溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python爬蟲的技巧有哪些”,在日常操作中,相信很多人在Python爬蟲的技巧有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python爬蟲的技巧有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
1. 基本抓取網頁
get方法
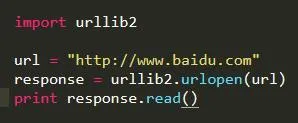
post方法
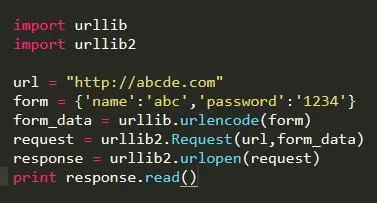
2. 使用代理IP
在開發爬蟲過程中經常會遇到IP被封掉的情況,這時就需要用到代理IP;
在urllib2包中有ProxyHandler類,通過此類可以設置代理訪問網頁,如下代碼片段:
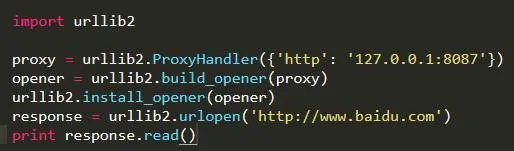
3. Cookies處理
cookies是某些網站為了辨別用戶身份、進行session跟蹤而儲存在用戶本地終端上的數據(通常經過加密),python提供了cookielib模塊用于處理cookies,cookielib模塊的主要作用是提供可存儲cookie的對象,以便于與urllib2模塊配合使用來訪問Internet資源。
代碼片段:
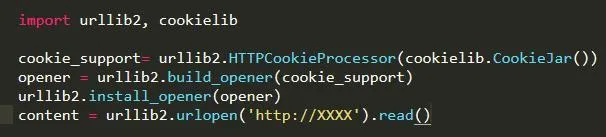
關鍵在于CookieJar(),它用于管理HTTP cookie值、存儲HTTP請求生成的cookie、向傳出的HTTP請求添加cookie的對象。整個cookie都存儲在內存中,對CookieJar實例進行垃圾回收后cookie也將丟失,所有過程都不需要單獨去操作。
手動添加cookie:

4. 偽裝成瀏覽器
某些網站反感爬蟲的到訪,于是對爬蟲一律拒絕請求。所以用urllib2直接訪問網站經常會出現HTTP Error 403: Forbidden的情況。
對有些 header 要特別留意,Server 端會針對這些 header 做檢查:
User-Agent 有些 Server 或 Proxy 會檢查該值,用來判斷是否是瀏覽器發起的 Request。
Content-Type 在使用 REST 接口時,Server 會檢查該值,用來確定 HTTP Body 中的內容該怎樣解析。
這時可以通過修改http包中的header來實現,代碼片段如下:
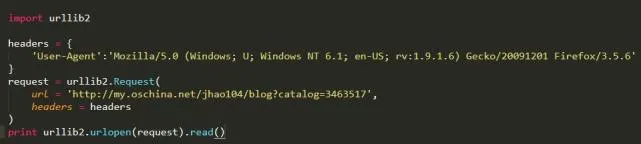
5. 驗證碼的處理
對于一些簡單的驗證碼,可以進行簡單的識別。我們只進行過一些簡單的驗證碼識別,但是有些反人類的驗證碼,比如12306,可以通過打碼平臺進行人工打碼,當然這是要付費的。
6. gzip壓縮
有沒有遇到過某些網頁,不論怎么轉碼都是一團亂碼。哈哈,那說明你還不知道許多web服務具有發送壓縮數據的能力,這可以將網絡線路上傳輸的大量數據消減 60% 以上。這尤其適用于 XML web 服務,因為 XML 數據 的壓縮率可以很高。
但是一般服務器不會為你發送壓縮數據,除非你告訴服務器你可以處理壓縮數據。
于是需要這樣修改代碼:
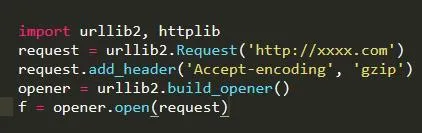
這是關鍵:創建Request對象,添加一個 Accept-encoding 頭信息告訴服務器你能接受 gzip 壓縮數據。
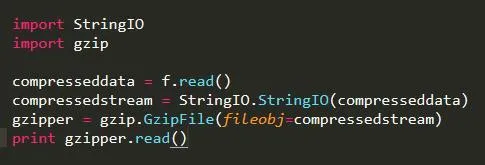
然后就是解壓縮數據:
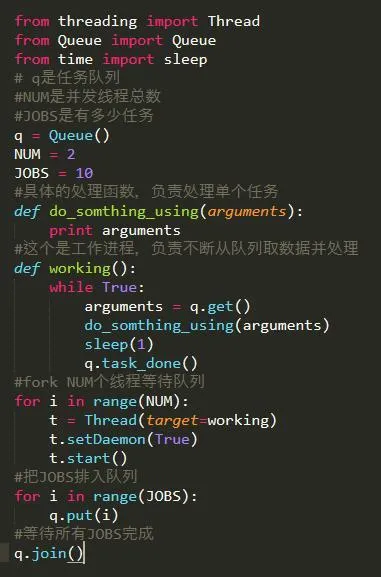
7. 多線程并發抓取
單線程太慢的話,就需要多線程了,這里給個簡單的線程池模板 這個程序只是簡單地打印了1-10,但是可以看出是并發的。
雖然說Python的多線程很雞肋,但是對于爬蟲這種網絡頻繁型,還是能一定程度提高效率的。
到此,關于“Python爬蟲的技巧有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





