溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何理解系統經典模型Wide與Deep”,在日常操作中,相信很多人在如何理解系統經典模型Wide與Deep問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何理解系統經典模型Wide與Deep”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
摘要
在大規模特征的場景當中,我們通常(2016年之前)是使用將非線性特征應用在線性模型上的做法來實現的,使用這種方式,我們的輸入會是一個非常稀疏的向量。雖然我們要實現這樣的非線性特征,通過一些特征轉化以及特征交叉的方法是可以實現的,但是這會需要消耗大量的人力物力。
這個問題其實我們之前在介紹FM模型的時候也曾經提到過,對于FM模型來說,其實解決的也是同樣的問題。只是解決的方法不同,FM模型的方法是引入一個n x k的參數矩陣V來計算所有特征兩兩交叉的權重,來降低參數的數量以及提升預測和訓練的效率。而在本篇paper當中,討論的是使用神經網絡來解決這個問題。
解決問題的核心在于embedding,embedding直譯過來是嵌入,但是這樣并不容易理解。一般來說我們可以理解成某些特征的向量表示。比如Word2Vec當中,我們做的就是把一個單詞用一個向量來表示。這些向量就稱為word embedding。embedding有一個特點就是長度是固定的,但是值一般是通過神經網絡來學習得到的。
我們可以利用同樣訓練embedding的方式來在神經網絡當中訓練一些特征的embedding,這樣我們需要的特征工程的工作量就大大地減少。但是僅僅使用embedding也是不行的,在一些場景當中可能會引起過擬合,所以我們需要把線性特征以及稀疏特征結合起來,這樣就可以讓模型既不會陷入過擬合,又可以有足夠的能力可以學到更好的效果。
簡介
正如我們之前文章所分享的一樣,推薦系統也可以看成是搜索的排序系統。它的輸入是一個用戶信息以及用戶瀏覽的上下文信息,返回的結果是一個排好序的序列。
正因為如此,對于推薦系統來說,也會面臨一個和搜索排序系統一個類似的挑戰——記憶性和泛化性的權衡。記憶性可以簡單地理解成對商品或者是特征之間成對出現的一種學習,由于用戶的歷史行為特征是非常強的特征,記憶性因此可以帶來更好的效果。但是與之同時也會有問題產生,最典型的問題就是模型的泛化能力不夠。
對于泛化能力來說,它的主要來源是特征之間的相關性以及傳遞性。有可能特征A和B直接和label相關,也可能特征A與特征B相關,特征B與label相關,這種就稱為傳遞性。利用特征之間的傳遞性, 我們就可以探索一些歷史數據當中很少出現的特征組合,從而獲得很強的泛化能力。
在大規模的在線推薦以及排序系統當中,比如像是LR這樣的線性模型被廣泛應用,因為這些模型非常簡單、拓展性好、性能很強,并且可解釋性也很好。這些模型經常用one-hot這樣的二進制數據來訓練,舉個例子,比如如果用戶安裝了netflix,那么user_installed_app=netflix這個特征就是1,否則就是0。因此呢,一些二階特征的可解釋性就很強。
比如用戶如果還瀏覽過了Pandora,那么user_installed_app=netflix,impression_app=pandora這個聯合特征就是1,聯合特征的權重其實就是這兩者的相關性。但是這樣的特征需要大量的人工操作,并且由于樣本的稀疏性,對于一些沒有在訓練數據當中出現過的組合,模型就無法學習到它們的權重了。
