溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“LRU緩存算法的實現方法是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“LRU緩存算法的實現方法是什么”吧!
LRU就是Least Recently Used,即最近最少使用,是一種常用的頁面置換算法,將最近長時間未使用的頁面淘汰,其實也很簡單,就是要將不受歡迎的頁面及時淘汰,不讓它占著茅坑不拉shit,浪費資源。
LRU是一種常見的頁面置換算法,在計算中,所有的文件操作都要放在內存中進行,然而計算機內存大小是固定的,所以我們不可能把所有的文件都加載到內存,因此我們需要制定一種策略對加入到內存中的文件進項選擇。
常見的頁面置換算法有如下幾種:
LRU 最近最久未使用
FIFO 先進先出置換算法 類似隊列
OPT 最佳置換算法 (理想中存在的)
NRU Clock置換算法
LFU 最少使用置換算法
PBA 頁面緩沖算法
LRU原理
LRU的設計原理就是,當數據在最近一段時間經常被訪問,那么它在以后也會經常被訪問。這就意味著,如果經常訪問的數據,我們需要然其能夠快速命中,而不常訪問的數據,我們在容量超出限制內,要將其淘汰。
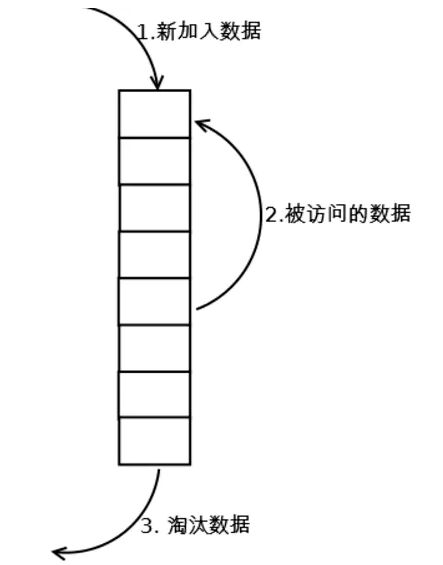
其核心就是利用棧,進行操作,其中主要有兩項操作,get和put
get
get時,若棧中有值則將該值的key提到棧頂,沒有時則返回null
put
棧未滿時,若棧中有要put的key,則更新此key對應的value,并將該鍵值提到棧頂,若無要put的key,直接入棧
棧滿時,若棧中有要put的key,則更新此key對應的value,并將該鍵值提到棧頂;若棧中沒有put的key 時,去掉棧底元素,將put的值入到棧頂
解法:維護一個數組,提供 get 和 put 方法,并且限定 max 數量。
使用時,get 可以標記某個元素是最新使用的,提升它去第一項。put 可以加入某個key-value,但需要判斷是否已經到最大限制 max
若未到能直接往數組第一項里插入 若到了最大限制 max,則需要淘汰數據尾端一個元素。
LRUCache cache = new LRUCache( 2 /* 緩存容量 */ ); cache.put(1, 1); cache.put(2, 2); cache.get(1); // 返回 1 cache.put(3, 3); // 該操作會使得密鑰 2 作廢 cache.get(2); // 返回 -1 (未找到) cache.put(4, 4); // 該操作會使得密鑰 1 作廢 cache.get(1); // 返回 -1 (未找到) cache.get(3); // 返回 3 cache.get(4); // 返回 4
LRU 算法設計
分析上面的操作過程,要讓 put 和 get 方法的時間復雜度為 O(1),我們可以總結出 cache 這個數據結構必要的條件:查找快,插入快,刪除快,有順序之分。
因為顯然 cache 必須有順序之分,以區分最近使用的和久未使用的數據;而且我們要在 cache 中查找鍵是否已存在;如果容量滿了要刪除最后一個數據;每次訪問還要把數據插入到隊頭。
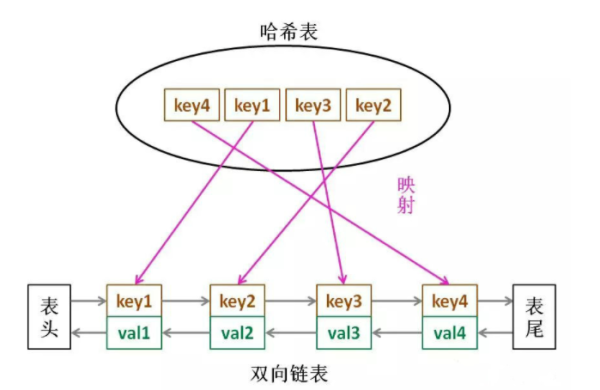
那么,什么數據結構同時符合上述條件呢?哈希表查找快,但是數據無固定順序;鏈表有順序之分,插入刪除快,但是查找慢。所以結合一下,形成一種新的數據結構:哈希鏈表。
LRU 緩存算法的核心數據結構就是哈希鏈表,雙向鏈表和哈希表的結合體。這個數據結構長這樣:
js 實現
具體代碼 一般的解法,通過維護一個數組,數組項存放了 key-value 鍵值對對象,每次需要遍歷去尋找 key 值所在的數組下標操作。
已經通過 leetCode 146 的檢測。執行用時 : 720 ms。內存消耗 : 58.5 MB。
function LRUCache(capacity) { this.capacity = capacity; // 最大限制 this.cache = []; }; /** * @param {number} key * @return {number} */ LRUCache.prototype.get = function (key) { let index = this.cache.findIndex((item) => item.key === key); if (index === -1) { return -1; } // 刪除此元素后插入到數組第一項 let value = this.cache[index].value; this.cache.splice(index, 1); this.cache.unshift({ key, value, }); return value; }; /** * @param {number} key * @param {number} value * @return {void} */ LRUCache.prototype.put = function (key, value) { let index = this.cache.findIndex((item) => item.key === key); // 想要插入的數據已經存在了,那么直接提升它就可以 if (index > -1) { this.cache.splice(index, 1); } else if (this.cache.length >= this.capacity) { // 若已經到達最大限制,先淘汰一個最久沒有使用的 this.cache.pop(); } this.cache.unshift({ key, value }); };上面的做法其實有變種,可以通過一個對象來存鍵值對,一個數組來存放鍵的順序。
進階要求O(1)
時間復雜度 O(1),那就不能數組遍歷去查找 key 值。可以用 ES6 的 Map 來解了,因為 Map 既能保持鍵值對,還能記住插入順序。
function LRUCache(capacity) { this.cache = new Map(); this.capacity = capacity; // 最大限制 }; LRUCache.prototype.get = function (key) { if (this.cache.has(key)) { // 存在即更新 let temp = this.cache.get(key); this.cache.delete(key); this.cache.set(key, temp); return temp; } return -1; }; LRUCache.prototype.put = function (key, value) { if (this.cache.has(key)) { // 存在即更新(刪除后加入) this.cache.delete(key); } else if (this.cache.size >= this.capacity) { // 不存在即加入 // 緩存超過最大值,則移除最近沒有使用的 this.cache.delete(this.cache.keys().next().value); } this.cache.set(key, value); };感謝各位的閱讀,以上就是“LRU緩存算法的實現方法是什么”的內容了,經過本文的學習后,相信大家對LRU緩存算法的實現方法是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





