溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Linux中虛擬文件系統是什么意思”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Linux中虛擬文件系統是什么意思”這篇文章吧。
虛擬文件系統是一種神奇的抽象,它使得 “一切皆文件” 哲學在 Linux 中成為了可能。
什么是文件系統?根據早期的 Linux 貢獻者和作家 Robert Love 所說,“文件系統是一個遵循特定結構的數據的分層存儲。” 不過,這種描述也同樣適用于 VFAT(虛擬文件分配表)、Git 和Cassandra(一種 NoSQL 數據庫)。那么如何區別文件系統呢?
Linux 內核要求文件系統必須是實體,它還必須在持久對象上實現 open()、read() 和 write() 方法,并且這些實體需要有與之關聯的名字。從 面向對象編程 的角度來看,內核將通用文件系統視為一個抽象接口,這三大函數是“虛擬”的,沒有默認定義。因此,內核的默認文件系統實現被稱為虛擬文件系統(VFS)。
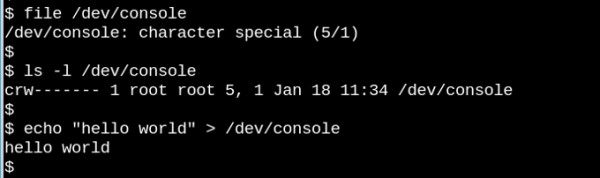
如果我們能夠 open()、read() 和 write(),它就是一個文件,如這個主控臺會話所示。
VFS 是著名的類 Unix 系統中 “一切皆文件” 概念的基礎。讓我們看一下它有多奇怪,上面的小小演示體現了字符設備 /dev/console 實際的工作。該圖顯示了一個在虛擬電傳打字控制臺(tty)上的交互式 Bash 會話。將一個字符串發送到虛擬控制臺設備會使其顯示在虛擬屏幕上。而 VFS 甚至還有其它更奇怪的屬性。例如,它可以在其中尋址。
我們熟悉的文件系統如 ext4、NFS 和 /proc 都在名為 file_operations 的 C 語言數據結構中提供了三大函數的定義。此外,個別的文件系統會以熟悉的面向對象的方式擴展和覆蓋了 VFS 功能。正如 Robert Love 指出的那樣,VFS 的抽象使 Linux 用戶可以輕松地將文件復制到(或復制自)外部操作系統或抽象實體(如管道),而無需擔心其內部數據格式。在用戶空間這一側,通過系統調用,進程可以使用文件系統方法之一 read() 從文件復制到內核的數據結構中,然后使用另一種文件系統的方法 write() 輸出數據。
屬于 VFS 基本類型的函數定義本身可以在內核源代碼的 fs/*.c 文件 中找到,而 fs/ 的子目錄中包含了特定的文件系統。內核還包含了類似文件系統的實體,例如 cgroup、/dev 和 tmpfs,在引導過程的早期需要它們,因此定義在內核的 init/ 子目錄中。請注意,cgroup、/dev 和 tmpfs 不會調用 file_operations 的三大函數,而是直接讀取和寫入內存。
下圖大致說明了用戶空間如何訪問通常掛載在 Linux 系統上的各種類型文件系統。像管道、dmesg 和 POSIX 時鐘這樣的結構在此圖中未顯示,它們也實現了 struct file_operations,而且其訪問也要通過 VFS 層。
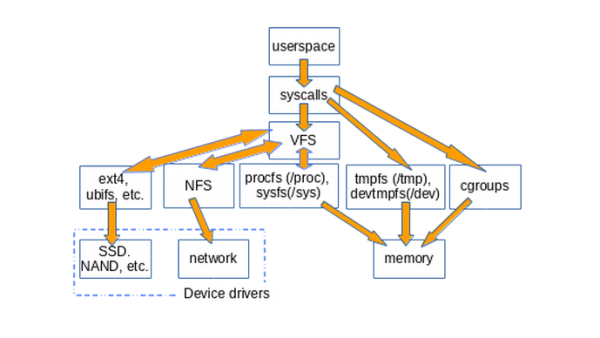
How userspace accesses various types of filesystems
VFS 是個“墊片層”,位于系統調用和特定 file_operations 的實現(如 ext4 和 procfs)之間。然后,file_operations 函數可以與特定于設備的驅動程序或內存訪問器進行通信。tmpfs、devtmpfs 和 cgroup 不使用 file_operations 而是直接訪問內存。
VFS 的存在促進了代碼重用,因為與文件系統相關的基本方法不需要由每種文件系統類型重新實現。代碼重用是一種被廣泛接受的軟件工程***實踐!唉,但是如果重用的代碼引入了嚴重的錯誤,那么繼承常用方法的所有實現都會受到影響。
找出系統中存在的 VFS 的簡單方法是鍵入 mount | grep -v sd | grep -v :/,在大多數計算機上,它將列出所有未駐留在磁盤上,同時也不是 NFS 的已掛載文件系統。其中一個列出的 VFS 掛載肯定是 /tmp,對吧?