但是這個問題可以被基于embedding的模型解決,比如之前介紹過的FM模型,或者是深度神經網絡。它可以通過訓練出低維度下的embedding,用embedding向量去計算得到交叉特征的權重。然而如果特征非常稀疏的話,我們也很難保證生成的embedding的效果。比如用戶的偏好比較明顯,或者是商品比較小眾,在這樣的情況下會使得大部分的query-item的pair對沒有行為,然而由embedding算出來的權重可能大于0,因此而導致過擬合,使得推薦結果不準。對于這種特殊的情況,線性模型的擬合、泛化能力反而更好。
在這篇paper當中,我們將會介紹Wide & Deep模型,它在一個模型當中兼容了記憶性以及泛化性。它可以同時訓練線性模型以及神經網絡兩個部分,從而達到更好的效果。
論文的主要內容有以下幾點:
Wide & Deep模型,包含前饋神經網絡embedding部分以及以及線性模型特征轉換,在廣義推薦系統當中的應用
Wide & Deep模型在Google Play場景下的實現與評估,Google Play是一個擁有超過10億日活和100w App的移動App商店
推薦系統概述
這是一張經典的推薦系統的架構圖:
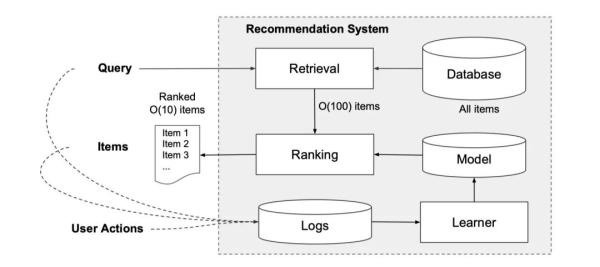
當用戶訪問app store的時候會生成一個請求,這個請求當中會包含用戶以及上下文的特征。推薦系統會返回一系列的app,這些app都是模型篩選出來用戶可能會點擊或者是購買的app。當用戶看到這些信息之后,會產生一些行為,比如瀏覽(沒有行為)、點擊、購買,產生行為之后,這些數據會被記錄在Logs當中,成為訓練數據。
我們看下上面部分,也就是從DataBase到Retrieval的部分。由于Database當中的數據量過大,足足有上百萬。所以我們想要在規定時間內(10毫秒)給所有的app都調用模型打一個分,然后進行排序是不可能的。所以我們需要對請求進行Retrieval,也就是召回。Retrieval系統會對用戶的請求進行召回,召回的方法有很多,可以利用機器學習模型,也可以進行規則。一般來說都是先基于規則快速篩選,再進行機器學習模型過濾。
進行篩選和檢索結束之后,最后再調用Wide & Deep模型進行CTR預估,根據預測出來的CTR對這些APP進行排序。在這篇paper當中我們同樣忽略其他技術細節,只關注與Wide & Deep模型的實現。
Wide & Deep原理
首先我們來看下業內的常用的模型的結構圖:
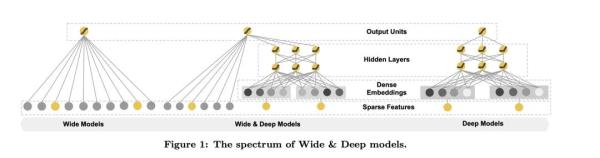
這張圖源于論文,從左到右分別展示了Wide模型,Wide & Deep模型以及Deep模型。從圖上我們也看得出來所謂的Wide模型呢其實就是線性模型,Deep模型是深度神經網絡模型。下面結合這張圖對這兩個部分做一個詳細一點的介紹。
Wide部分
Wide部分其實就是一個泛化的形如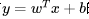 的線性模型,就如上圖左邊部分所展示的一樣。y是我們要預測的結果,x是特征,它是一個d維的向量
的線性模型,就如上圖左邊部分所展示的一樣。y是我們要預測的結果,x是特征,它是一個d維的向量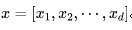 。這里的d是特征的數量。同樣w也是一個d維的權重向量
。這里的d是特征的數量。同樣w也是一個d維的權重向量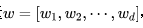 ,b呢則是偏移量。這些我們在之前線性回歸的模型當中曾經都介紹過,大家應該也都不陌生。
,b呢則是偏移量。這些我們在之前線性回歸的模型當中曾經都介紹過,大家應該也都不陌生。
特征包含兩個部分,一種是原始數據直接拿過來的數據,另外一種是我們經過特征轉化之后得到的特征。最重要的一種特征轉化方式就是交叉組合,交叉組合可以定義成如下形式:
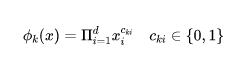
