溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么實現一個前端監控回放系統”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么實現一個前端監控回放系統”吧!
要想給用戶的訪問做一次完整的應用狀態監控錄制與回放,除了錄制視頻外,通過 Web API 實現大致有兩類主流的解決思路。
第一種方案是通過記錄 DOM 的每次變更,并將內容序列化下來,然后在沙箱中還原并回放這些 UI 變化。這種方案的優點之一是能夠給 DOM 創建快照的概念,在應用每一次狀態變化后進行收集,把這個序列串起來后我們便可以靈活掌握回放速度、并針對關鍵性節點進行自定義回放。在社區開源方案中,這類技術最成熟的莫過于 rrweb https://github.com/rrweb-io/rrweb ,此外若干互聯網企業也有提供一些商業解決方案,但技術設計上大同小異,大致都可以拆分為 DOM 序列化、構建快照序列、反序列化回放以及運行沙箱環境等四方面。
另一種可行方案,從我們的調研結果來看,是將用戶側所有數據收集起來,然后在一個可控運行環境下嚴格按照校準時間對用戶事件操作進行派發,從而控制回放。這里主要分為兩部分,一方面因為我們通過派發事件來重演用戶的行為,便需要高精度計時器以及完善的用戶事件收集策略;另一方面,由于要保證應用狀態在兩端的變化一致性,只嚴格觸發用戶的操作還不夠,我們還要將任何應用與網絡之前的交互操作(請求與響應內容)精準對齊,所以我們需要攔截所有請求、即時的前端構建產物以及用戶操作序列等等。
第二種方案由于可以近乎模擬用戶側運行時的狀態變化,相當于將當時的用戶整個搬到了我們面前,因此可以方便開發同學進一步調試。在社區開源方案中,我們沒有找到類似的實現,但商業方案中 https://logrocket.com/ 最接近這個思路,其提供的不少功能甚至比這里提及的功能要更強大。
但本文中,我們只討論當需要實現這樣一個系統時的涉及技術項。所以接下來,來看看我們在調研中記錄的一些有用的 Web API,希望對你們實現有幫助。
本章主要介紹要實現這樣一個前端監控回放系統的四個環節,關于這些內容,rrweb 的描述篇幅會更加翔實,可以更進一步查閱他們的文檔描述。
如何回放一個應用的狀態變化?首先,我們要將應用的內容以及狀態變化收集起來。如果用 jQuery 我們可以這樣實現 body 內容的收集與替換:
// record const snapshot = $('body').clone(); // replay $('body').replaceWith(snapshot);如果換用MediaRecorder API,利用 ondataavailable 和 onstop 兩個事件處理 API,我們還可以將 DOM 轉變成可播放的媒體文件,比如這樣:
startRecording() { const stream = (this.canvas as any).captureStream(); this.recorder = new MediaRecorder(stream, { mimeType: 'video/webm' }); const data = []; this.recorder.ondataavailable = (event) => { if (event.data && event.data.size) { data.push(event.data); } }; this.recorder.onstop = () => { const url = URL.createObjectURL(new Blob(data, { type: 'video/webm' })); this.videoUrl$.next( this.sanitizer.bypassSecurityTrustUrl(url) ); }; this.recorder.start(); this.recordVideo$.next(true); }但這些內容是沒法序列化的,而媒體體積又過于龐大且無法進一步分析。舉個例子,一個 input 標簽,如果我們不做任何額外處理只將其轉化成文本進行存儲(類似 innerHTML),那么其中包含的 value 等狀態便會丟失,這便是我們首先需要將 DOM 及其視圖狀態進行序列化的原因所在。關于如何序列化 DOM 也有不少開源方案比如 https://github.com/inikulin/parse5 ,rrweb 在文檔中有提到為什么沒有采用的原因,而我這里簡單列一下在序列化環節中需要考慮的幾點細節:
如何將 DOM 樹轉化成一個帶視圖狀態的樹狀結構,包括未反映在 HTML 中的視圖狀態;
如何定義唯一標識,方便應用狀態變化(快照)的溯源;
如何處理特殊標簽諸如 script 以及樣式等內容,因方案而異;
簡而言之,這部分的目的是完成一個 DOM 樹至可存儲狀態的數據結構映射。
如果只是記錄 DOM 變更的話,我們可以很方便的利用 MutationObserver API 達到變更監聽與記錄這一目的,但此外我們還需要考慮如何將 Mutation 的批量序列轉化為快照上的增量更新。
比如,為了方便針對 Node 進行增刪時可以唯一確定其在樹形結構中的位置,我們最好設計一個合適的 DOM 唯一標記策略,此外,如何優化諸如 mousemove 以及大量頻繁 input 輸入導致的視圖變更等。前者的設計可以繼續用在增量快照的實現上,而后者的表現則直接影響用戶體驗,容易導致 DOM 在更改時 Node 記錄的出現順序錯誤。
這一環節,主要依賴 DOM 的序列化方案繼續處理。在添加一些其他必要信息諸如時間序列編號等,便可以進行存儲等操作了。
簡單來說,重演就是將收集到的數據按照順序依次“播放”一遍,視頻文件的播放需要音視頻解碼器,而我們的重演環節要做的工作就可以簡單理解成一個 Web 應用解碼器,從用戶端收集上來的數據結構除了要做清洗和存儲外,還不能直接被回放側使用,其中有不少需要考慮的細節。
舉個簡單的例子,我們利用 Web API 是沒法達到派發 hover 事件的,但是我們的項目中一定存在大量的 hover 樣式,那么如何針對這些交互做額外處理,對 Node 狀態變化做相應樣式的補全,便成為一個需要考慮的環節結合 mousedown 和 mouseup 兩個事件的觸發時機是否夠用?事件收集的掛載節點如何圈定?這些都是需要考慮的地方。再比如,回放中想跳過被認為無意義的操作片段,如何設計才能保持應用在前后兩個時間節點上不因為跳過的操作而缺失視圖狀態?