誰都知道把 /tmp 放在物理存儲設備上簡直是瘋了!圖片:https://tinyurl.com/ybomxyfo
為什么把 /tmp 留在存儲設備上是不可取的?因為 /tmp 中的文件是臨時的(!),并且存儲設備比內存慢,所以創建了 tmpfs 這種文件系統。此外,比起內存,物理設備頻繁寫入更容易磨損。***,/tmp 中的文件可能包含敏感信息,因此在每次重新啟動時讓它們消失是一項功能。
不幸的是,默認情況下,某些 Linux 發行版的安裝腳本仍會在存儲設備上創建 /tmp。如果你的系統出現這種情況,請不要絕望。按照一直優秀的 Arch Wiki 上的簡單說明來解決問題就行,記住分配給 tmpfs 的內存就不能用于其他目的了。換句話說,包含了大文件的龐大的 tmpfs 可能會讓系統耗盡內存并崩潰。
另一個提示:編輯 /etc/fstab 文件時,請務必以換行符結束,否則系統將無法啟動。(猜猜我怎么知道。)
除了 /tmp 之外,大多數 Linux 用戶最熟悉的 VFS 是 /proc 和 /sys。(/dev 依賴于共享內存,而沒有 file_operations 結構)。為什么有兩種呢?讓我們來看看更多細節。
procfs 為用戶空間提供了內核及其控制的進程的瞬時狀態的快照。在 /proc 中,內核發布有關其提供的設施的信息,如中斷、虛擬內存和調度程序。此外,/proc/sys 是存放可以通過 sysctl 命令配置的設置的地方,可供用戶空間訪問。單個進程的狀態和統計信息在 /proc/<PID> 目錄中報告。
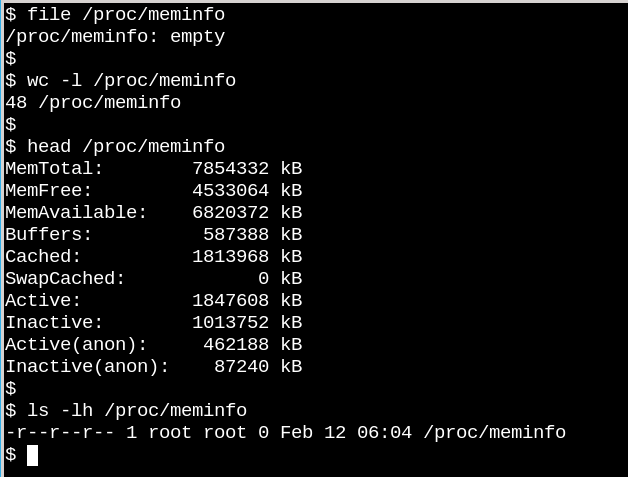
/proc/meminfo 是一個空文件,但仍包含有價值的信息。
/proc 文件的行為說明了 VFS 可以與磁盤上的文件系統不同。一方面,/proc/meminfo 包含了可由命令 free 展現出來的信息。另一方面,它還是空的!怎么會這樣?這種情況讓人聯想起康奈爾大學物理學家 N. David Mermin 在 1985 年寫的一篇名為《沒有人看見月亮的情況嗎?現實和量子理論》。事實是當進程從 /proc 請求數據時內核再收集有關內存的統計信息,而且當沒有人查看它時,/proc 中的文件實際上沒有任何內容。正如 Mermin 所說,“這是一個基本的量子學說,一般來說,測量不會揭示被測屬性的預先存在的價值。”(關于月球的問題的答案留作練習。)

當沒有進程訪問它們時,/proc 中的文件為空。(來源)
procfs 的空文件是有道理的,因為那里可用的信息是動態的。sysfs 的情況則不同。讓我們比較一下 /proc 與 /sys 中不為空的文件數量。

procfs 只有一個不為空的文件,即導出的內核配置,這是一個例外,因為每次啟動只需要生成一次。另一方面,/sys 有許多更大一些的文件,其中大多數由一頁內存組成。通常,sysfs 文件只包含一個數字或字符串,與通過讀取 /proc/meminfo 等文件生成的信息表格形成鮮明對比。