這里的是一個bool型的變量,表示的是第i個特征的第k種轉化函數的結果。由于使用的是乘積的形式,只有所有項都為真,最終的結果才是1,否則是0。比如"AND(gender=female,language=en)"這就是一個交叉特征,只有當用戶的性別為女,并且使用的語言為英文同時成立,這個特征的結果才會是1。通過這種方式我們可以捕捉到特征之間的交互,以及為線性模型加入非線性的特征。
Deep部分
Deep部分是一個前饋神經網絡,也就是上圖當中的右側部分。
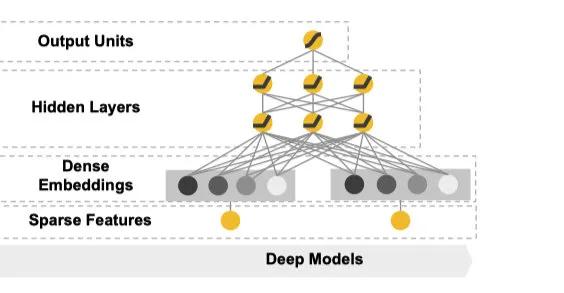
我們觀察一下這張圖會發現很多細節,比如它的輸入是一個sparse的feature,可以簡單理解成multihot的數組。這個輸入會在神經網絡的第一層轉化成一個低維度的embedding,然后神經網絡訓練的是這個embedding。這個模塊主要是被設計用來處理一些類別特征,比如說item的類目,用戶的性別等等。
和傳統意義上的one-hot方法相比,embedding的方式用一個向量來表示一個離散型的變量,它的表達能力更強,并且這個向量的值是讓模型自己學習的,因此泛化能力也大大提升。這也是深度神經網絡當中常見的做法。
Wide & Deep合并
Wide部分和Deep部分都有了之后,通過加權的方式合并在一起。這也就是上圖當中的中間部分。
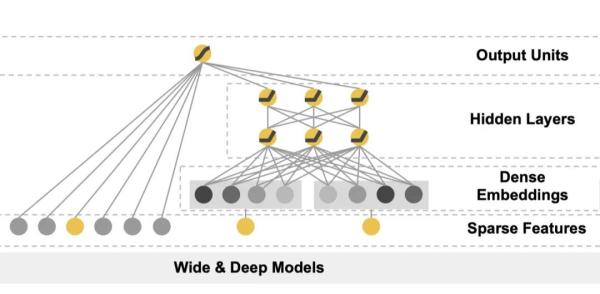
最上層輸出之前其實是一個sigmoid層或者是一個linear層,就是一個簡單的線性累加。英文叫做joint,paper當中還列舉了joint和ensemble的區別,對于ensemble模型來說,它的每一個部分是獨立訓練的。而joint模型當中的不同部分是聯合訓練的。ensemble模型當中的每一個部分的參數是互不影響的,但是對于joint模型而言,它當中的參數是同時訓練的。
這樣帶來的結果是,由于訓練對于每個部分是分開的,所以每一個子模型的參數空間都很大,這樣才能獲得比較好的效果。而joint訓練的方式則沒有這個問題,我們把線性部分和深度學習的部分分開,可以互補它們之間的缺陷,從而達到更好的效果,并且也不用人為地擴大訓練參數的數量。
系統實現
app推薦的數據流包含了三個部分:數據生產、模型訓練以及模型服務。用一張圖來展示大概是這樣的:
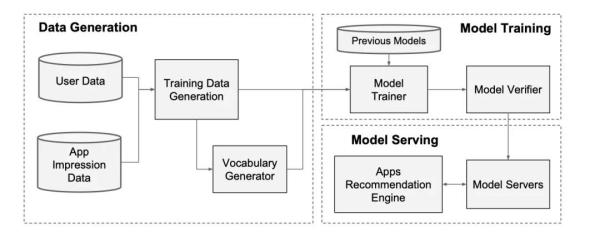
數據生產
在數據生產的階段,我們使用app在用戶面前曝光一段時間作為一個樣本,如果這個app被用戶點擊安裝,那么這個樣本被標記為1,否則標記為0。這也是絕大多數推薦場景下的做法。
在這個階段,系統會去查表,把一些字符串類別的特征轉化成int型的id。比如娛樂類的對應1,攝影類的對應2,比如收費的對應0,免費的對應1等等。同時會把數字類型的特征做標準化處理,縮放到[0, 1]的范圍內。
模型訓練
paper當中提供了一張模型的結構圖:
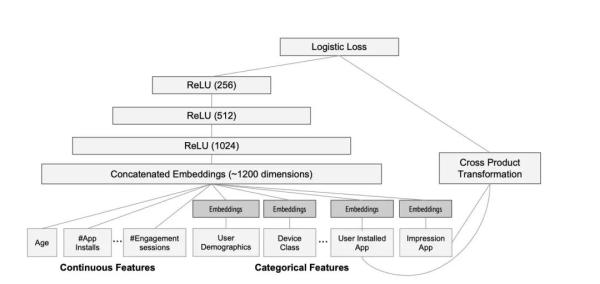
從上圖當中我們可以看到,左邊是一些連續性的特征,比如年齡,安裝的app數量等等,右邊是一些離散型的特征,比如設備信息,安裝過的app等等。這些離散型的特征都會被轉化成embedding,之后和右邊的連續性特征一起進入神經網絡進行學習。paper當中使用的是32維的embedding。
模型每次訓練會使用超過500 billion的樣本數量進行訓練,每次搜集到了新的訓練數據都會訓練模型。但是如果每一次訓練我們都從頭開始的話,顯然會非常緩慢,并且會浪費大量的計算資源。因此paper當中選擇了一種增量更新的模式,也就是說在模型更新的時候,會加載舊模型的參數,再使用最新的數據進行更新訓練。在新模型更新上線之前,會先驗證模型的效果,確認效果沒有問題之后再進行更新。