這一環節,目的是為了實現對快照存儲下來的數據結構進行回放。因為要保證回放側與收集側的嚴格一致,諸如高精度計時、DOM 補全以及交互效果模擬等細節,都需要詳細設計。
沙箱,是為了給回放提供一個安全可控的運行環境。如何采用 DOM 快照方案,那么便需要考慮如何禁止一些“不安全”的 DOM 操作。例如應用內鏈接跳轉、我們不太可能會直接給用戶打開一個新的 tab,為了保證快照狀態依次回放,我們還需要考慮如何安全準確的反序列化構建 DOM。如果實現上考慮通過派發事件的思路來實現,那么如何準確定位派發的 Node 節點、如何匹配數據請求并響應等等都是需要重點考慮的。
兩種思路都有一些需要共同考慮的事情,比如如何保證運行環境符合瀏覽器的安全限制、需要展示和用戶操作保持一致的渲染層等等。這部分在技術項拆分一節,會提到兩個解決方案,分別是 iframe 以及 puppeteer,此處不再贅述。
Web 有強大的 API List,本章節針對可能用到的 API 與相關技術做一一講解。
MutationObserver API 可以用于監聽觀察 DOM 對象的變化并予以記錄數組的形式返回,這可以用在應用初始化和增量快照的記錄部分。關于 MutationObserver 的方法與入參這里不做詳細介紹,簡單來看,要用 MutationObserver API 監聽一個 Node 的變更大致分為這么幾步:
利用 document.getElementById 等 API 定位你所需要的 Node
定義一個 MutationObserverInit 對象,此對象的配置項描述了 DOM 的哪些變化應該提供給當前觀察者的回調函數
定義上述回調函數被調用時的執行邏輯
創建一個觀察器實例并傳入回調函數
調用 MutationObserver 的 observe() 方法開始觀察
以下節選自 MDN 的一段示例代碼用于釋義:
const targetNode = document.getElementById('some-id'); const config = { attributes: true, childList: true, subtree: true }; const callback = function(mutationsList, observer) { for(let mutation of mutationsList) { if (mutation.type === 'childList') { console.log('A child node has been added or removed.'); } } }; const observer = new MutationObserver(callback); observer.observe(targetNode, config);iframe 大家肯定都用過,它能夠將另一個 HTML 頁面嵌入到當前頁面中。利用 iframe ,我們可以快速構建一個安全的沙箱機制,比如將其用于限制 JavaScript 執行等。除了我們平時直接給 iframe 的 src 屬性賦值外,iframe 還有不少其他值得了解的屬性,這些在完善運行沙箱環境上都會有所幫助,比如其中的 sandbox 屬性便可以對呈現在 iframe 中的內容啟用一些額外的限制條件。
此外,要實現沙箱中不同容器的的通信,可以通過 postMessage API 來完成。這里有一篇非常詳細的文章介紹了 iframe 的方方面面,可以進一步查閱 https://blog.logrocket.com/the-ultimate-guide-to-iframes/ 。
HTTP 請求與響應匯集,即我們常說的 HAR 格式數據。打開 chrome devtools,network tab 下的每一條數據流都代表一個請求,從 http 到 weoscket,request 到 response,包含 request 入參、headers、連接耗時、發起時間、響應時間、TTFB、內容大小等等。如同前面所述,如果要在回放側派發用戶操作的話,那么即需要在采集時將所有請求攔截并標號進行存儲,如此一來,直接收集 HAR 便成了最佳的選擇。
但想要收集 HAR 會遇到一些限制,比如這類數據只在 chrome devtools API 中開放,所以要實現這塊數據的收集,必須采用類似 chrome 插件的形式進行開發,但這樣一來,如何進行用戶無感知的數據收集與上報又成了一個難題。
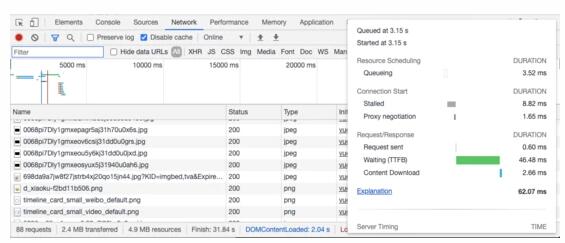
利用 chrome.webRequest API 可以允許我們觀察和分析流量,并在運行中攔截、阻止或修改它。從上文描述來看,要收集 HAR 只能通過這個 API 來實現,下面給出一個調用 network 對請求攔截處理的示例,詳細用法可參照文檔 https://developer.chrome.com/extensions/webRequest
