溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么快速從深層嵌套JSON中找到特定的Key”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

在爬蟲開發的過程中,我們經常遇到一些 Ajax 加載的接口會返回 JSON 數據。如下圖所示,是 Twitter 的用戶時間線接口,返回了一段3000多行的深層嵌套 JSON:
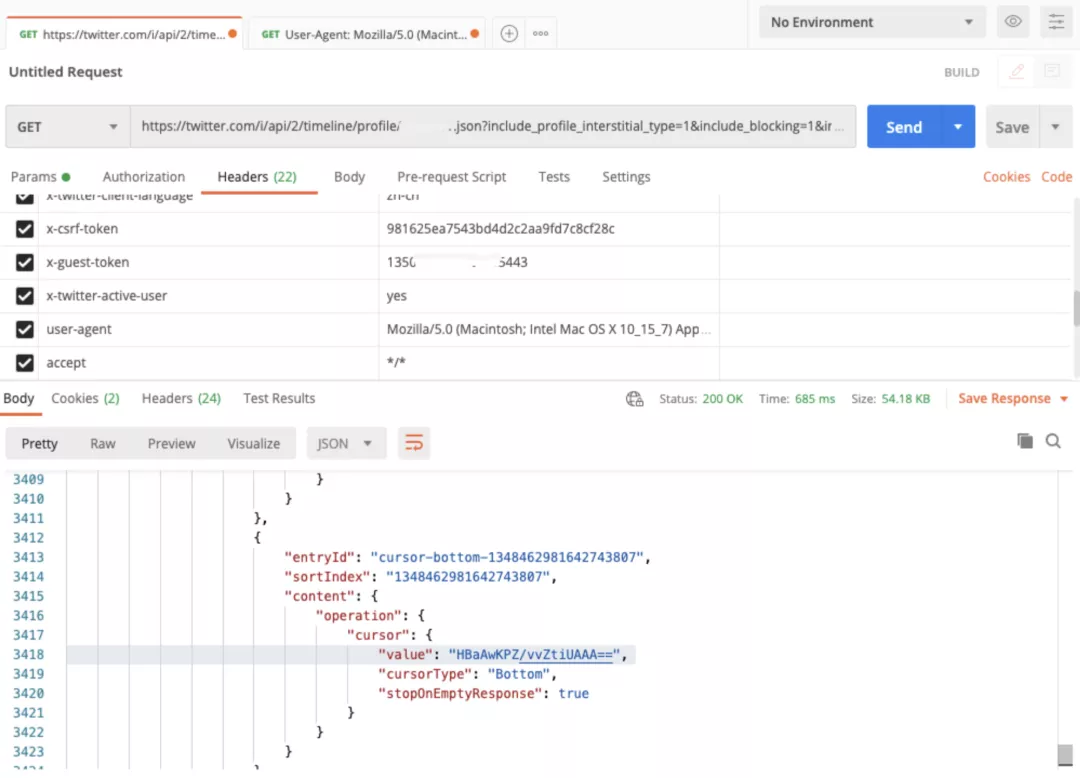
其中的cursor這個字段,是請求下一頁的必要字段,我必須把它的 value 值讀取出來,拼接到請求 URL 中,才能請求下一頁的內容。
現在問題來了,cursor字段在這個 JSON 里面的哪個位置?從最外層開始,我應該怎么樣才能讀取到最里面的這個cursor中的value字段的值?
