溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Linux中如何解決網卡中斷與CPU綁定問題”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Linux中如何解決網卡中斷與CPU綁定問題”這篇文章吧。
在Linux的網絡調優方面,如果你發現網絡流量上不去,那么有一個方面需要去查一下:網卡處理網絡請求的中斷是否被綁定到單個CPU或跟處理其它中斷的是同一個CPU。
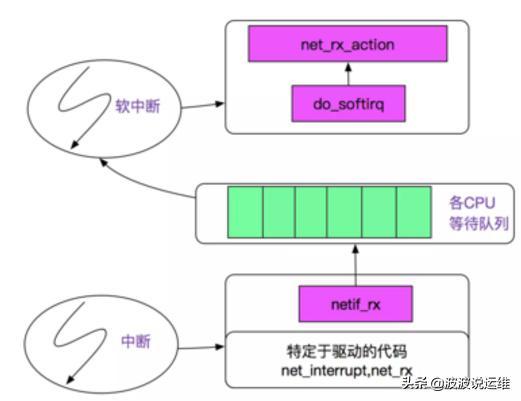
網卡與操作系統的交互方式
網卡與操作系統的交互一般有兩種方式:
1. 中斷IRQ
網卡在收到了網絡信號之后,主動發送中斷到CPU,而CPU將會立即停下手邊的活以便對這個中斷信號進行分析;
2. DMA(Direct Memory Access)
也就是允許硬件在無CPU干預的情況下將數據緩存在指定的內存空間內,在CPU合適的時候才處理;
現在的對稱多核處理器(SMP)上,一塊網卡的IRQ還是只有一個CPU來響應,其它CPU無法參與,如果這個CPU還要忙其它的中斷(其它網卡或者其它使用中斷的外設(比如磁盤)),那么就會形成瓶頸。
檢查環境
首先,讓網絡跑滿。如:對于MySQL/MongoDB服務,可以通過客戶端發起密集的讀操作 或執行一個大文件傳送任務。查明是不是某個CPU在一直忙著處理IRQ?
從 mpstat -P ALL 1 輸出里面的 %irq一列即說明了哪個CPU忙于處理中斷的時間占比;
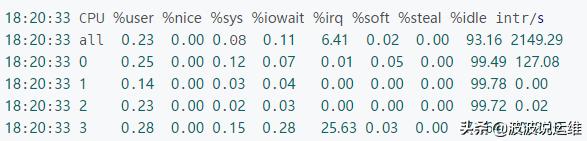
上面的例子中,第四個CPU有25.63%時間在忙于處理中斷,后面 intr/s 也說明了CPU每秒處理的中斷數。從上面的數據可以看出,其它幾個CPU都不怎么處理中斷。
那么,這些忙于處理中斷的CPU都在處理哪些中斷?
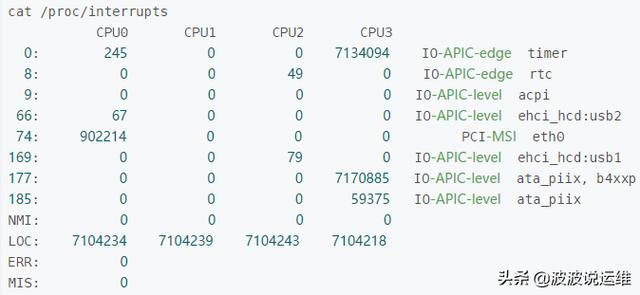
這里記錄的是自啟動以來,每個CPU處理各類中斷的數量。第一列是中斷號,最后一列是對應的設備名。從上面可以看到: eth0所出發的中斷全部都是 CPU0在處理,而CPU0所處理的中斷請求中,主要是eth0和LOC中斷。有時我們會看到幾個CPU對同一個中斷類型所處理的的請求數相差無幾(比如上面的LOC),這并不一定是說多個CPU會輪流處理同一個中斷,而是因為這里記錄的是“自啟動以來”的統計,中間可能因為irq balancer重新分配過處理中斷的CPU。
解決思路
現在的多數Linux系統中都有IRQ Balance這個服務(服務程序一般是 /usr/sbin/irqbalance),它可以自動調節分配各個中斷與CPU的綁定關系,以避免所有中斷的處理都集中在少數幾個CPU上。在某些情況下,這個IRQ Balance反而會導致問題,會出現 irqbalance 這個進程反而自身占用了較高的CPU(當然也就影響了業務系統的性能)。
首先要看該網卡的中斷當前是否已經限定到某些CPU了?具體是哪些CPU?
根據上面 /proc/interrupts 的內容我們可以看到 eth0 的中斷號是74,然后我們來看看該中斷號的CPU綁定情況或者說叫親和性 affinity。
$ sudo cat /proc/irq/74/smp_affinity ffffff
這個輸出是一個16進制的數值,0xffffff = '0b111111111111111111111111',這就意味著這里有24個CPU,所有位都為1表示所有CPU都可以被該中斷干擾。
修改配置的方法:(設置為2表示將該中斷綁定到CPU1上,0x2 = 0b10,而第一個CPU為CPU0)
echo 2 > /proc/irq/74/smp_affinity
以上是“Linux中如何解決網卡中斷與CPU綁定問題”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





