溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何從底層聊下IO多路復用模型”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何從底層聊下IO多路復用模型”吧!
當我們去面試的時候,問到了 redis,nginx,netty他們的底層模型分別是什么?
redis -> epoll
nginx-> epoll
netty-> epoll?
需要從操作系統的層面上來談
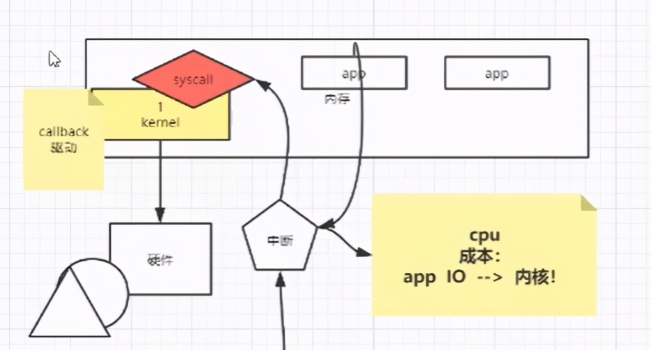
當我們開機的時候,首先被加載進內存的是我們的Kernel(內核),內核是用于管理我們的硬件的,同時內核還會創建一個GDT表,然后劃分兩個空間(用戶空間和內核空間),同時空間中的內容是開啟了保護模式,無法被修改的。
同時還有一個CPU的概念,CPU有自己的指令集,并且指令集是分了幾個級別的,分別是從0~3的,Kernel屬于0級別。APP只能用級別為3的指令集。
從上面我們可以知道,我們的應用程序是無法直接訪問我們的Kernel的,也就是程序不能直接訪問我們的磁盤,聲卡,網卡等設備,只有內核才可以訪問,那我們怎么辦?
只有APP通過調用Kernel提供的 syscall(系統軟中斷和硬中斷)來獲取硬件中的內容。
硬中斷:硬中斷指的是我們的鍵盤,按下一個按鍵的時候,就會觸發我們的硬中斷,也就是內核會有一個中斷號,然后得到一個callback的回調函數
說到這里,其實就是為了引出一個 概念,就是 IO 和 內核之間的成本問題
/** * 服務器讀取文件 * @author: 陌溪 * @create: 2020-07-01-20:40 */ public class TestSocket { public static void main(String[] args) throws IOException { ServerSocket server = new ServerSocket(8090); System.out.println("step1: new ServerSocket(8090)"); while(true) { Socket client = server.accept(); System.out.println("step2: client " + client.getPort()); new