溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Linux 運維故障排查思路是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
有時候會遇到一些疑難雜癥,并且監控插件并不能一眼立馬發現問題的根源。這時候就需要登錄服務器進一步深入分析問題的根源。那么分析問題需要有一定的技術經驗積累,并且有些問題涉及到的領域非常廣,才能定位到問題。所以,分析問題和踩坑是非常鍛煉一個人的成長和提升自我能力。如果我們有一套好的分析工具,那將是事半功倍,能夠幫助大家快速定位問題,節省大家很多時間做更深入的事情。
主要介紹各種問題定位的工具以及會結合案例分析問題。
針對應用程序,我們通常關注的是內核CPU調度器功能和性能。
線程的狀態分析主要是分析線程的時間用在什么地方,而線程狀態的分類一般分為:
on-CPU:執行中,執行中的時間通常又分為用戶態時間user和系統態時間sys。
off-CPU:等待下一輪上CPU,或者等待I/O、鎖、換頁等等,其狀態可以細分為可執行、匿名換頁、睡眠、鎖、空閑等狀態。
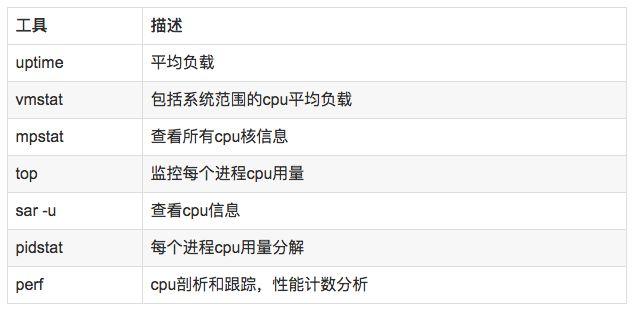
//查看系統cpu使用情況top //查看所有cpu核信息mpstat -P ALL 1 //查看cpu使用情況以及平均負載vmstat 1 //進程cpu的統計信息pidstat -u 1 -p pid //跟蹤進程內部函數級cpu使用情況 perf top -p pid -e cpu-clock
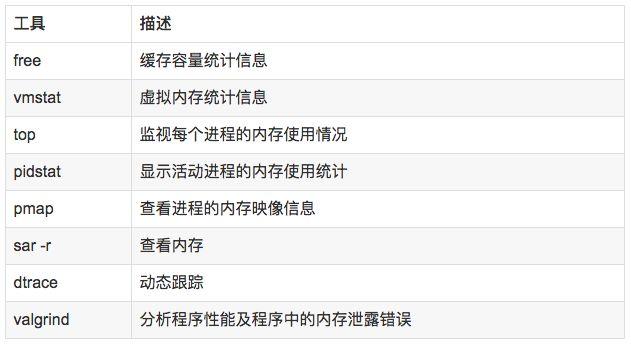
說明:
free,vmstat,top,pidstat,pmap只能統計內存信息以及進程的內存使用情況。
valgrind 可以分析內存泄漏問題。
dtrace 動態跟蹤。需要對內核函數有很深入的了解,通過D語言編寫腳本完成跟蹤。
//查看系統內存使用情況free -m //虛擬內存統計信息vmstat 1 //查看系統內存情況top //1s采集周期,獲取內存的統計信息pidstat -p pid -r 1 //查看進程的內存映像信息pmap -d pid //檢測程序內存問題valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
在理解磁盤IO之前,同樣我們需要理解一些概念,例如:
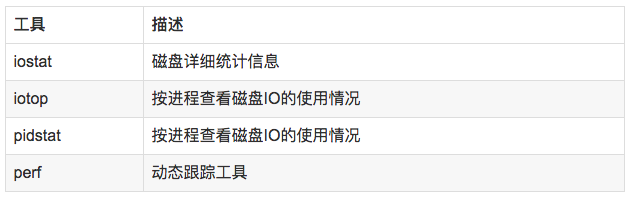
//查看系統io信息iotop //統計io詳細信息iostat -d -x -k 1 10 //查看進程級io的信息pidstat -d 1 -p pid //查看系統IO的請求,比如可以在發現系統IO異常時,可以使用該命令進行調查,就能指定到底是什么原因導致的IO異常perf record -e block:block_rq_issue -ag^Cperf report

