溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
初因是給寶寶制作拼音卡點讀包時,要下載賣家提供給的MP3,大概有2百多個。作為一個會碼代碼的非專業人士,怎么可能取一個一個下載?所以就決定用python 的 scrapy 框架寫個爬蟲,去下載這些MP3。一開始以為簡單,直到完成下載,竟然花了我一下午的時間。最大的難題就是頁面的數據是通過javascript 腳本動態渲染的。百度上大部分方法都是通過splash 做中轉實現的方法,而我只是想簡單的寫個代碼實現而已,看splash還要掛docker,巴啦巴啦一大堆的操作,頓時就心塞了。通過百度和自己實踐,終于找到了一個最簡單的方法解決了問題,特此記錄下來,同大家分享一下。
先開始分析目標html
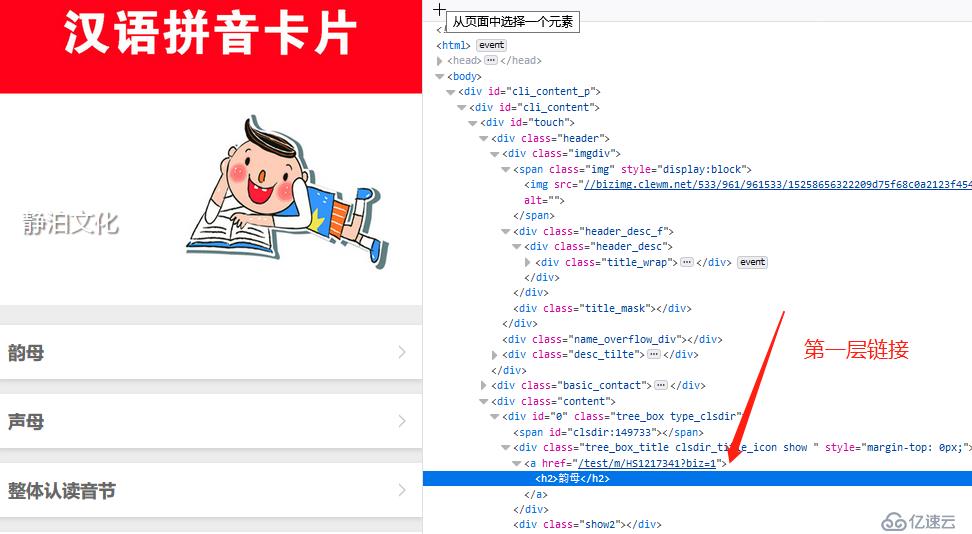
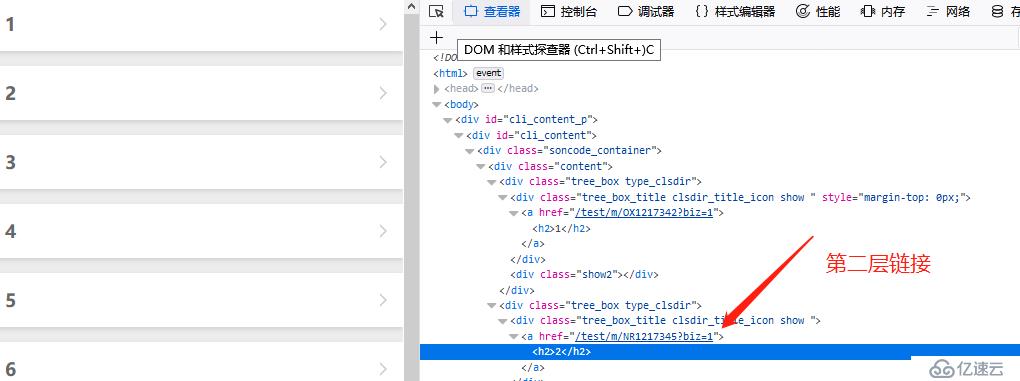
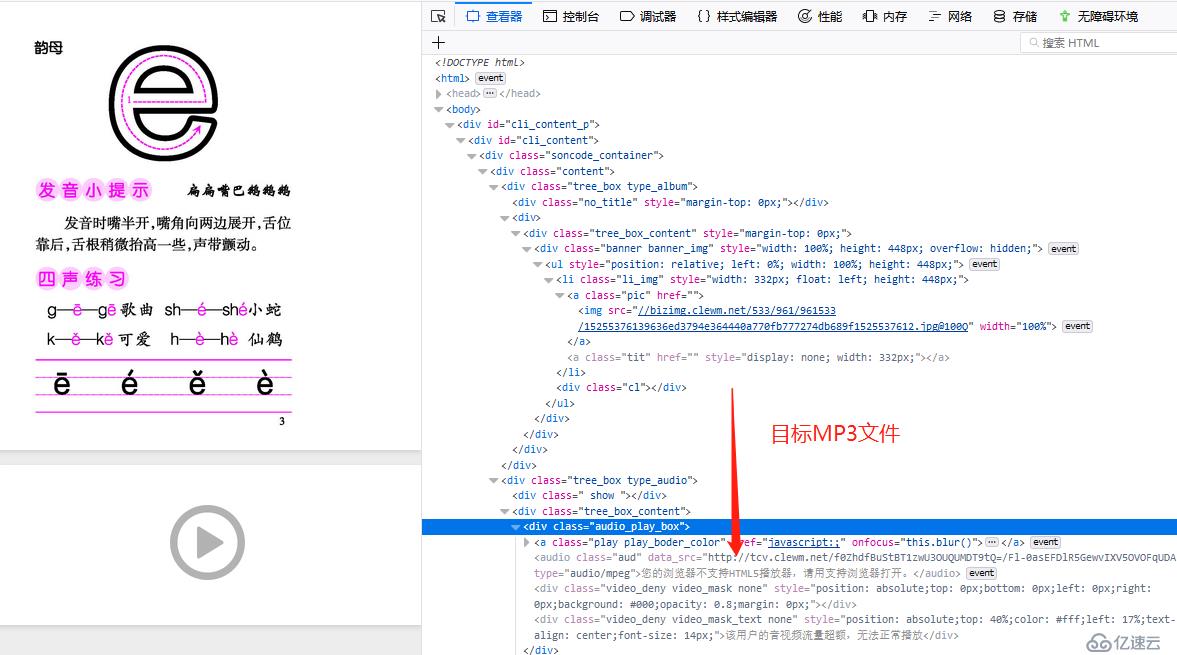
看著簡單吧,可一爬取,問題立馬就出現了,curl下靜態頁看看。
curl -s https://biz.cli.im/test/CI525711?stime=2 >111.html
首頁竟是這樣的,頁面的列表數據,是通過javascript 動態渲染的。

是個json 數據,再格式化后分析下,頁面link 都在data 這個json數據里了。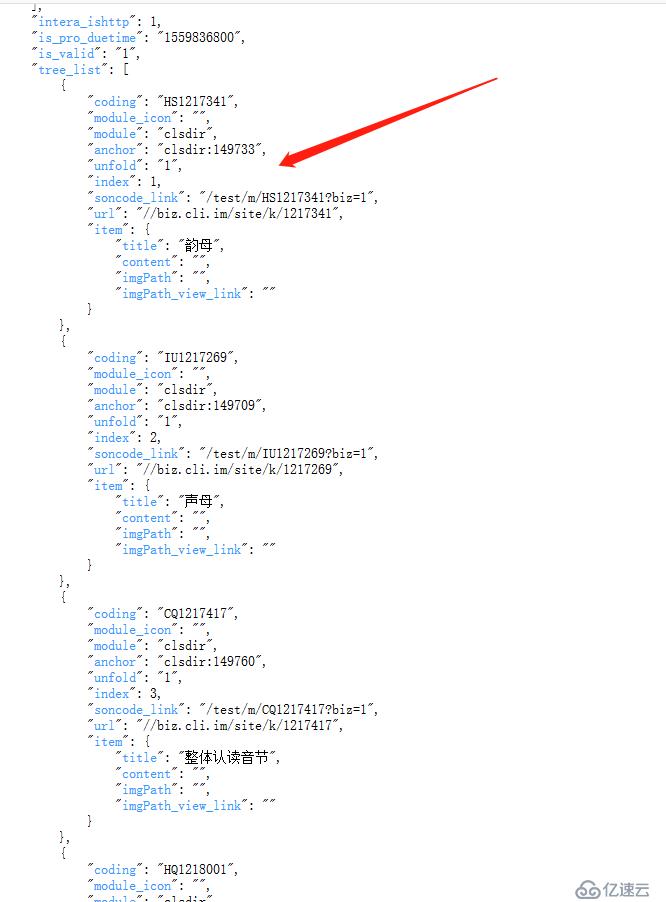
最基礎的response.xpath 方式是不能用了,我的思路是把scripts 獲取出來,然后用獲取soncode_link 的值。
經過研究決定用 BeautifulSoup + js2xml
class JingboSpider(scrapy.Spider):
name = 'jingbo'
allowed_domains = ['biz.cli.im']
all_urls= "https://biz.cli.im"
start_urls = ['test/CI525711?stime=2']
def start_requests(self):
#自定義headers
for url in self.start_urls:
yield scrapy.Request(self.all_urls+"/"+url, headers={"User-Agent": USER_AGENT})
def parse(self, response):
resp = response.text
# 用lxml作為解析器 ,解析返回數據
soup = BeautifulSoup(resp,'lxml')
# 獲取所有script 標簽數據,并遍歷查找
scripts = soup.find_all('script')