Thread(() -> { try { InputStream in = client.getInputStream(); BufferedReader reader = new BufferedReader(new InputStreamReader(in)); while(true) { System.out.println(reader.readLine()); } } catch (IOException e) { e.printStackTrace(); } }, "t1").start(); } } }
抓取程序對內核有沒有系統調用,然后輸出
strace -ff -o ./ooxx java TestSocket
然后我們執行上面的程序,得到我們的結果
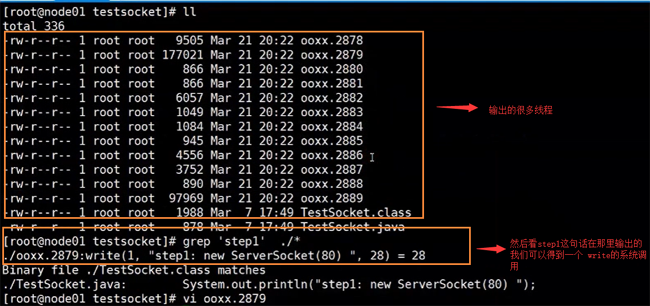
然后我們在通過jps命令,查看當前TestSocket的進程號
jps 2912 Jps 2878 TestSocket
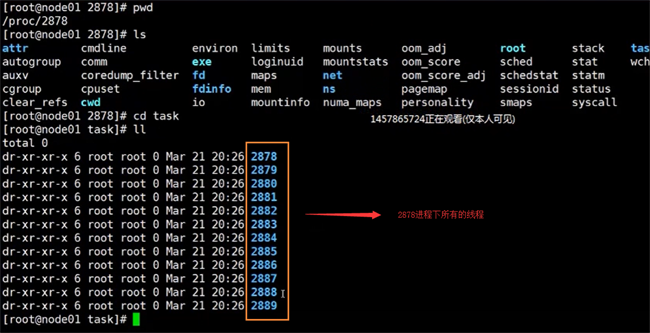
然后我們在進入下面的這個目錄下,啟動2878是線程的id號,這個目錄就是存放該線程的一些信息
cd /proc/2878
我們可以看到2878進程下的,通過查看task目錄,可以看到所有線程數
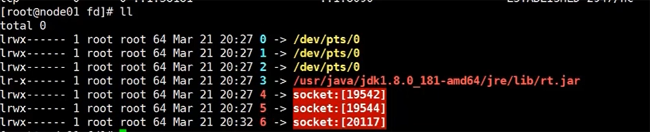
還有一個目錄,就是 fd目錄,在該目錄下,就是我們的一些IO流
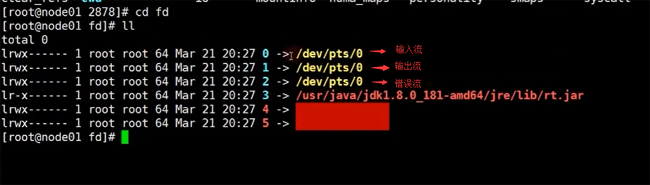
上面的0,1,2,分別對應著 輸入流,輸出流和錯誤流。在java里面我們流就是對象,而在linux系統中,流就是一個個的文件。后面的4,5 就對應著我們的socket通信,分別對應著ipv4 和 ipv6

通過netstat命令查看
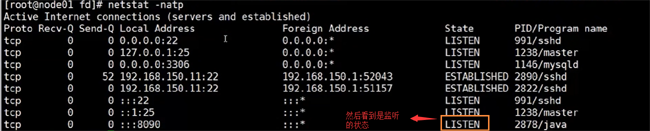
然后我們使用nc連接 8090端口
nc localhost 8090
我們執行完后,通過netstat命令查看 ,發現多了個連接的狀態
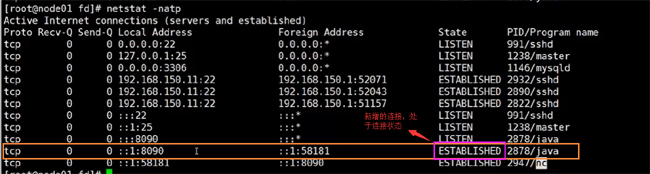
然后在看文件里面,也多了一個socket
我們查看系統調用,發現通過系統調用接收了一個58181端口號的請求,在前面我們還能夠看到5,這個5其實就是對應的上圖里面的socket,走的是ipv4。
