溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“程序員必知必會的排序算法有哪些”,在日常操作中,相信很多人在程序員必知必會的排序算法有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”程序員必知必會的排序算法有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
身為程序員,十大排序是是所有合格程序員所必備和掌握的,并且熱門的算法比如快排、歸并排序還可能問的比較細致,對算法性能和復雜度的掌握有要求。bigsai作為一個負責任的Java和數據結構與算法方向的小博主,在這方面肯定不能讓讀者們有所漏洞。跟著本篇走,帶你捋一捋常見的十大排序算法,輕輕松松掌握!
首先對于排序來說大多數人對排序的概念停留在冒泡排序或者JDK中的Arrays.sort(),手寫各種排序對很多人來說都是一種奢望,更別說十大排序算法了,不過還好你遇到了本篇文章!
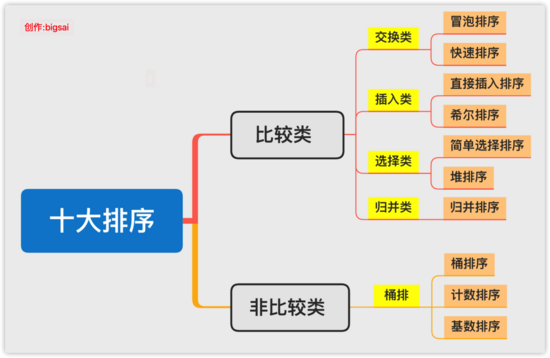
對于排序的分類,主要不同的維度比如復雜度來分、內外部、比較非比較等維度來分類。我們正常講的十大排序算法是內部排序,我們更多將他們分為兩大類:基于 「比較和非比較」 這個維度去分排序種類。
「非比較類的有桶排序、基數排序、計數排序」。也有很多人將排序歸納為8大排序,那就是因為基數排序、計數排序是建立在桶排序之上或者是一種特殊的桶排序,但是基數排序和計數排序有它特有的特征,所以在這里就將他們歸納為10種經典排序算法。而比較類排序也可分為
比較類排序也有更細致的分法,有基于交換的、基于插入的、基于選擇的、基于歸并的,更細致的可以看下面的腦圖。
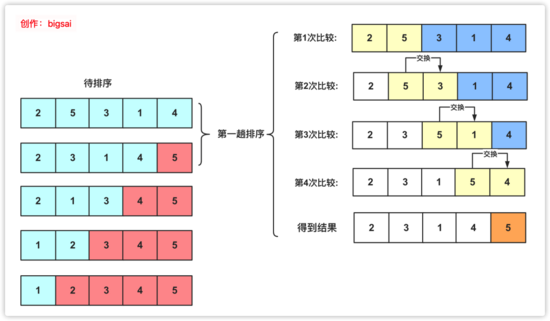
冒泡排序,又稱起泡排序,它是一種基于交換的排序典型,也是快排思想的基礎,冒泡排序是一種穩定排序算法,時間復雜度為O(n^2).基本思想是: 「循環遍歷多次每次從前往后把大元素往后調,每次確定一個最大(最小)元素,多次后達到排序序列。」 (或者從后向前把小元素往前調)。
具體思想為(把大元素往后調):
從第一個元素開始往后遍歷,每到一個位置判斷是否比后面的元素大,如果比后面元素大,那么就交換兩者大小,然后繼續向后,這樣的話進行一輪之后就可以保證 「最大的那個數被交換交換到最末的位置可以確定」 。
第二次同樣從開始起向后判斷著前進,如果當前位置比后面一個位置更大的那么就和他后面的那個數交換。但是有點注意的是,這次并不需要判斷到最后,只需要判斷到倒數第二個位置就行(因為第一次我們已經確定最大的在倒數第一,這次的目的是確定倒數第二)
同理,后面的遍歷長度每次減一,直到第一個元素使得整個元素有序。
例如 2 5 3 1 4 排序過程如下:
實現代碼為:
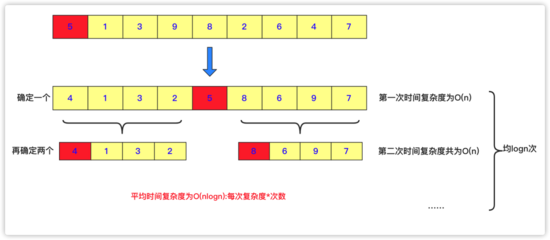
public void maopaosort(int[] a) { // TODO Auto-generated method stub for(int i=a.length-1;i>=0;i--) { for(int j=0;j<i;j++) { if(a[j]>a[j+1]) { int team=a[j]; a[j]=a[j+1]; a[j+1]=team; } } } }快速排序是對冒泡排序的一種改進,采用遞歸分治的方法進行求解。而快排相比冒泡是一種不穩定排序,時間復雜度最壞是O(n^2),平均時間復雜度為O(nlogn),最好情況的時間復雜度為O(nlogn)。
對于快排來說, 「基本思想」 是這樣的