模型服務
當模型被訓練好被加載進來之后,對于每一個請求,服務器都會從recall系統當中獲取一系列候選的app,以及用戶的特征。接著調用模型對每一個app進行打分,獲取了分數之后,服務器會對候選的app按照分數從高到低進行排序。
為了保證服務器的響應能力,能夠在10ms時間內返回結果,paper采取了多線程并發執行的方法。老實講,我覺得這份數據有點虛。因為現在的模型沒有不使用并發執行的,但即使是并發執行,使用深度學習進行預測也很難保證效率能夠到達這種程度。也許是還采用了其他的一些優化,但是paper里沒有全寫出來。
模型結果
為了驗證Wide & Deep模型的效果,paper在真實的場景當中從兩個角度進行了大量的測試。包括app的獲取量以及服務的表現。
App 獲取量
在線上環境進行了為期3周的A/B測試,1個桶作為對照桶,使用之前版本的線性模型。1個桶使用Wide & Deep模型,另外一個桶只使用Deep模型,去除了linear的部分。這三個桶各自占據了1%的流量,最后得到的結果如下:

Wide & Deep模型不僅AUC更高,并且線上APP的獲取量也提升了3.9%。
服務性能
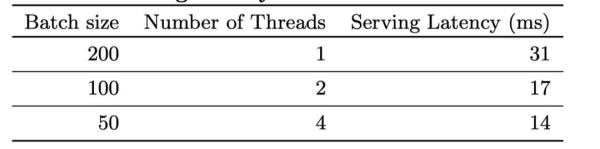
對于推薦系統來說,服務端的性能一直是一個很大的問題,因為既需要承載大量的流量,也需要保證延遲非常短。而使用機器學習或者是深度學習模型來進行CTR的預測,本身的復雜度是非常高的。根據paper當中的說法,高峰時期,他們的服務器會承載1千萬的qps。
如果使用單線程來處理一個batch的數據需要31毫秒,為了提升速度,他們開發了多線程打分的機制,并且將一個batch拆分成了幾個部分進行并發計算。通過這樣的方式,將客戶端的延遲降低到了14毫秒。
代碼實現
光說不練假把式,Wide & Deep在推薦領域一度表現不俗,并且模型的實現也不復雜。我曾經使用Pytorch實現過一個簡易版本,貼出來拋磚引玉給大家做一個參考。
import torch from torch import nn class WideAndDeep(nn.Module): def __init__(self, dense_dim=13, site_category_dim=24, app_category_dim=32): super(WideAndDeep, self).__init__() # 線性部分 self.logistic = nn.Linear(19, 1, bias=True) # embedding部分 self.site_emb = nn.Embedding(site_category_dim, 6) self.app_emb = nn.Embedding(app_category_dim, 6) # 融合部分 self.fusion_layer = nn.Linear(12, 6) def forward(self, x): site = self.site_emb(x[:, -2].long()) app = self.app_emb(x[:, -1].long()) emb = self.fusion_layer(torch.cat((site, app), dim=1)) return torch.sigmoid(self.logistic(torch.cat((emb, x[:, :-2]), dim=1)))
由于我當時的應用場景比較簡單,所以網絡結構只有三層,但是原理是一樣的,如果要應用在復雜的場景當中,只需要增加特征以及網絡層次即可。
到此,關于“如何理解系統經典模型Wide與Deep”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