我知道已經有一些第三方庫可以直接根據字段名讀取 JSON 內部任意深度的值,不過用別人的東西總沒有自己寫一個輪子來得過癮。所以今天我們自己來手寫一個模塊,我把他叫做JsonPathFinder,傳入一個 JSON 字符串和需要讀取的字段名,返回從最外層開始直到這個字段的路徑。
效果演示
我們用 Python 之父龜叔的 Twitter 時間線來作為演示,運行以后,效果如下圖所示:
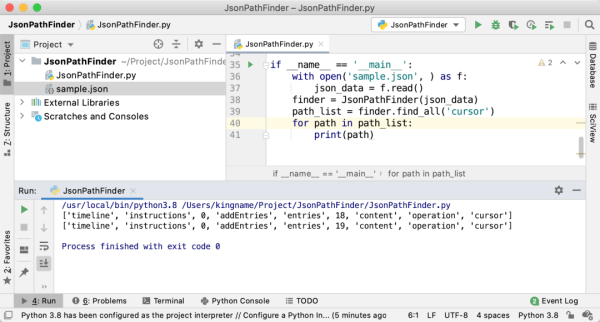
可以看到,從最外層開始一路讀到cursor字段,需要經過非常多的字段名,對應到 JSON 中,如下圖所示:
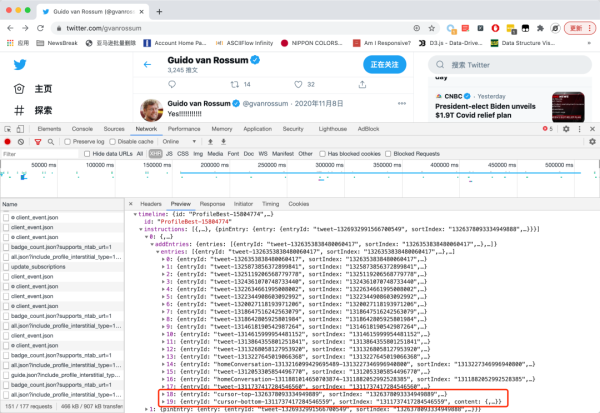
由于entries 字段列表中一共有20個元素,所以這里的18、19實際上對應了倒數第二條和倒數第一條數據。其中,倒數第二條的 cursor 對應的是本頁第一條推文,而倒數第一條對應的是本頁最后一條推文。所以當我們要往后翻頁的時候,應該用的是倒數第一條的 cursor。
我們試著來讀取一下結果:
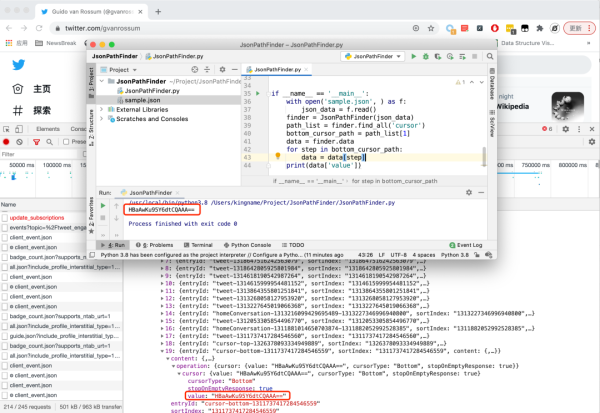
非常輕松地獲取到了數據。不需要再肉眼在 JSON 中尋找字段了。
