溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何理解Java中的語法糖”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
語法糖
在聊之前我們需要先了解一下 語法糖 的概念:語法糖(Syntactic sugar),也叫做糖衣語法,是英國科學家發明的一個術語,通常來說使用語法糖能夠增加程序的可讀性,從而減少程序代碼出錯的機會,真是又香又甜。
語法糖指的是計算機語言中添加的某種語法,這種語法對語言的功能并沒有影響,但是更方便程序員使用。因為 Java 代碼需要運行在 JVM 中,JVM 是并不支持語法糖的,語法糖在程序編譯階段就會被還原成簡單的基礎語法結構,這個過程就是解語法糖。所以在 Java 中,真正支持語法糖的是 Java 編譯器,真是換湯不換藥,萬變不離其宗,關了燈都一樣。。。。。。
下面我們就來認識一下 Java 中的這些語法糖
泛型
泛型是一種語法糖。在 JDK1.5 中,引入了泛型機制,但是泛型機制的本身是通過類型擦除 來實現的,在 JVM 中沒有泛型,只有普通類型和普通方法,泛型類的類型參數,在編譯時都會被擦除。泛型并沒有自己獨特的 Class類型。如下代碼所示
List<Integer> aList = new ArrayList(); List<String> bList = new ArrayList(); System.out.println(aList.getClass() == bList.getClass());
List 和 List 被認為是不同的類型,但是輸出卻得到了相同的結果,這是因為,泛型信息只存在于代碼編譯階段,在進入 JVM 之前,與泛型相關的信息會被擦除掉,專業術語叫做類型擦除。但是,如果將一個 Integer 類型的數據放入到 List 中或者將一個 String 類型的數據放在 List 中是不允許的。
如下圖所示
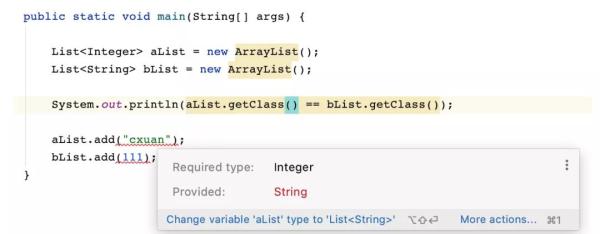
無法將一個 Integer 類型的數據放在 List 和無法將一個 String 類型的數據放在 List 中是一樣會編譯失敗。
自動拆箱和自動裝箱
自動拆箱和自動裝箱是一種語法糖,它說的是八種基本數據類型的包裝類和其基本數據類型之間的自動轉換。簡單的說,裝箱就是自動將基本數據類型轉換為包裝器類型;拆箱就是自動將包裝器類型轉換為基本數據類型。
我們先來了解一下基本數據類型的包裝類都有哪些
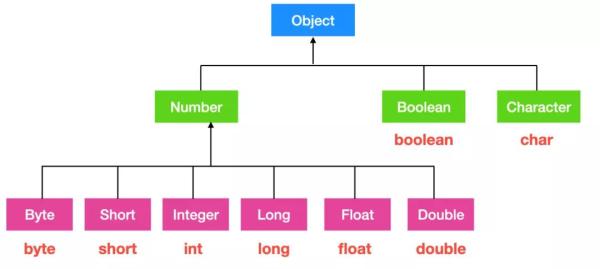
也就是說,上面這些基本數據類型和包裝類在進行轉換的過程中會發生自動裝箱/拆箱,例如下面代碼
Integer integer = 66; // 自動拆箱 int i1 = integer; // 自動裝箱
上面代碼中的 integer 對象會使用基本數據類型來進行賦值,而基本數據類型 i1 卻把它賦值給了一個對象類型,一般情況下是不能這樣操作的,但是編譯器卻允許我們這么做,這其實就是一種語法糖。這種語法糖使我們方便我們進行數值運算,如果沒有語法糖,在進行數值運算時,你需要先將對象轉換成基本數據類型,基本數據類型同時也需要轉換成包裝類型才能使用其內置的方法,無疑增加了代碼冗余。
那么自動拆箱和自動裝箱是如何實現的呢?