快排需要將序列變成兩個部分,就是 「序列左邊全部小于一個數」 , 「序列右面全部大于一個數」 ,然后利用遞歸的思想再將左序列當成一個完整的序列再進行排序,同樣把序列的右側也當成一個完整的序列進行排序。
其中這個數在這個序列中是可以隨機取的,可以取最左邊,可以取最右邊,當然也可以取隨機數。但是 「通常」 不優化情況我們取最左邊的那個數。
實現代碼為:
public void quicksort(int [] a,int left,int right) { int low=left; int high=right; //下面兩句的順序一定不能混,否則會產生數組越界!!!very important!!! if(low>high)//作為判斷是否截止條件 return; int k=a[low];//額外空間k,取最左側的一個作為衡量,最后要求左側都比它小,右側都比它大。 while(low<high)//這一輪要求把左側小于a[low],右側大于a[low]。 { while(low<high&&a[high]>=k)//右側找到第一個小于k的停止 { high--; } //這樣就找到第一個比它小的了 a[low]=a[high];//放到low位置 while(low<high&&a[low]<=k)//在low往右找到第一個大于k的,放到右側a[high]位置 { low++; } a[high]=a[low]; } a[low]=k;//賦值然后左右遞歸分治求之 quicksort(a, left, low-1); quicksort(a, low+1, right); }直接插入排序在所有排序算法中的是最簡單排序方式之一。和我們上學時候 從前往后、按高矮順序排序,那么一堆高低無序的人群中,從第一個開始,如果前面有比自己高的,就直接插入到合適的位置。 「一直到隊伍的最后一個完成插入」 整個隊列才能滿足有序。
直接插入排序遍歷比較時間復雜度是每次O(n),交換的時間復雜度每次也是O(n),那么n次總共的時間復雜度就是O(n^2)。有人會問折半(二分)插入能否優化成O(nlogn),答案是不能的。因為二分只能減少查找復雜度每次為O(logn),而插入的時間復雜度每次為O(n)級別,這樣總的時間復雜度級別還是O(n^2).
插入排序的具體步驟:
選取當前位置(當前位置前面已經有序) 目標就是將當前位置數據插入到前面合適位置。
向前枚舉或者二分查找,找到待插入的位置。
移動數組,賦值交換,達到插入效果。
實現代碼為:
public void insertsort (int a[]) { int team=0; for(int i=1;i<a.length;i++) { System.out.println(Arrays.toString(a)); team=a[i]; for(int j=i-1;j>=0;j--) { if(a[j]>team) { a[j+1]=a[j]; a[j]=team; } else { break; } } } }直接插入排序因為是O(n^2),在數據量很大或者數據移動位次太多會導致效率太低。很多排序都會想辦法拆分序列,然后組合,希爾排序就是以一種特殊的方式進行預處理,考慮到了 「數據量和有序性」 兩個方面緯度來設計算法。使得序列前后之間小的盡量在前面,大的盡量在后面,進行若干次的分組別計算,最后一組即是一趟完整的直接插入排序。
對于一個 長串 ,希爾首先將序列分割(非線性分割)而是 「按照某個數模」 ( 取余 這個類似報數1、2、3、4。1、2、3、4)這樣形式上在一組的分割先 「各組分別進行直接插入排序」 ,這樣 「很小的數在后面」 可以通過 「較少的次數移動到相對靠前」 的位置。然后慢慢合并變長,再稍稍移動。
因為每次這樣插入都會使得序列變得更加有序,稍微有序序列執行直接插入排序成本并不高。所以這樣能夠在合并到最終的時候基本小的在前,大的在后,代價越來越小。這樣希爾排序相比插入排序還是能節省不少時間的。