原理分析
JsonPathFinder 的原理并不復雜,全部代碼加上空行,一共只有32行,如下圖所示:
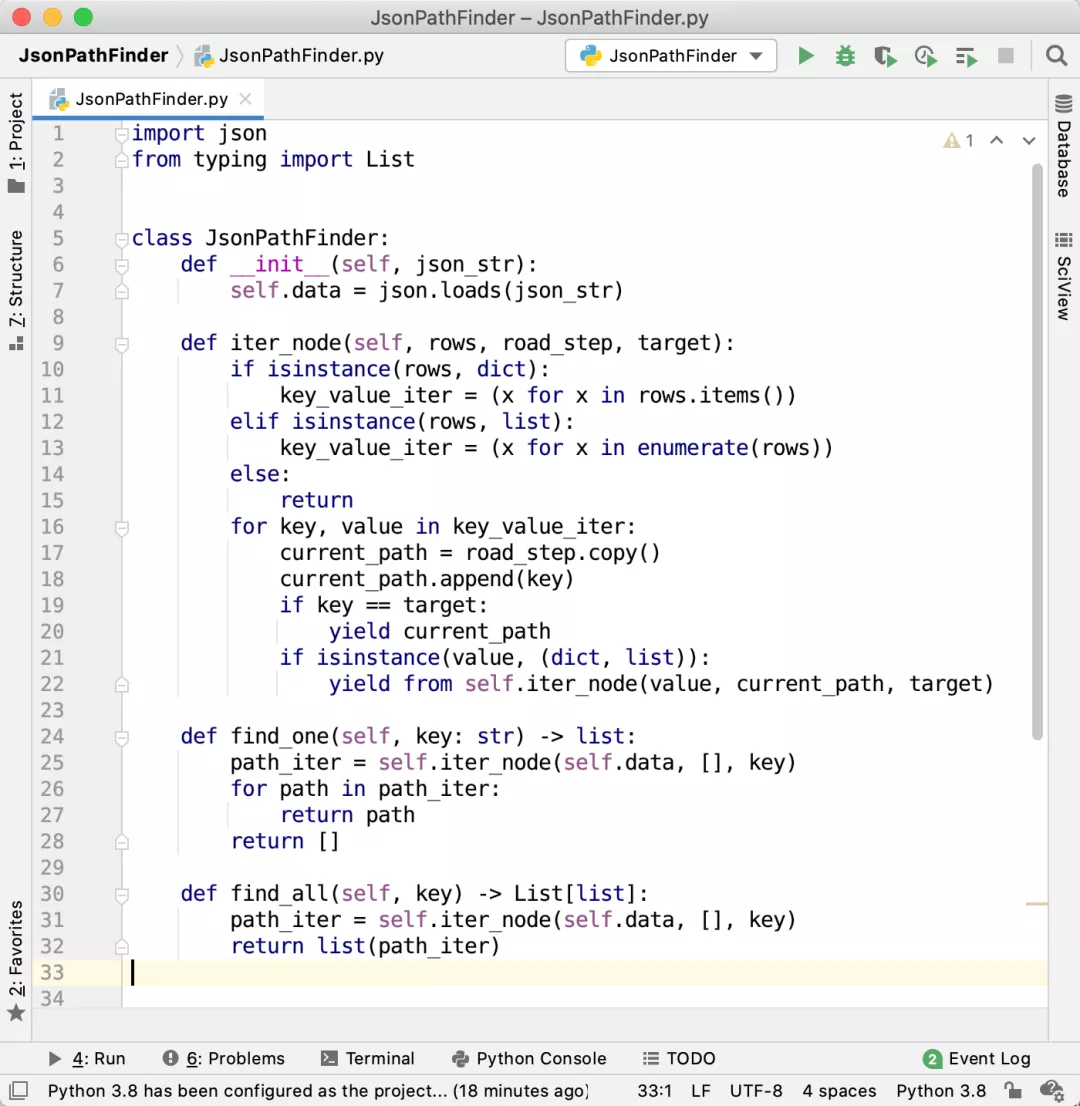
因為一個字段在 JSON 中可能出現很多次,所以find_one方法返回從外層到目標字段的第一條路徑。而find_all方法返回從外層到目標字段的所有路徑。
而核心算法,就是iter_node方法。在把 JSON 字符串轉成 Python 的字典或者列表以后,這個方法使用深度優先遍歷整個數據,記錄它走過的每一個字段,如果遇到列表就把列表的索引作為 Key。直到遍歷到目標字段,或者某個字段的值不是列表也不是字典時結束本條路徑,繼續遍歷下個節點。
代碼第10-15行,分別對列表和字典進行處理。對于字典來說,我們分離 key 和 value,寫作:
for key, value in xxx.items(): ...
對于列表,我們分離索引和元素,寫作:
for index, element in enumerate(xxx): ...
所以如在第11和第13行,使用生成器推導式分別處理字典和列表,這樣得到的key_value_iter生成器對象,就可以在第16行被相同的 for 循環迭代。