其實這背后的原理是編譯器做了優化。將基本類型賦值給包裝類其實是調用了包裝類的 valueOf() 方法創建了一個包裝類再賦值給了基本類型。
int i1 = Integer.valueOf(1);
而包裝類賦值給基本類型就是調用了包裝類的 xxxValue() 方法拿到基本數據類型后再進行賦值。
Integer i1 = new Integer(1).intValue();
我們使用 javap -c 反編譯一下上面的自動裝箱和自動拆箱來驗證一下
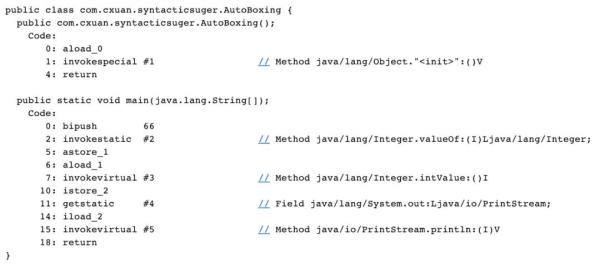
可以看到,在 Code 2 處調用 invokestatic 的時候,相當于是編譯器自動為我們添加了一下 Integer.valueOf 方法從而把基本數據類型轉換為了包裝類型。
在 Code 7 處調用了 invokevirtual 的時候,相當于是編譯器為我們添加了 Integer.intValue() 方法把 Integer 的值轉換為了基本數據類型。
枚舉
我們在日常開發中經常會使用到 enum 和 public static final ... 這類語法。那么什么時候用 enum 或者是 public static final 這類常量呢?好像都可以。
但是在 Java 字節碼結構中,并沒有枚舉類型。枚舉只是一個語法糖,在編譯完成后就會被編譯成一個普通的類,也是用 Class 修飾。這個類繼承于 java.lang.Enum,并被 final 關鍵字修飾。
我們舉個例子來看一下
public enum School { STUDENT, TEACHER; }這是一個 School 的枚舉,里面包括兩個字段,一個是 STUDENT ,一個是 TEACHER,除此之外并無其他。
下面我們使用 javap 反編譯一下這個 School.class 。反編譯完成之后的結果如下

從圖中我們可以看到,枚舉其實就是一個繼承于 java.lang.Enum 類的 class 。而里面的屬性 STUDENT 和 TEACHER 本質也就是 public static final 修飾的字段。這其實也是一種編譯器的優化,畢竟 STUDENT 要比 public static final School STUDENT 的美觀性、簡潔性都要好很多。
除此之外,編譯器還會為我們生成兩個方法,values() 方法和 valueOf 方法,這兩個方法都是編譯器為我們添加的方法,通過使用 values() 方法可以獲取所有的 Enum 屬性值,而通過 valueOf 方法用于獲取單個的屬性值。
注意,Enum 的 values() 方法不屬于 JDK API 的一部分,在 Java 源碼中,沒有 values() 方法的相關注釋。
用法如下
public enum School { STUDENT("Student"), TEACHER("Teacher"); private String name; School(String name){ this.name = name; } public String getName() { return name; } public static void main(String[] args) { System.out.println(School.STUDENT.getName()); School[] values = School.values(); for(School school : values){ System.out.println("name = "+ school.getName()); } } }內部類
內部類是 Java 一個小眾 的特性,我之所以說小眾,并不是說內部類沒有用,而是我們日常開發中其實很少用到,但是翻看 JDK 源碼,發現很多源碼中都有內部類的構造。比如常見的 ArrayList 源碼中就有一個 Itr 內部類繼承于 Iterator 類;再比如 HashMap 中就構造了一個 Node 繼承于 Map.Entry 來表示 HashMap 的每一個節點。
Java 語言中之所以引入內部類,是因為有些時候一個類只想在一個類中有用,不想讓其在其他地方被使用,也就是對外隱藏內部細節。
內部類其實也是一個語法糖,因為其只是一個編譯時的概念,一旦編譯完成,編譯器就會為內部類生成一個單獨的class 文件,名為 outer$innter.class。
下面我們就根據一個示例來驗證一下。
public class OuterClass { private String label; class InnerClass { public String linkOuter(){ return label = "inner"; } } public static void main(String[] args) { OuterClass outerClass = new OuterClass(); InnerClass innerClass = outerClass.new InnerClass(); System.out.println(innerClass.linkOuter()); } }上面這段編譯后就會生成兩個 class 文件,一個是 OuterClass.class ,一個是 OuterClass$InnerClass.class ,這就表明,外部類可以鏈接到內部類,內部類可以修改外部類的屬性等。
我們來看一下內部類編譯后的結果
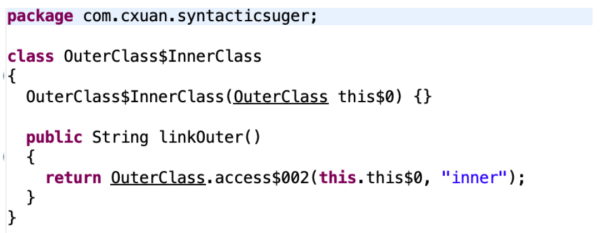
如上圖所示,內部類經過編譯后的 linkOuter() 方法會生成一個指向外部類的 this 引用,這個引用就是連接外部類和內部類的引用。
變長參數
變長參數也是一個比較小眾的用法,所謂變長參數,就是方法可以接受長度不定確定的參數。一般我們開發不會使用到變長參數,而且變長參數也不推薦使用,它會使我們的程序變的難以處理。但是我們有必要了解一下變長參數的特性。
其基本用法如下
public class VariableArgs { public static void printMessage(String... args){ for(String str : args){ System.out.println("str = " + str); } } public static void main(String[] args) { VariableArgs.printMessage("l","am","cxuan"); } }變長參數也是一種語法糖,那么它是如何實現的呢?我們可以猜測一下其內部應該是由數組構成,否則無法接受多個值,那么我們反編譯看一下是不是由數組實現的。

可以看到,printMessage() 的參數就是使用了一個數組來接收,所以千萬別被變長參數忽悠了!