sysfs 的目的是將內核稱為 “kobject” 的可讀寫屬性公開給用戶空間。kobject 的唯一目的是引用計數:當刪除對 kobject 的***一個引用時,系統將回收與之關聯的資源。然而,/sys 構成了內核著名的“到用戶空間的穩定 ABI”,它的大部分內容在任何情況下都沒有人能“破壞”。但這并不意味著 sysfs 中的文件是靜態,這與易失性對象的引用計數相反。
內核的穩定 ABI 限制了 /sys 中可能出現的內容,而不是任何給定時刻實際存在的內容。列出 sysfs 中文件的權限可以了解如何設置或讀取設備、模塊、文件系統等的可配置、可調參數。邏輯上強調 procfs 也是內核穩定 ABI 的一部分的結論,盡管內核的文檔沒有明確說明。
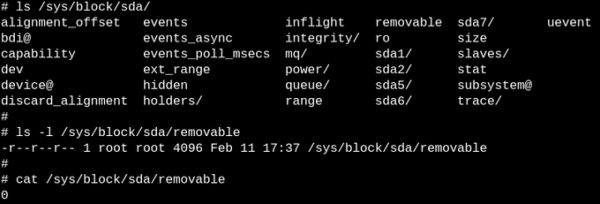
sysfs 中的文件確切地描述了實體的每個屬性,并且可以是可讀的、可寫的,或兩者兼而有之。文件中的“0”表示 SSD 不可移動的存儲設備。
了解內核如何管理 sysfs 文件的最簡單方法是觀察它的運行情況,在 ARM64 或 x86_64 上觀看的最簡單方法是使用 eBPF。eBPF(擴展的伯克利數據***濾器)由在內核中運行的虛擬機組成,特權用戶可以從命令行進行查詢。內核源代碼告訴讀者內核可以做什么;而在一個啟動的系統上運行 eBPF 工具會顯示內核實際上做了什么。
令人高興的是,通過 bcc 工具入門使用 eBPF 非常容易,這些工具在主要 Linux 發行版的軟件包 中都有,并且已經由 Brendan Gregg 給出了充分的文檔說明。bcc 工具是帶有小段嵌入式 C 語言片段的 Python 腳本,這意味著任何對這兩種語言熟悉的人都可以輕松修改它們。據當前統計,bcc/tools 中有 80 個 Python 腳本,使得系統管理員或開發人員很有可能能夠找到與她/他的需求相關的已有腳本。
要了解 VFS 在正在運行中的系統上的工作情況,請嘗試使用簡單的 vfscount 或 vfsstat 腳本,這可以看到每秒都會發生數十次對 vfs_open() 及其相關的調用。
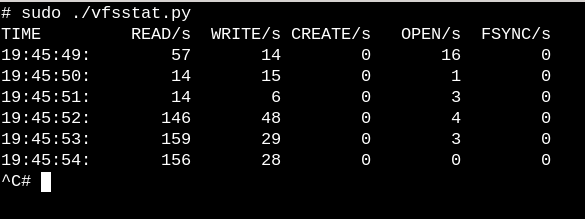
vfsstat.py 是一個帶有嵌入式 C 片段的 Python 腳本,它只是計數 VFS 函數調用。
作為一個不太重要的例子,讓我們看一下在運行的系統上插入 USB 記憶棒時 sysfs 中會發生什么。
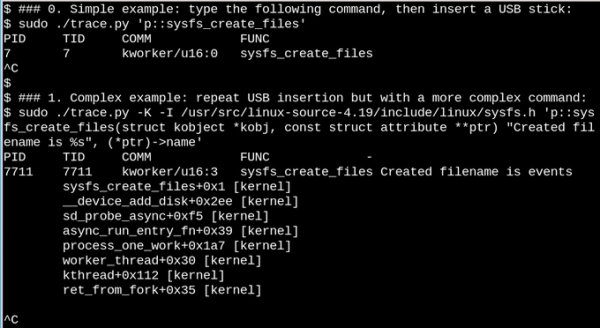
用 eBPF 觀察插入 USB 記憶棒時 /sys 中會發生什么,簡單的和復雜的例子。