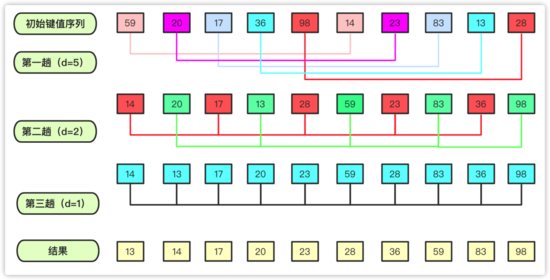
實現代碼為:
public void shellsort (int a[]) { int d=a.length; int team=0;//臨時變量 for(;d>=1;d/=2)//共分成d組 for(int i=d;i<a.length;i++)//到那個元素就看這個元素在的那個組即可 { team=a[i]; for(int j=i-d;j>=0;j-=d) { if(a[j]>team) { a[j+d]=a[j]; a[j]=team; } else { break; } } } }簡單選擇排序(Selection sort)是一種簡單直觀的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小(大)元素,然后放到 「已排序序列的末尾」 。以此類推,直到所有元素均排序完畢。

實現代碼為:
public void selectSort(int[] arr) { for (int i = 0; i < arr.length - 1; i++) { int min = i; // 最小位置 for (int j = i + 1; j < arr.length; j++) { if (arr[j] < arr[min]) { min = j; // 更換最小位置 } } if (min != i) { swap(arr, i, min); // 與第i個位置進行交換 } } } private void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; }對于堆排序,首先是建立在堆的基礎上,堆是一棵完全二叉樹,還要先認識下大根堆和小根堆,完全二叉樹中所有節點均大于(或小于)它的孩子節點,所以這里就分為兩種情況
如果所有節點 「大于」 孩子節點值,那么這個堆叫做 「大根堆」 ,堆的最大值在根節點。
如果所有節點 「小于」 孩子節點值,那么這個堆叫做 「小根堆」 ,堆的最小值在根節點。
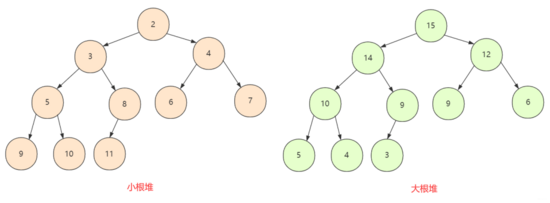
堆排序首先就是 「建堆」 ,然后再是調整。對于二叉樹(數組表示),我們從下往上進行調整,從 「第一個非葉子節點」 開始向前調整,對于調整的規則如下:
建堆是一個O(n)的時間復雜度過程,建堆完成后就需要進行刪除頭排序。給定數組建堆(creatHeap)
①從第一個非葉子節點開始判斷交換下移(shiftDown),使得當前節點和子孩子能夠保持堆的性質
②但是普通節點替換可能沒問題,對如果交換打破子孩子堆結構性質,那么就要重新下移(shiftDown)被交換的節點一直到停止。
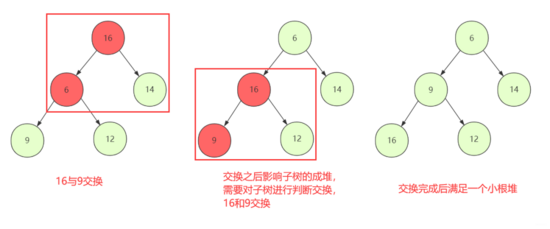
堆構造完成,取第一個堆頂元素為最小(最大),剩下左右孩子依然滿足堆的性值,但是缺個堆頂元素,如果給孩子調上來,可能會調動太多并且可能破壞堆結構。
①所以索性把最后一個元素放到第一位。這樣只需要判斷交換下移(shiftDown),不過需要注意此時整個堆的大小已經發生了變化,我們在邏輯上不會使用被拋棄的位置,所以在設計函數的時候需要附帶一個堆大小的參數。
②重復以上操作,一直堆中所有元素都被取得停止。
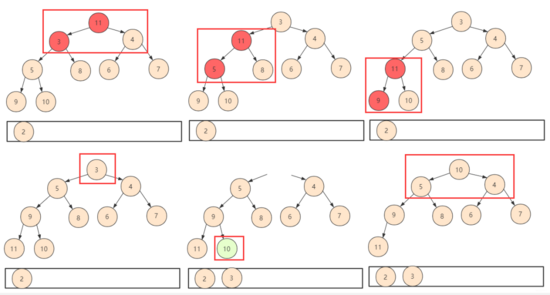
而堆算法復雜度的分析上,之前建堆時間復雜度是O(n)。而每次刪除堆頂然后需要向下交換,每個個數最壞為logn個。這樣復雜度就為O(nlogn).總的時間復雜度為O(n)+O(nlogn)=O(nlogn).