chrome.devtools.network.onRequestFinished.addListener(function (req) { // Only collect Resource when XHR option is enabled if (document.getElementById('check-xhr').checked) { console.log('Resource Collector pushed: ', req.request.url); req.getContent(function (body, encoding) { if (!body) { console.log('No Content Detected!, Resource Collector will ignore: ', req.request.url); } else { reqs[req.request.url] = { body, encoding }; } setResourceCount(); }); setResourceCount(); } });我們都知道 Servcie Worker 的 cache API 在 PWA 應用中廣泛使用,但其實除了可以將其用于離線應用體驗增強外,由于 Servcie Worker 擁有更精細、更完整的控制特性,它完全可以作為一個頁面與服務器之間的代理中間層,用于捕獲它所負責的頁面請求,并返回相應資源。
一般來說,基于框架 HTTPClient (Angular) 或者原生 XMLHttpRequest 的監聽,對頁面的請求攔截都或多或少存在一些無法捕獲的盲區,但 Service Worker 不會,你所需要注意的是需要將它放在你的應用根目錄下,或者通過入參在注冊時指定 scope 以使你的 Service Worker 在指定范圍內生效。
關于它,除了理解其生命周期外,還有些細節需要注意,比如作用域 scope。單個 Service Worker 可以控制多個頁面,每個頁面不會有自己獨有的 worker,所以請注意 scope 的生效范圍;在你 scope 范圍內的頁面在加載完時,Service Worker 便可以開始控制它,所以請小心定義 Service Worker 腳本里的全局變量。
當然,為了方便開發,你可以使用 TypeScript、Babel、webpack 等語言和工具,來加速你的開發體驗。MDN 有一篇教程對 Service Worker 入門介紹的挺詳細,可以一看 https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API/Using_Service_Workers

上圖為 Service Worker 的生命周期
Web Worker 的作用,就是為 JavaScript 創造多線程環境,允許主線程創建 Worker 線程,將一些任務分配給后者運行。在主線程運行的同時,Worker 線程在后臺運行,兩者互不干擾。等到 Worker 線程完成計算任務,再把結果返回給主線程。這樣的好處是,一些計算密集型或高延遲的任務,被 Worker 線程負擔了,主線程(通常負責 UI 交互)就會很流暢,不會被阻塞或拖慢。—— 阮一峰的網絡日志
用于收集數據上報的計算工作,由于重計算邏輯且需要頻繁做數據處理,最好不要在主線程操作,否則很影響交互體驗。Web Worker 是一個很好的解決方案,在采用它之后,其余涉及到 BOM/DOM 的相關操作還可以將需要的數據直接事件傳遞通知或者 SharedArrayBuffer 共享。
那么,如何構建一個 Web Worker 呢?一個 worker 文件由簡單的 JavaScript 代碼組成,在寫完之后,你需要在主線程中傳入 URI 來構建這么一個 worker 線程,如下圖所示:
const myWorker = new Worker('worker.js');在 worker 中,除了完善用于計算的邏輯代碼外,我們還可以引入腳本、通過 postMessage 與主線程通信等等:
// 引入腳本 importScripts('foo.js', 'bar.js'); // 在 Web Worker 中監聽消息與向外通信 onmessage = function(e) { console.log('Message received from main script'); var workerResult = 'Result: ' + (e.data[0] * e.data[1]); console.log('Posting message back to main script'); postMessage(workerResult); }上面提到的 Service Worker 也可以算作 Web Worker 的一個相似品,但與一般的 Web Worker 不同,Service Worker 有一些額外的特性來實現代理的目的。只要它們被安裝且被激活,Service Worker 就可以攔截主線程中發起的任何網絡請求。
此外,還有一個特別的 Worker 叫做 Worklet,這些 API 都挺有意思,值得另開篇幅介紹,但與本文暫不相關,便不詳述。
window.requestIdleCallback() 方法將在瀏覽器的空閑時段內調用的函數排隊。這使開發者能夠在主事件循環上執行后臺和低優先級工作,而不會影響延遲關鍵事件,如動畫和輸入響應。函數一般會按先進先調用的順序執行,然而,如果回調函數指定了執行超時時間 timeout,則有可能為了在超時前執行函數而打亂執行順序。 —— MDN
由于系統需要對用戶數據進行全量收集,除了計算邏輯的負擔分攤外,包含序列化節點、快照等結構數據的上傳勢必又會成為項目潛在的瓶頸與需要考慮的優化點。利用 requestIdleCallback API,我們可以保證數據在處理后的上報(網絡請求)不對用戶交互造成影響,例如使用戶頁面卡頓等。