在上面的***個簡單示例中,只要 sysfs_create_files() 命令運行,trace.py bcc 工具腳本就會打印出一條消息。我們看到 sysfs_create_files() 由一個 kworker 線程啟動,以響應 USB 棒的插入事件,但是它創建了什么文件?第二個例子說明了 eBPF 的強大能力。這里,trace.py 正在打印內核回溯(-K 選項)以及 sysfs_create_files() 創建的文件的名稱。單引號內的代碼段是一些 C 源代碼,包括一個易于識別的格式字符串,所提供的 Python 腳本引入 LLVM 即時編譯器(JIT) 來在內核虛擬機內編譯和執行它。必須在第二個命令中重現完整的 sysfs_create_files() 函數簽名,以便格式字符串可以引用其中一個參數。在此 C 片段中出錯會導致可識別的 C 編譯器錯誤。例如,如果省略 -I 參數,則結果為“無法編譯 BPF 文本”。熟悉 C 或 Python 的開發人員會發現 bcc 工具易于擴展和修改。
插入 USB 記憶棒后,內核回溯顯示 PID 7711 是一個 kworker 線程,它在 sysfs 中創建了一個名為 events 的文件。使用 sysfs_remove_files() 進行相應的調用表明,刪除 USB 記憶棒會導致刪除該 events 文件,這與引用計數的想法保持一致。在 USB 棒插入期間(未顯示)在 eBPF 中觀察 sysfs_create_link() 表明創建了不少于 48 個符號鏈接。
無論如何,events 文件的目的是什么?使用 cscope 查找函數 __device_add_disk() 顯示它調用 disk_add_events(),并且可以將 “mediachange” 或 “ejectrequest” 寫入到該文件。這里,內核的塊層通知用戶空間該 “磁盤” 的出現和消失。考慮一下這種檢查 USB 棒的插入的工作原理的方法與試圖僅從源頭中找出該過程的速度有多快。
確實,沒有人通過拔出電源插頭來關閉服務器或桌面系統。為什么?因為物理存儲設備上掛載的文件系統可能有掛起的(未完成的)寫入,并且記錄其狀態的數據結構可能與寫入存儲器的內容不同步。當發生這種情況時,系統所有者將不得不在下次啟動時等待 fsck 文件系統恢復工具 運行完成,在最壞的情況下,實際上會丟失數據。
然而,狂熱愛好者會聽說許多物聯網和嵌入式設備,如路由器、恒溫器和汽車現在都運行著 Linux。許多這些設備幾乎完全沒有用戶界面,并且沒有辦法干凈地讓它們“解除啟動”。想一想啟動電池耗盡的汽車,其中運行 Linux 的主機設備 的電源會不斷加電斷電。當引擎最終開始運行時,系統如何在沒有長時間 fsck 的情況下啟動呢?答案是嵌入式設備依賴于只讀根文件系統(簡稱 ro-rootfs)。
ro-rootfs 是嵌入式系統不經常需要 fsck 的原因。 來源:https://tinyurl.com/yxoauoub