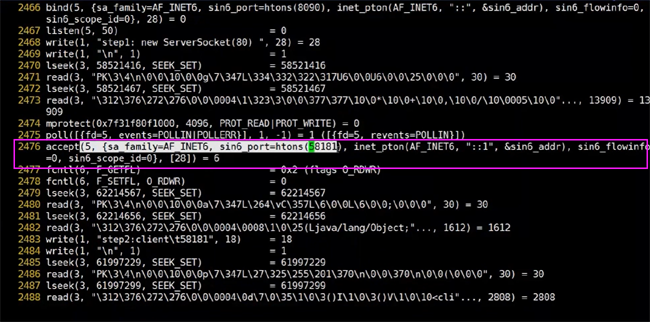
從這里其實我們就可以知道了,我們原來調用中寫的代碼
Socket client = server.accept();
對應到系統層面,也是調用了系統的方法。
同時關于系統調用,有以下幾種方式
bind
connect
listen
select
socket
首先我們需要知道,java其實是一種解釋型語言,通過JVM 虛擬機將我們的.java文件轉換為字節碼文件,然后調用我們os中的syscall方法,我們必須明確的是,無論怎么調用,一定最后要通過調用內核的方法,然后調用我們的硬件。
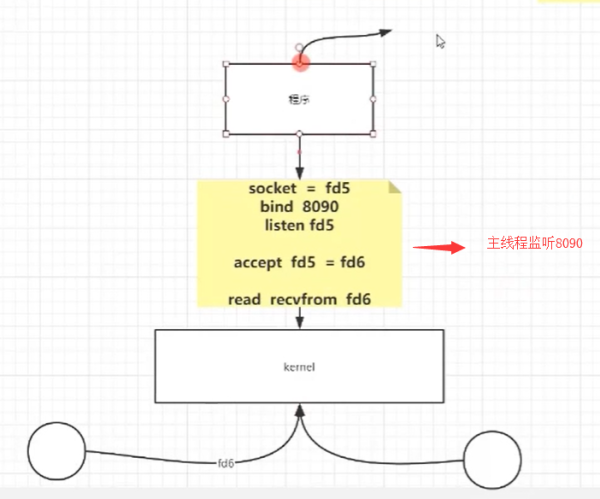
上述的模型,就是BIO的通信,是這里面有很多阻塞,我們只能夠通過多個線程來避免主線程的阻塞。但是從上面我們可以知道,如果有大量地連接過來,那服務器需要創建很多個線程與之對應,并且線程的創建也是需要消耗資源的,因為線程使用的棧是獨占的(棧大小默認1MB),同時CPU的資源調度也是需要浪費。
最根本的原因就是因為 BIO是阻塞的,才會造成上面的問題。
因為BIO存在線程阻塞的問題,后面就提出了NIO的概念,在NIO中,有C10K的問題,C10K = 10000個客戶端。但是在和你連接的服務器中,其實沒有多少給你發送數據了,所以我們需要做的就是,每當有人發送消息的時候,我才和它進行連接。
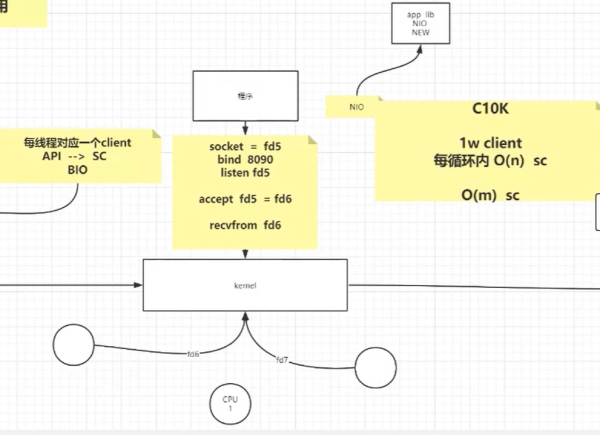
也就是每次都需要遍歷10000個客戶端,是非常耗費時間呢,因為很多客戶端可能就沒有請求的發送。
這個時候,我們就不需要遍歷10K個客戶端了,而是把我們的fds文件發送給內核,然后內核去判斷最后需要連接誒的客戶端,這樣就不用遍歷全部的了。所以這里的Select就是多路復用器,通過多路復用返回的是狀態,然后我們需要程序去判斷這些狀態。
說白了,就是通過一個多路復用器,來判斷哪些路可以走通,然后不需要輪詢全部的。
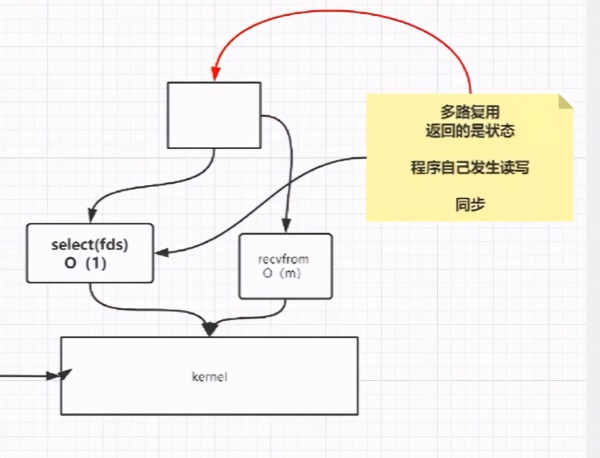
這個模型,是通過select,將fds文件交給內核來做了,也就是內核需要完成10K個文件的主動遍歷,這個10K個調用,對比之前的10K次系統調用來說,是更省時間的,存在以下的問題
每次傳遞很多數據(重復勞動)
然后內核需要主動去遍歷( 復雜度O(N) )