變長參數特性是在 JDK 1.5 中引入的,使用變長參數有兩個條件,一是變長的那一部分參數具有相同的類型,二是變長參數必須位于方法參數列表的最后面。
增強 for 循環
為什么有了普通的 for 循環后,還要有增強 for 循環呢?想一下,普通 for 循環你不是需要知道遍歷次數?每次還需要知道數組的索引是多少,這種寫法明顯有些繁瑣。增強 for 循環與普通 for 循環相比,功能更強并且代碼更加簡潔,你無需知道遍歷的次數和數組的索引即可進行遍歷。
增強 for 循環的對象要么是一個數組,要么實現了 Iterable 接口。這個語法糖主要用來對數組或者集合進行遍歷,其在循環過程中不能改變集合的大小。
public static void main(String[] args) { String[] params = new String[]{"hello","world"}; //增強for循環對象為數組 for(String str : params){ System.out.println(str); } List<String> lists = Arrays.asList("hello","world"); //增強for循環對象實現Iterable接口 for(String str : lists){ System.out.println(str); } }經過編譯后的 class 文件如下
public static void main(String[] args) { String[] params = new String[]{"hello", "world"}; String[] lists = params; int var3 = params.length; //數組形式的增強for退化為普通for for(int str = 0; str < var3; ++str) { String str1 = lists[str]; System.out.println(str1); } List var6 = Arrays.asList(new String[]{"hello", "world"}); Iterator var7 = var6.iterator(); //實現Iterable接口的增強for使用iterator接口進行遍歷 while(var7.hasNext()) { String var8 = (String)var7.next(); System.out.println(var8); } }如上代碼所示,如果對數組進行增強 for 循環的話,其內部還是對數組進行遍歷,只不過語法糖把你忽悠了,讓你以一種更簡潔的方式編寫代碼。
而對繼承于 Iterator 迭代器進行增強 for 循環遍歷的話,相當于是調用了 Iterator 的 hasNext() 和 next() 方法。
Switch 支持字符串和枚舉
switch 關鍵字原生只能支持整數類型。如果 switch 后面是 String 類型的話,編譯器會將其轉換成 String 的hashCode 的值,所以其實 switch 語法比較的是 String 的 hashCode 。
如下代碼所示
public class SwitchCaseTest { public static void main(String[] args) { String str = "cxuan"; switch (str){ case "cuan": System.out.println("cuan"); break; case "xuan": System.out.println("xuan"); break; case "cxuan": System.out.println("cxuan"); break; default: break; } } }我們反編譯一下,看看我們的猜想是否正確
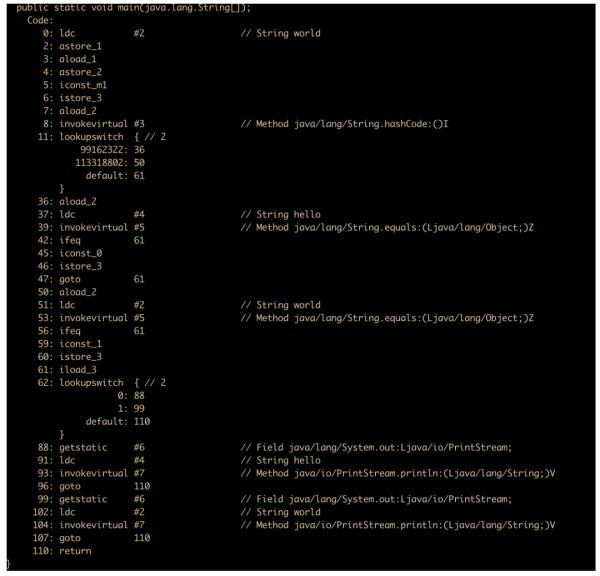
根據字節碼可以看到,進行 switch 的實際是 hashcode 進行判斷,然后通過使用 equals 方法進行比較,因為字符串有可能會產生哈希沖突的現象。
條件編譯
這個又是讓小伙伴們摸不著頭腦了,什么是條件編譯呢?其實,如果你用過 C 或者 C++ 你就知道可以通過預處理語句來實現條件編譯。
那么什么是條件編譯呢?