ro-rootfs 提供了許多優點,雖然這些優點不如耐用性那么顯然。一個是,如果 Linux 進程不可以寫入,那么惡意軟件也無法寫入 /usr 或 /lib。另一個是,基本上不可變的文件系統對于遠程設備的現場支持至關重要,因為支持人員擁有理論上與現場相同的本地系統。也許最重要(但也是最微妙)的優勢是 ro-rootfs 迫使開發人員在項目的設計階段就決定好哪些系統對象是不可變的。處理 ro-rootfs 可能經常是不方便甚至是痛苦的,編程語言中的常量變量經常就是這樣,但帶來的好處很容易償還這種額外的開銷。
對于嵌入式開發人員,創建只讀根文件系統確實需要做一些額外的工作,而這正是 VFS 的用武之地。Linux 需要 /var 中的文件可寫,此外,嵌入式系統運行的許多流行應用程序會嘗試在 $HOME 中創建配置的點文件。放在家目錄中的配置文件的一種解決方案通常是預生成它們并將它們構建到 rootfs 中。對于 /var,一種方法是將其掛載在單獨的可寫分區上,而 / 本身以只讀方式掛載。使用綁定或疊加掛載是另一種流行的替代方案。
運行 man mount 是了解綁定掛載和疊加掛載的***辦法,這種方法使得嵌入式開發人員和系統管理員能夠在一個路徑位置創建文件系統,然后以另外一個路徑將其提供給應用程序。對于嵌入式系統,這代表著可以將文件存儲在 /var 中的不可寫閃存設備上,但是在啟動時將 tmpfs 中的路徑疊加掛載或綁定掛載到 /var 路徑上,這樣應用程序就可以在那里隨意寫它們的內容了。下次加電時,/var 中的變化將會消失。疊加掛載為 tmpfs 和底層文件系統提供了聯合,允許對 ro-rootfs 中的現有文件進行直接修改,而綁定掛載可以使新的空 tmpfs 目錄在 ro-rootfs 路徑中顯示為可寫。雖然疊加文件系統是一種適當的文件系統類型,而綁定掛載由 VFS 命名空間工具 實現的。
根據疊加掛載和綁定掛載的描述,沒有人會對 Linux 容器 中大量使用它們感到驚訝。讓我們通過運行 bcc 的 mountsnoop 工具監視當使用 systemd-nspawn 啟動容器時會發生什么:

在 mountsnoop.py 運行的同時,system-nspawn 調用啟動容器。
讓我們看看發生了什么:
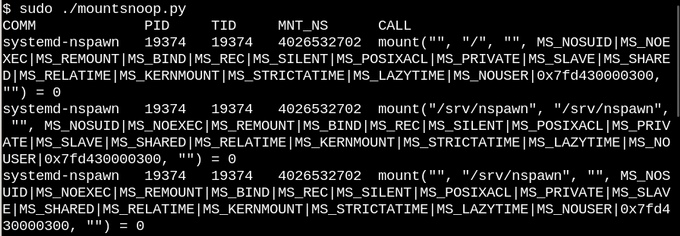
在容器 “啟動” 期間運行 mountsnoop 可以看到容器運行時很大程度上依賴于綁定掛載。(僅顯示冗長輸出的開頭)
這里,systemd-nspawn 將主機的 procfs 和 sysfs 中的選定文件按其 rootfs 中的路徑提供給容器。除了設置綁定掛載時的 MS_BIND 標志之外,mount 系統調用的一些其它標志用于確定主機命名空間和容器中的更改之間的關系。例如,綁定掛載可以將 /proc 和 /sys 中的更改傳播到容器,也可以隱藏它們,具體取決于調用。
以上是“Linux中虛擬文件系統是什么意思”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