我們知道,在 Python 里面可以迭代的對象除了字典和列表以外,還有很多其他的對象,不過我這里只處理了字典和列表。大家也可以試一試修改10-15行的條件判斷,增加對其他可迭代對象的處理邏輯。
代碼第16-22行,對處理以后的 key-value 進行迭代。首先記錄到當前字段為止的迭代路徑到current_path列表中。然后判斷當前字段是不是目標字段。如果是,那么把當前的路徑通過 yield 拋出來。如果當前路徑的值是列表或者字典,那么把這個值遞歸傳入 iter_node 方法,進一步檢查內部還有沒有目標字段。需要注意的是,無論當前字段是不是目標字段,只要它的值是列表或者字典,都需要繼續迭代。因為即使當前字段的名字是目標字段,但也許它內部還有某個子孫字段的字段名也是目標字段名。
對于普通函數來說,要遞歸調用,直接return 當前函數(參數)就可以了。但是對于生成器來說,要遞歸調用,就需要使用yield from 當前函數名(參數)。
由于iter_node方法返回的是一個生成器對象,在 find_one和find_all方法中,for 循環每一次迭代,都能拿到一條從20行拋出來的到目標字段的路徑。而在find_one方法中,當我們拿到第一條路徑時,不再繼續迭代,那么就可以節省大量的時間,減少迭代次數。