一般情況下,源程序中所有的行都參加編譯。但有時希望對其中一部分內容只在滿足一定條件下才進行編譯,即對一部分內容指定編譯條件,這就是 條件編譯(conditional compile)。
#define DEBUG #IFDEF DEBUUG /* code block 1 */ #ELSE /* code block 2 */ #ENDIF
但是在 Java 中沒有預處理和宏定義這些內容,那么我們想實現條件編譯,應該怎樣做呢?
使用 final + if 的組合就可以實現條件編譯了。如下代碼所示
public static void main(String[] args) { final boolean DEBUG = true; if (DEBUG) { System.out.println("Hello, world!"); } else { System.out.println("nothing"); } }這段代碼會發生什么?我們反編譯看一下

我們可以看到,我們明明是使用了 if …else 語句,但是編譯器卻只為我們編譯了 DEBUG = true 的條件,
所以,Java 語法的條件編譯,是通過判斷條件為常量的 if 語句實現的,編譯器不會為我們編譯分支為 false 的代碼。
斷言
你在 Java 中使用過斷言作為日常的判斷條件嗎?
斷言:也就是所謂的 assert 關鍵字,是 jdk 1.4 后加入的新功能。它主要使用在代碼開發和測試時期,用于對某些關鍵數據的判斷,如果這個關鍵數據不是你程序所預期的數據,程序就提出警告或退出。當軟件正式發布后,可以取消斷言部分的代碼。它也是一個語法糖嗎?現在我不告訴你,我們先來看一下 assert 如何使用。
//這個成員變量的值可以變,但最終必須還是回到原值5 static int i = 5; public static void main(String[] args) { assert i == 5; System.out.println("如果斷言正常,我就被打印"); }如果要開啟斷言檢查,則需要用開關 -enableassertions 或 -ea 來開啟。其實斷言的底層實現就是 if 判斷,如果斷言結果為 true,則什么都不做,程序繼續執行,如果斷言結果為 false,則程序拋出 AssertError 來打斷程序的執行。
assert 斷言就是通過對布爾標志位進行了一個 if 判斷。
try-with-resources
JDK 1.7 開始,java引入了 try-with-resources 聲明,將 try-catch-finally 簡化為 try-catch,這其實是一種語法糖,在編譯時會進行轉化為 try-catch-finally 語句。新的聲明包含三部分:try-with-resources 聲明、try 塊、catch 塊。它要求在 try-with-resources 聲明中定義的變量實現了 AutoCloseable 接口,這樣在系統可以自動調用它們的 close 方法,從而替代了 finally 中關閉資源的功能。
如下代碼所示
public class TryWithResourcesTest { public static void main(String[] args) { try(InputStream inputStream = new FileInputStream(new File("xxx"))) { inputStream.read(); }catch (Exception e){ e.printStackTrace(); } } }我們可以看一下 try-with-resources 反編譯之后的代碼

可以看到,生成的 try-with-resources 經過編譯后還是使用的 try…catch…finally 語句,只不過這部分工作由編譯器替我們做了,這樣能讓我們的代碼更加簡潔,從而消除樣板代碼。
字符串相加
這個想必大家應該都知道,字符串的拼接有兩種,如果能夠在編譯時期確定拼接的結果,那么使用 + 號連接的字符串會被編譯器直接優化為相加的結果,如果編譯期不能確定拼接的結果,底層會直接使用 StringBuilder 的 append 進行拼接,如下圖所示。
public class StringAppendTest { public static void main(String[] args) { String s1 = "I am " + "cxuan"; String s2 = "I am " + new String("cxuan"); String s3 = "I am "; String s4 = "cxuan"; String s5 = s3 + s4; } }上面這段代碼就包含了兩種字符串拼接的結果,我們反編譯看一下

首先來看一下 s1 ,s1 因為 = 號右邊是兩個常量,所以兩個字符串拼接會被直接優化成為 I am cxuan。而 s2 由于在堆空間中分配了一個 cxuan 對象,所以 + 號兩邊進行字符串拼接會直接轉換為 StringBuilder ,調用其 append 方法進行拼接,最后再調用 toString() 方法轉換成字符串。
而由于 s5 進行拼接的兩個對象在編譯期不能判定其拼接結果,所以會直接使用 StringBuilder 進行拼接。
學習語法糖的意義
互聯網時代,有很多標新立異的想法和框架層出不窮,但是,我們對于學習來說應該抓住技術的核心。然而,軟件工程是一門協作的藝術,對于工程來說如何提高工程質量,如何提高工程效率也是我們要關注的,既然這些語法糖能輔助我們以更好的方式編寫備受歡迎的代碼,我們程序員為什么要 抵制 呢?
語法糖也是一種進步,這就和你寫作文似的,大白話能把故事講明白的它就沒有語言優美、酣暢淋漓的把故事講生動的更令人喜歡。
“如何理解Java中的語法糖”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