//顯示網絡統計信息netstat -s //顯示當前UDP連接狀況netstat -nu //顯示UDP端口號的使用情況netstat -apu //統計機器中網絡連接各個狀態個數netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' //顯示TCP連接ss -t -a//顯示sockets摘要信息ss -s//顯示所有udp socketsss -u -a//tcp,etcp狀態sar -n TCP,ETCP 1 //查看網絡IOsar -n DEV 1//抓包以包為單位進行輸出tcpdump -i eth2 host 192.168.1.1 and port 80 //抓包以流為單位顯示數據內容tcpflow -cp host 192.168.1.1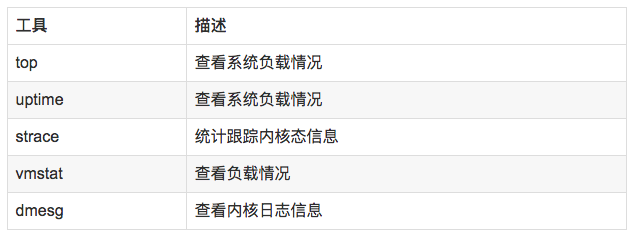
//查看負載情況uptimetopvmstat //統計系統調用耗時情況strace -c -p pid //跟蹤指定的系統操作例如epoll_waitstrace -T -e epoll_wait -p pid //查看內核日志信息dmesg
常見的火焰圖類型有 On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
//安裝systemtap,默認系統已安裝yum install systemtap systemtap-runtime //內核調試庫必須跟內核版本對應,例如:uname -r 2.6.18-308.el5kernel-debuginfo-2.6.18-308.el5.x86_64.rpmkernel-devel-2.6.18-308.el5.x86_64.rpmkernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm //安裝內核調試庫debuginfo-install --enablerepo=debuginfo search kerneldebuginfo-install --enablerepo=debuginfo search glibc
git clone https://github.com/lidaohang/quick_location.gitcd quick_location
cpu占用過高,或者使用率提不上來,你能快速定位到代碼的哪塊有問題嗎?
一般的做法可能就是通過日志等方式去確定問題。現在我們有了火焰圖,能夠非常清晰的發現哪個函數占用cpu過高,或者過低導致的問題。
//on-CPU usersh ngx_on_cpu_u.sh pid //進入結果目錄 cd ngx_on_cpu_u //on-CPU kernelsh ngx_on_cpu_k.sh pid //進入結果目錄 cd ngx_on_cpu_k //開一個臨時端口 8088 python -m SimpleHTTPServer 8088//打開瀏覽器輸入地址127.0.0.1:8088/pid.svg
DEMO:
#include <stdio.h> #include <stdlib.h> void foo3() { } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3(); } void foo1() { int i; for(i = 0; i< 1000; i++) foo3(); } int main(void) { int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); } }DEMO火焰圖:

cpu過低,利用率不高。等待下一輪CPU,或者等待I/O、鎖、換頁等等,其狀態可以細分為可執行、匿名換頁、睡眠、鎖、空閑等狀態。
使用方式:
// off-CPU usersh ngx_off_cpu_u.sh pid //進入結果目錄cd ngx_off_cpu_u //off-CPU kernelsh ngx_off_cpu_k.sh pid //進入結果目錄cd ngx_off_cpu_k //開一個臨時端口8088python -m SimpleHTTPServer 8088 //打開瀏覽器輸入地址127.0.0.1:8088/pid.svg
官網DEMO:
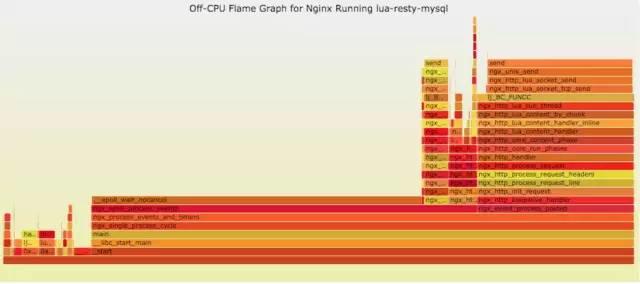
如果線上程序出現了內存泄漏,并且只在特定的場景才會出現。這個時候我們怎么辦呢?有什么好的方式和工具能快速的發現代碼的問題呢?同樣內存級別火焰圖幫你快速分析問題的根源。
使用方式:
sh ngx_on_memory.sh pid //進入結果目錄cd ngx_on_memory //開一個臨時端口8088python -m SimpleHTTPServer 8088 //打開瀏覽器輸入地址127.0.0.1:8088/pid.svg
官網DEMO:
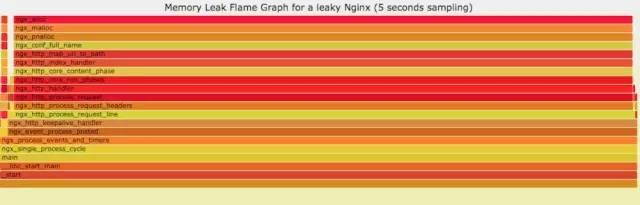
你能快速定位CPU性能回退的問題么?如果你的工作環境非常復雜且變化快速,那么使用現有的工具是來定位這類問題是很具有挑戰性的。當你花掉數周時間把根因找到時,代碼已經又變更了好幾輪,新的性能問題又冒了出來。主要可以用到每次構建中,每次上線做對比看,如果損失嚴重可以立馬解決修復。
通過抓取了兩張普通的火焰圖,然后進行對比,并對差異部分進行標色:紅色表示上升,藍色表示下降。差分火焰圖是以當前(“修改后”)的profile文件作為基準,形狀和大小都保持不變。因此你通過色彩的差異就能夠很直觀的找到差異部分,且可以看出為什么會有這樣的差異。
使用方式:
cd quick_location //抓取代碼修改前的profile 1文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks1 //抓取代碼修改后的profile 2文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks2 //生成差分火焰圖:./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
//test.c #include <stdio.h> #include <stdlib.h> void foo3() { } void foo2() { int i; for(i=0 ; i < 10; i++) foo3(); } void foo1() { int i; for(i = 0; i< 1000; i++) foo3(); } int main(void) { int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); } } //test1.c #include <stdio.h> #include <stdlib.h> void foo3() { } void foo2() { int i; for(i=0 ; i < 10; i++) foo3(); } void foo1() { int i; for(i = 0; i< 1000; i++) foo3(); } void add() { int i; for(i = 0; i< 10000; i++) foo3(); } int main(void) { int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); add(); } }DEMO紅藍差分火焰圖:

a) **分析nginx請求流量:
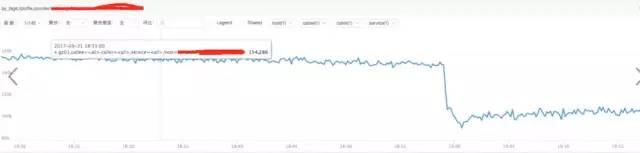
結論:
通過上圖發現流量并沒有突增,反而下降了,跟請求流量突增沒關系。
b) **分析nginx響應時間
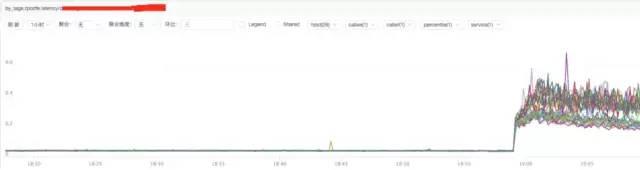
結論:
通過上圖發現nginx的響應時間有增加可能跟nginx自身有關系或者跟后端upstream響應時間有關系。
c) **分析nginx upstream響應時間
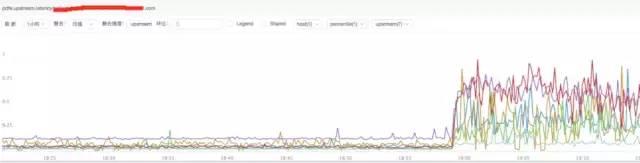
結論:
通過上圖發現nginx upstream 響應時間有增加,目前猜測可能后端upstream響應時間拖住nginx,導致nginx出現請求流量異常。
a) **通過top觀察系統指標
top
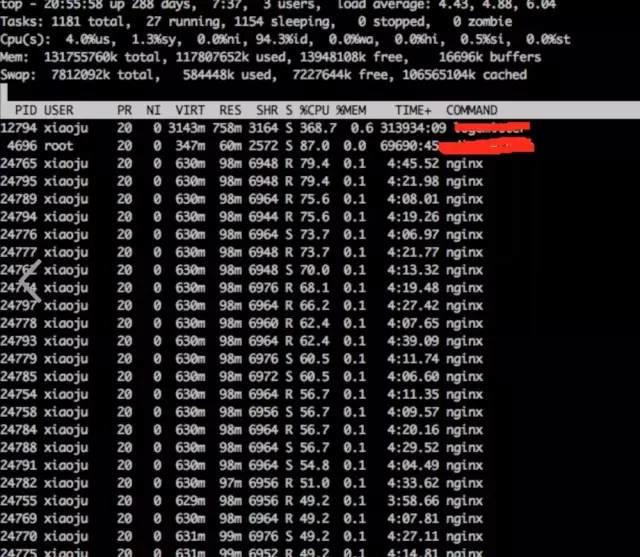
結論:
發現nginx worker cpu比較高
b) **分析nginx進程內部cpu情況
perf top -p pid
結論:
發現主要開銷在free,malloc,json解析上面
10.4 火焰圖分析cpu
a) **生成用戶態cpu火焰圖
//on-CPU usersh ngx_on_cpu_u.sh pid
//進入結果目錄cd ngx_on_cpu_u
//開一個臨時端口8088python -m SimpleHTTPServer 8088
//打開瀏覽器輸入地址127.0.0.1:8088/pid.svg
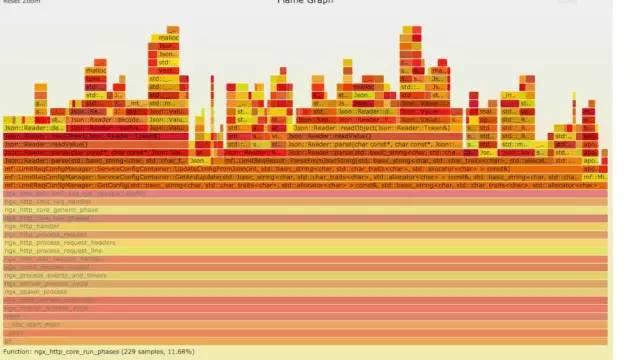
結論:
發現代碼里面有頻繁的解析json操作,并且發現這個json庫性能不高,占用cpu挺高。
a) 分析請求流量異常,得出nginx upstream后端機器響應時間拉長
b) 分析nginx進程cpu高,得出nginx內部模塊代碼有耗時的json解析以及內存分配回收操作
根據以上兩點問題分析的結論,我們進一步深入分析。
后端upstream響應拉長,最多可能影響nginx的處理能力。但是不可能會影響nginx內部模塊占用過多的cpu操作。并且當時占用cpu高的模塊,是在請求的時候才會走的邏輯。不太可能是upstram后端拖住nginx,從而觸發這個cpu的耗時操作。
遇到這種問題,我們優先解決已知的,并且非常明確的問題。那就是cpu高的問題。解決方式先降級關閉占用cpu過高的模塊,然后進行觀察。經過降級關閉該模塊cpu降下來了,并且nginx請求流量也正常了。之所以會影響upstream時間拉長,因為upstream后端的服務調用的接口可能是個環路再次走回到nginx。
上述內容就是Linux 運維故障排查思路是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