正確使用
有了這個工具以后,我們可以直接用它來解析數據,也可以用來輔助分析數據。例如,Twitter 時間線的正文是在full_text中,我可以直接用 JsonPathFinder 獲取所有的正文:
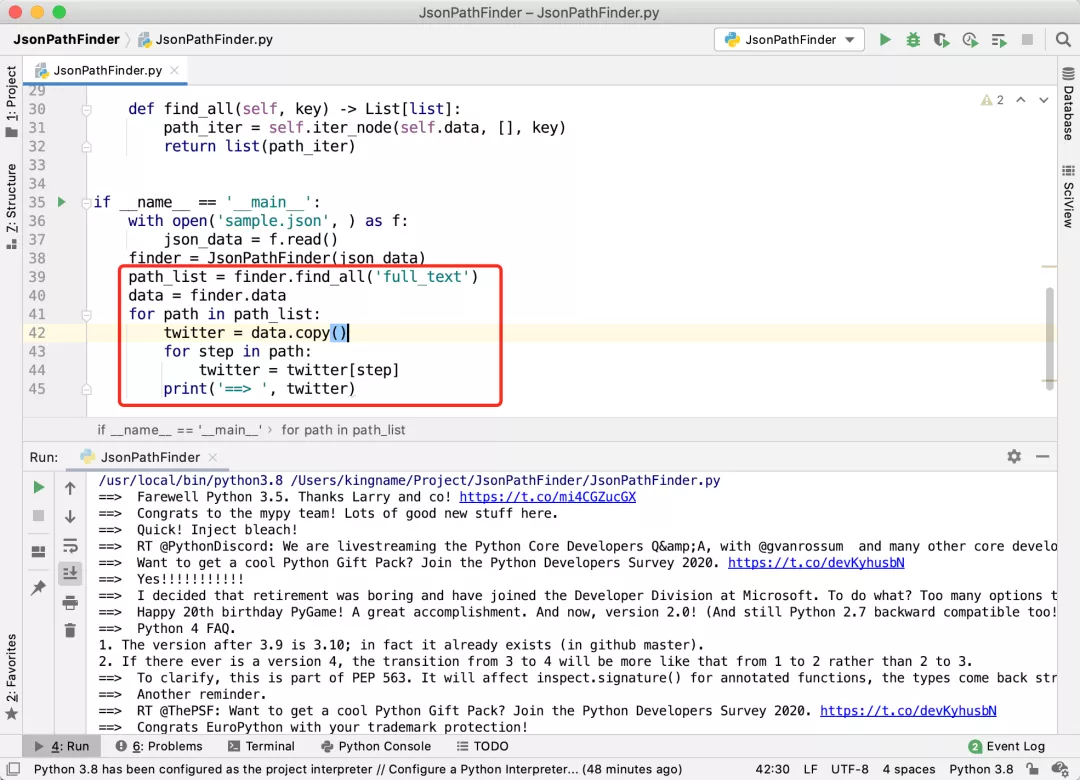
但有時候,我們除了獲取正文外,還需要每一條推文的其他信息,如下圖所示:
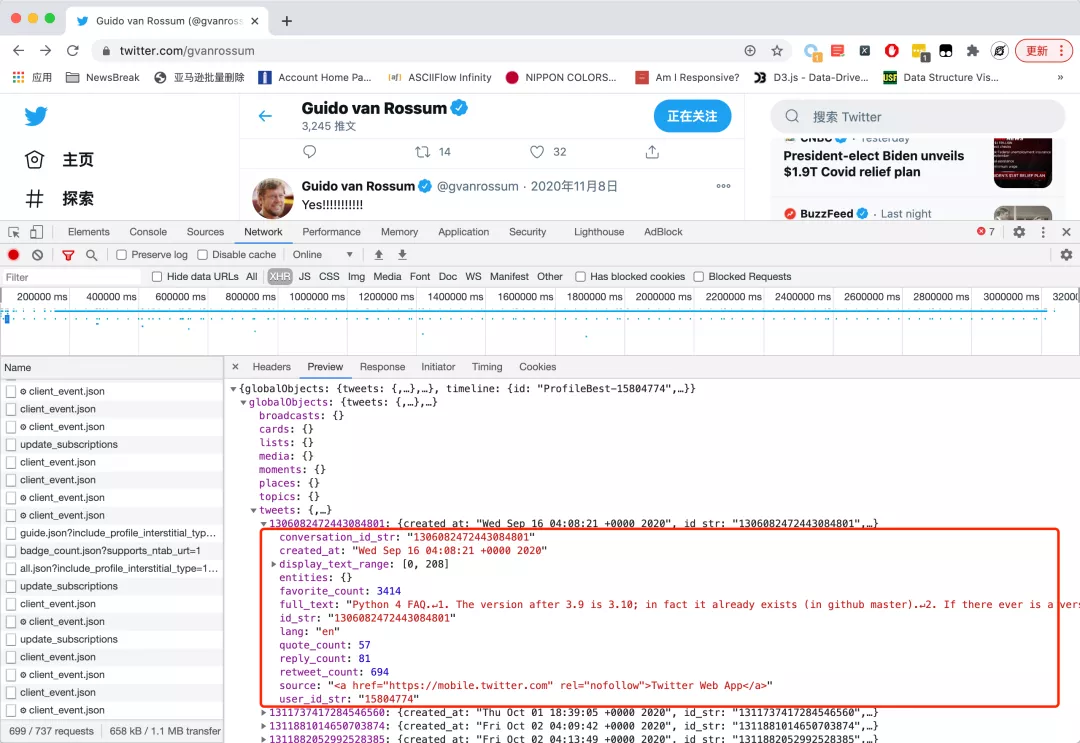
可以看到, 這種情況下,我們可以先獲取從外層到full_text的路徑列表,然后再人工對列表進行一些加工,輔助開發:
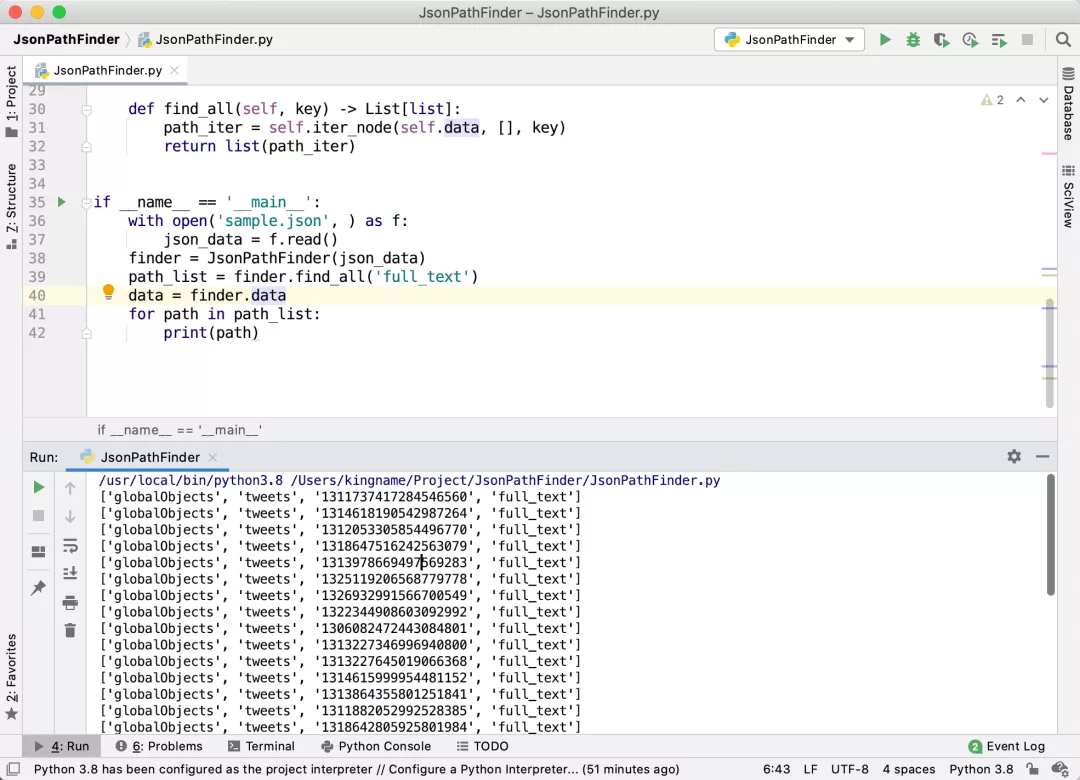
從打印出來的路徑列表里面可以看到,我們只需要獲取globalObjects->tweets就可以了。它的值是20個字典,每個字典的 Key 是推文的 ID,Value 是推文的詳情。這個時候,我們再人工去修改一下代碼,也能方便地提取一條推文的全部字段。
“怎么快速從深層嵌套JSON中找到特定的Key”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