實現代碼為:
static void swap(int arr[],int m,int n) { int team=arr[m]; arr[m]=arr[n]; arr[n]=team; } //下移交換 把當前節點有效變換成一個堆(小根) static void shiftDown(int arr[],int index,int len)//0 號位置不用 { int leftchild=index*2+1;//左孩子 int rightchild=index*2+2;//右孩子 if(leftchild>=len) return; else if(rightchild<len&&arr[rightchild]<arr[index]&&arr[rightchild]<arr[leftchild])//右孩子在范圍內并且應該交換 { swap(arr, index, rightchild);//交換節點值 shiftDown(arr, rightchild, len);//可能會對孩子節點的堆有影響,向下重構 } else if(arr[leftchild]<arr[index])//交換左孩子 { swap(arr, index, leftchild); shiftDown(arr, leftchild, len); } } //將數組創建成堆 static void creatHeap(int arr[]) { for(int i=arr.length/2;i>=0;i--) { shiftDown(arr, i,arr.length); } } static void heapSort(int arr[]) { System.out.println("原始數組為 :"+Arrays.toString(arr)); int val[]=new int[arr.length]; //臨時儲存結果 //step1建堆 creatHeap(arr); System.out.println("建堆后的序列為 :"+Arrays.toString(arr)); //step2 進行n次取值建堆,每次取堆頂元素放到val數組中,最終結果即為一個遞增排序的序列 for(int i=0;i<arr.length;i++) { val[i]=arr[0];//將堆頂放入結果中 arr[0]=arr[arr.length-1-i];//刪除堆頂元素,將末尾元素放到堆頂 shiftDown(arr, 0, arr.length-i);//將這個堆調整為合法的小根堆,注意(邏輯上的)長度有變化 } //數值克隆復制 for(int i=0;i<arr.length;i++) { arr[i]=val[i]; } System.out.println("堆排序后的序列為:"+Arrays.toString(arr)); }在歸并類排序一般只講歸并排序,但是歸并排序也分二路歸并、多路歸并,這里就講較多的二路歸并排序,且用遞歸方式實現。
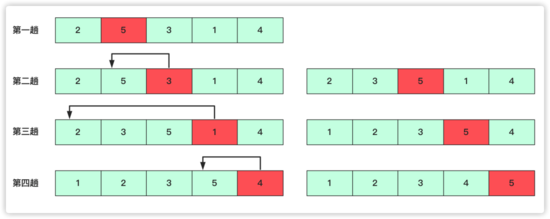
歸并和快排都是 「基于分治算法」 的,分治算法其實應用挺多的,很多分治會用到遞歸,但事實上 「分治和遞歸是兩把事」 。分治就是分而治之,可以采用遞歸實現,也可以自己遍歷實現非遞歸方式。而歸并排序就是先將問題分解成代價較小的子問題,子問題再采取代價較小的合并方式完成一個排序。
至于歸并的思想是這樣的:
第一次:整串先進行劃分成一個一個單獨,第一次是將序列中( 1 2 3 4 5 6--- )兩兩歸并成有序,歸并完( xx xx xx xx---- )這樣局部有序的序列。
第二次就是兩兩歸并成若干四個( 1 2 3 4 5 6 7 8 ---- ) 「每個小局部是有序的」 。
就這樣一直到最后這個串串只剩一個,然而這個耗費的總次數logn。每次操作的時間復雜的又是 O(n) 。所以總共的時間復雜度為 O(nlogn) .