for script in scripts:
if type(script.string) is type(None):
continue
if script.string.find("loadtemp();") > 0:
src=script
break
title="title"
link="soncode_link"
# 將js 數據轉化為 xml 標簽樹格式
src_text = js2xml.parse(src.string, encoding='utf-8',debug=False)
src_tree = js2xml.pretty_print(src_text)
# print(src_tree)
selector = etree.HTML(src_tree)
links = selector.xpath("http://property[@name = '"+link+"']/string/text()")
playurl = selector.xpath("http://property[@name = 'play_url']/string/text()")
titles = selector.xpath("http://property[@name = '"+title+"']/string/text()")
#剩下就是循環獲取頁面,下載MP3文件了。
wget https://www.lfd.uci.edu/~gohlke/pythonlibs/Twisted?18.9.0?cp37?cp37m?win_amd64.whl
wget https://www.lfd.uci.edu/~gohlke/pythonlibs/beautifulsoup4?4.7.1?py3?none?any.whl
pip install Twisted?18.9.0?cp37?cp37m?win_amd64.whl
pip install pypiwin32 js2xml urllib2 Scrapy
scrapy startproject pinyin
scrapy genspider jingbo https://biz.cli.im/test/CI525711?stime=2
scrapy crawl jingbo

https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
https://www.cnblogs.com/zhaof/p/6930955.html
https://blog.csdn.net/qq_34246164/article/details/80700399
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