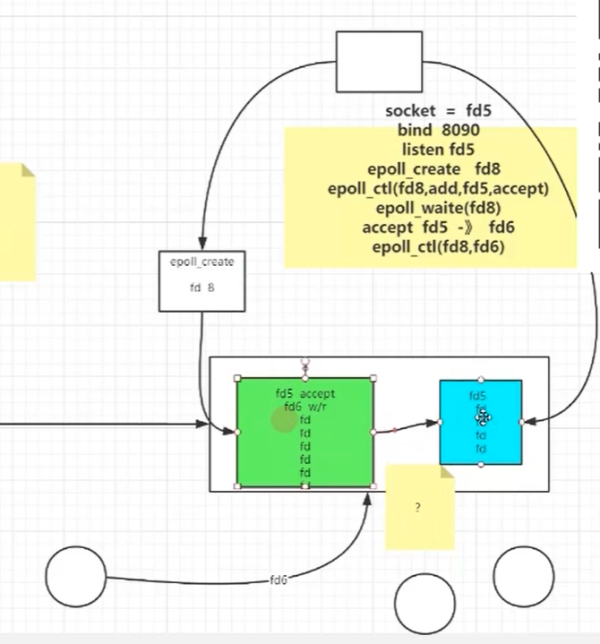
解決方法,通過在內核中,開辟一個空間,當每次來一個客戶端,就把這個文件丟到內核中,這樣不需要每次把10K個文件傳遞到內核了。然后在使用一個基于事件驅動的模型,如下圖所示就是一個異步事件驅動的流程
我們通過strace命令,查看nginx 和 redis的運行流程,能夠發現 同樣是使用了 epoll,但是nginx是阻塞的,而redis它是輪詢(非阻塞)的。
首先那是因為Redis只有一個線程,而這個線程要做很多事情,例如 接收客戶端,LRU,LFU(淘汰過濾)、RDB/AOF(fork線程進行數據備份)。
也就是說對于Redis中的C10K問題,redis也是通過epoll的事件驅動來進行處理的,也就是通過epoll將每個需要讀取的客戶端的操作放在一個原子串行化的隊列中,并且一個客戶端包含以下的幾個操作:read、計算、write等
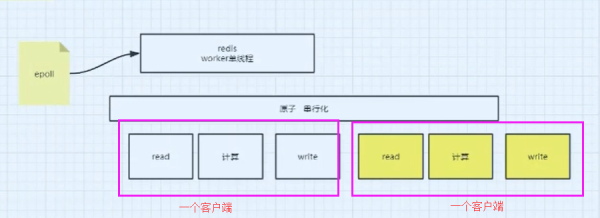
在redis 6.X版本中,還有一個IO threads的概念,首先它為了留住串行化原子性的特點,也就是計算的時候還是串行化的處理,但是在讀取數據的時候,使用的是多線程進行并發IO讀取。為什么要多線程讀呢?首先因為讀操作需要發生CPU的系統調用,如果通過多個線程讀取,能夠充分發揮CPU的多核作用
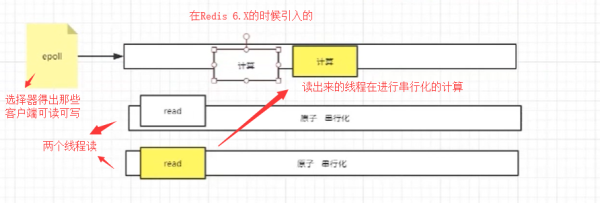
而nginx只需要做一件事,就是等著客戶端過來,不需要做其他的事情,所以也就設置成阻塞。
用kafka來講,首先這里面有兩個角色,一個是消息生產者,一個是消息消費者
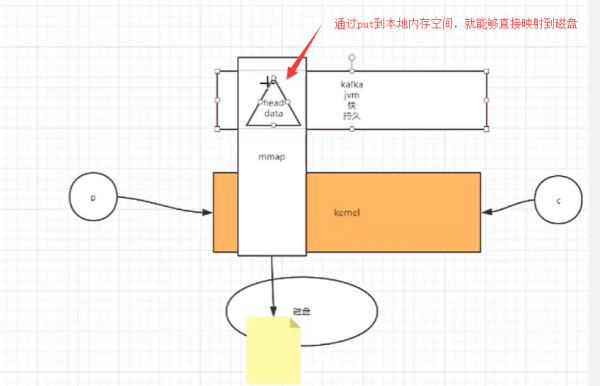
也就是說,我們通過開辟了一個內存空間,能夠直接抵達磁盤,能夠減少kernel的系統調用。在讀取的時候,如果是原來的做法,就需要首先請求kernel,然后kernel發起一個read請求,讀取磁盤的文件到內核中,然后kafka在讀取kernel中的信息。
那么什么是零拷貝呢?
零拷貝就是不發生拷貝的情況,零拷貝的前提就是數據不需要加工,在JVM中有一個RandomAccessFile,它能夠直接開辟一個堆內空間,或者堆外空間。
到此,相信大家對“如何從底層聊下IO多路復用模型”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