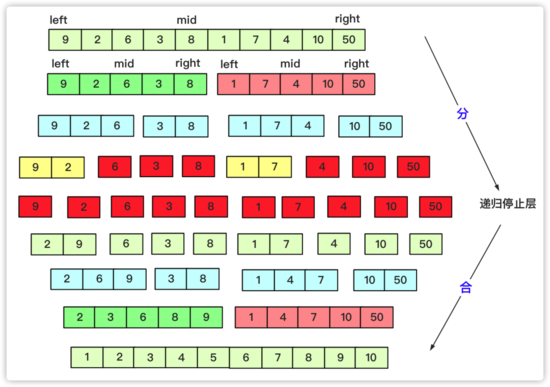
合并為一個O(n)的過程:
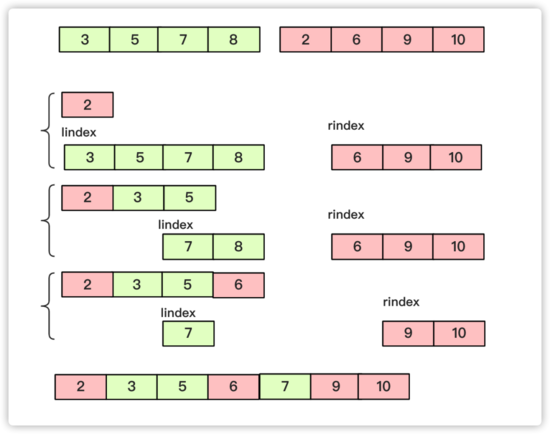
實現代碼為:
private static void mergesort(int[] array, int left, int right) { int mid=(left+right)/2; if(left<right) { mergesort(array, left, mid); mergesort(array, mid+1, right); merge(array, left,mid, right); } } private static void merge(int[] array, int l, int mid, int r) { int lindex=l;int rindex=mid+1; int team[]=new int[r-l+1]; int teamindex=0; while (lindex<=mid&&rindex<=r) {//先左右比較合并 if(array[lindex]<=array[rindex]) { team[teamindex++]=array[lindex++]; } else { team[teamindex++]=array[rindex++]; } } while(lindex<=mid)//當一個越界后剩余按序列添加即可 { team[teamindex++]=array[lindex++]; } while(rindex<=r) { team[teamindex++]=array[rindex++]; } for(int i=0;i<teamindex;i++) { array[l+i]=team[i]; } }桶排序是一種用空間換取時間的排序,桶排序重要的是它的思想,而不是具體實現,時間復雜度最好可能是線性O(n),桶排序不是基于比較的排序而是一種分配式的。桶排序從字面的意思上看:
桶:若干個桶,說明此類排序將數據放入若干個桶中。
桶:每個桶有容量,桶是有一定容積的容器,所以每個桶中可能有多個元素。
桶:從整體來看,整個排序更希望桶能夠更勻稱,即既不溢出(太多)又不太少。
桶排序的思想為: 「將待排序的序列分到若干個桶中,每個桶內的元素再進行個別排序。」 當然桶排序選擇的方案跟具體的數據有關系,桶排序是一個比較廣泛的概念,并且計數排序是一種特殊的桶排序,基數排序也是建立在桶排序的基礎上。在數據分布均勻且每個桶元素趨近一個時間復雜度能達到O(n),但是如果數據范圍較大且相對集中就不太適合使用桶排序。
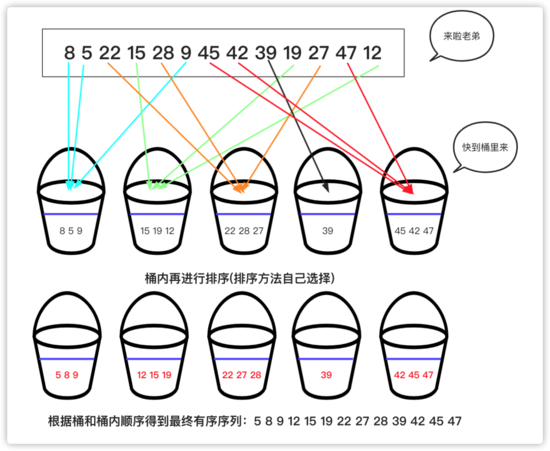
實現一個簡單桶排序:
import java.util.ArrayList; import java.util.List; //微信公眾號:bigsai public class bucketSort { public static void main(String[] args) { int a[]= {1,8,7,44,42,46,38,34,33,17,15,16,27,28,24}; List[] buckets=new ArrayList[5]; for(int i=0;i<buckets.length;i++)//初始化 { buckets[i]=new