更為人熟知的一個 Web API 是 requestAnimationFrame,這個 API 可以告訴瀏覽器在下次重繪之前執行傳入的回調函數,由于是每幀執行一次,所以其每秒的執行次數與瀏覽器屏幕刷新次數一致,通常是每秒60次。而 requestIdleCallback 與其相反,它會在每幀的最后執行,但并不是每一幀都保證會執行 requestIdleCallback。這個原因很簡單,我們無法保證每一幀結束時我們還有時間,所以并不能保證 requestIdleCallback 的執行時間。
requestIdleCallback API 的設計很簡單,一個空閑調度函數,一個可選配置項參數。
const handle = window.requestIdleCallback(callback[, options])
舉個例子,假設我們現在需要追蹤用戶的點擊事件,并將數據上報服務器,利用這個 API 我們可以這樣完成數據收集以及上報調度:
const btns = btns.forEach(btn => btn.addEventListener('click', e => { // 其他交互 putIntoQueue({ type: 'click' // 收集數據 })); schedule(); }); function schedule() { requestIdleCallback( deadline => { while (deadline > 0) { const event = queues.pop(); send(event); } }, { timeout: 1000 } ); }既然要上報,那么就要考慮在數據未完成上報時用戶的意外退出或者網絡斷開等。在這些情況下,瀏覽器的本地存儲方案便派上了用場。由于需要保證數據上報的完整性,持久化存儲推薦 localStorage API 以及 IndexedDB API。
利用 localStorage API,我們可以快速的存取字符串形式的鍵值對,但受瀏覽器限制,存儲大小一般有限,僅幾兆而已。
利用 IndexedDB API,我們可以在客戶端存儲大量的結構化數據(也包括文件/二進制大型對象等),IndexedDB 被瀏覽器存在本地磁盤中,于是,你可以將其存儲上限近似看成計算機的剩余存儲容量。
IndexedDB 是一個事務型數據庫系統,類似于基于 SQL 的 RDBMS。 然而,不像 RDBMS 使用固定列表,IndexedDB 是一個基于 JavaScript 的面向對象數據庫。IndexedDB 允許您存儲和檢索用鍵索引的對象;可以存儲結構化克隆算法支持的任何對象。您只需要指定數據庫模式,打開與數據庫的連接,然后檢索和更新一系列事務。
localStorage 與 IndexedDB 的使用都相對容易,MDN 上有較為完善的入門指導,此處便不貼代碼了。
假設我們不使用 iframe 來做便捷沙箱環境,那么一個更強大的解決方案便是 puppeteer。
puppeteer 是谷歌官方出品的一個通過 DevTools 協議控制 headless Chrome 的 Node 庫,我們可以通過 puppeteer 提供的 API 直接控制 Chrome,進而模擬大部分用戶在瀏覽器上的操作,來進行 UI Test 或者作為爬蟲訪問頁面來收集數據。有關 puppeteer 的使用可以參考文檔 https://pptr.dev/
回到我們的場景,當需要重演用戶的操作時,我們可以便捷的利用 page API 來做,比如下面這個例子:
const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch() const page = await browser.newPage() await page.goto('https://hijiangtao.github.io/') await page.setViewport({ width: 2510, height: 1306 }) await page.waitForSelector('.ant-tabs-nav-wrap > .ant-tabs-nav-scroll > .ant-tabs-nav > div') await page.click('.ant-tabs-nav-wrap > .ant-tabs-nav-scroll > .ant-tabs-nav > div > .ant-tabs-tab:nth-child(2)') await page.waitForSelector('.ant-tabs-nav-wrap > .container') await page.click('.ant-tabs-nav-wrap > .ant-tabs-nav-scroll > .ant-tabs-nav > div > .ant-tabs-tab:nth-child(1)') await browser.close() })()當然,puppeteer 存在廣泛的使用場景,比如生成頁面截圖或者 PDF、進行自動化 UI 測試、構建爬蟲系統、捕獲頁面時間軸進行性能診斷等等
到此,相信大家對“怎么實現一個前端監控回放系統”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





