OrderedDict(sorted(agg_dict.items(),key=lambda x:len(x[0])))) print(df6)
上述內容就是Python中怎么處理大數據,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