ArrayList<Integer>(); } for(int i=0;i<a.length;i++)//將待排序序列放入對應桶中 { int index=a[i]/10;//對應的桶號 buckets[index].add(a[i]); } for(int i=0;i<buckets.length;i++)//每個桶內進行排序(使用系統自帶快排) { buckets[i].sort(null); for(int j=0;j<buckets[i].size();j++)//順便打印輸出 { System.out.print(buckets[i].get(j)+" "); } } } }計數排序是一種特殊的桶排序,每個桶的大小為1,每個桶不在用List表示,而通常用一個值用來計數。
在 「設計具體算法的時候」 ,先找到最小值min,再找最大值max。然后創建這個區間大小的數組,從min的位置開始計數,這樣就可以最大程度的壓縮空間,提高空間的使用效率。
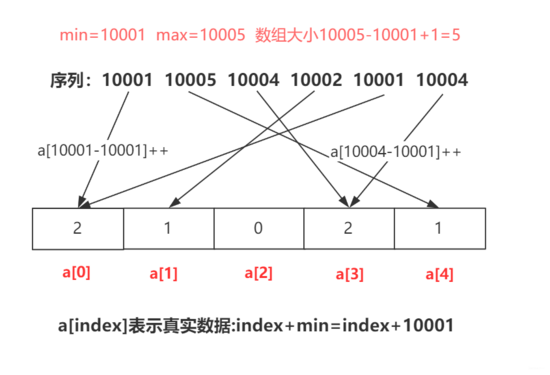
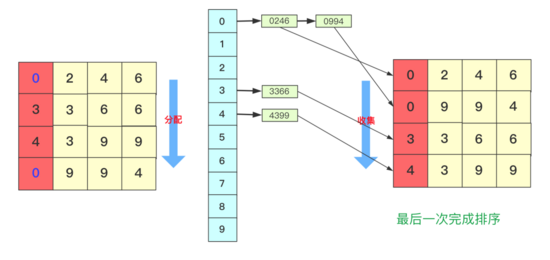
public static void countSort(int a[]) { int min=Integer.MAX_VALUE;int max=Integer.MIN_VALUE; for(int i=0;i<a.length;i++)//找到max和min { if(a[i]<min) min=a[i]; if(a[i]>max) max=a[i]; } int count[]=new int[max-min+1];//對元素進行計數 for(int i=0;i<a.length;i++) { count[a[i]-min]++; } //排序取值 int index=0; for(int i=0;i<count.length;i++) { while (count[i]-->0) { a[index++]=i+min;//有min才是真正值 } } }基數排序是一種很容易理解但是比較難實現(優化)的算法。基數排序也稱為卡片排序,基數排序的原理就是多次利用計數排序(計數排序是一種特殊的桶排序),但是和前面的普通桶排序和計數排序有所區別的是, 「基數排序并不是將一個整體分配到一個桶中」 ,而是將自身拆分成一個個組成的元素,每個元素分別順序分配放入桶中、順序收集,當從前往后或者從后往前每個位置都進行過這樣順序的分配、收集后,就獲得了一個有序的數列。
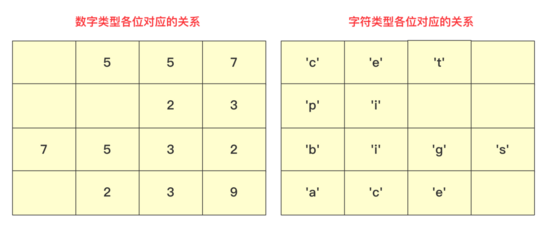
如果是數字類型排序,那么這個桶只需要裝0-9大小的數字,但是如果是字符類型,那么就需要注意ASCII的范圍。
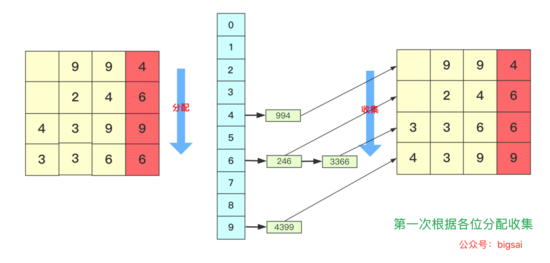
所以遇到這種情況我們基數排序思想很簡單,就拿 934,241,3366,4399這幾個數字進行基數排序的一趟過程來看,第一次會根據各位進行分配、收集:
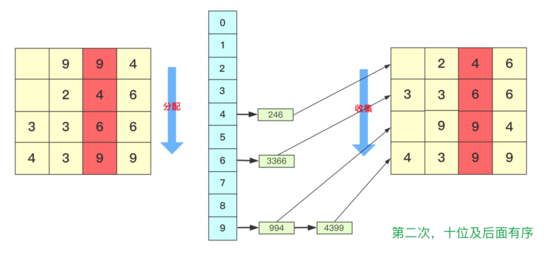
分配和收集都是有序的,第二次會根據十位進行分配、收集,此次是在第一次個位分配、收集基礎上進行的,所以所有數字單看個位十位是有序的。
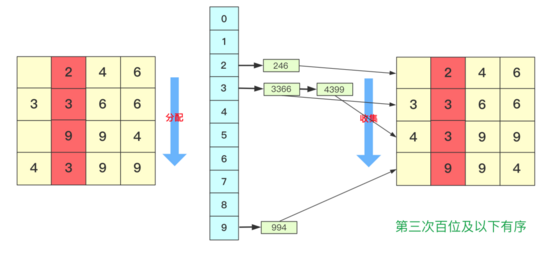
而第三次就是對百位進行分配收集,此次完成之后百位及其以下是有序的。
而最后一次的時候進行處理的時候,千位有的數字需要補零,這次完畢后后千位及以后都有序,即整個序列排序完成。
簡單實現代碼為:
static void radixSort(int[] arr)//int 類型 從右往左 { List<Integer>bucket[]=new ArrayList[10]; for(int i=0;i<10;i++) { bucket[i]=new ArrayList<Integer>(); } //找到最大值 int max=0;//假設都是正數 for(int i=0;i<arr.length;i++) { if(arr[i]>max) max=arr[i]; } int divideNum=1;//1 10 100 100……用來求對應位的數字 while (max>0) {//max 和num 控制 for(int num:arr) { bucket[(num/divideNum)%10].add(num);//分配 將對應位置的數字放到對應bucket中 } divideNum*=10; max/=10; int idx=0; //收集 重新撿起數據 for(List<Integer>list:bucket) { for(int num:list) { arr[idx++]=num; } list.clear();//收集完需要清空留下次繼續使用 } } }當然,基數排序還有字符串等長、不等長、一維數組優化等各種實現需要需學習,具體可以參考公眾號內其他文章。
本次十大排序就這么瀟灑的過了一遍,我想大家都應該有所領悟了吧!對于算法總結,避免不必要的勞動力,我分享這個表格給大家:
| 排序算法 | 平均時間復雜度 | 最好 | 最壞 | 空間復雜度 | 穩定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 穩定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | O(logn) | 不穩定 |
| 插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 穩定 |
| 希爾排序 | O(n^1.3) | O(n) | O(nlog2n) | O(1) | 不穩定 |
| 選擇排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不穩定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不穩定 |
| 歸并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 穩定 |
| 桶排序 | O(n+k) | O(n+k) | O(n+k) | O(n+k) | 穩定 |
| 計數排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 穩定 |
| 基數排序 | O(n*k) | O(n*k) | O(n*k) | O(n+k) | 穩定 |
到此,關于“程序員必知必會的排序算法有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





