溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Java 中有哪些集合框架,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1. 為什么要使用集合
當我們在學習一個東西的時候,最好是明白為什么要使用這個東西,不要為了用而用,知其然而知其所以然。
集合,故名思議,是用來存儲元素的,而數組也同樣具有這個功能,那么既然出現了集合,必然是因為「數組的使用存在一定的缺陷」。
上篇文章已經簡單提到過,數組一旦被定義,就無法再更改其存儲大小。舉個例子,假設有一個班級,現在有 50 個學生在這個班里,于是我們定義了一個能夠存儲 50 個學生信息的數組:
1)如果這個班里面來了 10 個轉班生,由于數組的長度固定不變,那么顯然這個數組的存儲能力無法支持 60 個學生;再比如,這個班里面有 20 個學生退學了,那么這個數組實際上只存了 30 個學生,造成了內存空間浪費。總結來說,「由于數組一旦被定義,就無法更改其長度,所以數組無法動態的適應元素數量的變化」。
2)數組擁有 length 屬性,可以通過這個屬性查到數組的存儲能力也就是數組的長度,但是無法通過一個屬性直接獲取到數組中實際存儲的元素數量。
3)因為「數組在內存中采用連續空間分配的存儲方式」,所以我們可以根據下標快速獲的取對應的學生信息。比如我們在數組下標為 2 的位置存入了某個學生的學號 111,那顯然,直接通過下標 2 就能獲取學號 111。但是「如果反過來我們想要查找學號 111 的下標呢」?數組原生是做不到的,這就需要使用各種查找算法了。
4)另外,假如我們想要存儲學生的姓名和家庭地址的一一對應信息,數組顯然也是做不到的。
5)如果我們想在這個用來存儲學生信息的數組中存儲一些老師的信息,數組是無法滿足這個需求的,它只能存儲相同類型的元素。
為了解決這些數組在使用過程中的痛點,集合框架應用而生。簡單來說,集合的主要功能就是兩點:
存儲不確定數量的數據(可以動態改變集合長度)
存儲具有映射關系的數據
存儲不同類型的數據
不過,需要注意的是,「集合只能存儲引用類型(對象),如果你存儲的是 int 型數據(基本類型),它會被自動裝箱成 Integer 類型。而數組既可以存儲基本數據類型,也可以存儲引用類型」。
2. 集合框架體系速覽
與現代的數據結構類庫的常見情況一樣,Java 集合類也將接口與實現分離,這些接口和實現類都位于 java.util 包下。按照其存儲結構集合可以分為兩大類:
單列集合 Collection
雙列集合 Map
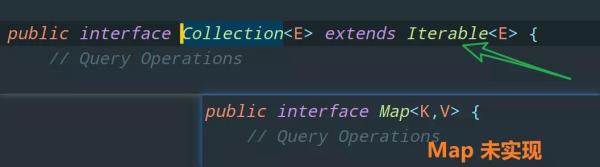
Collection 接口
「單列集合」 java.util.Collection:元素是孤立存在的,向集合中存儲元素采用一個個元素的方式存儲。

來看 Collection 接口的繼承體系圖:

Collection 接口中定義了一些單列集合通用的方法:
public boolean add(E e); // 把給定的對象添加到當前集合中 public void clear(); // 清空集合中所有的元素 public boolean remove(E e); // 把給定的對象在當前集合中刪除 public boolean contains(E e); // 判斷當前集合中是否包含給定的對象 public boolean isEmpty(); // 判斷當前集合是否為空 public int size(); // 返回集合中元素的個數 public Object[] toArray(); // 把集合中的元素,存儲到數組中
Collection 有兩個重要的子接口,分別是 List 和 Set,它們分別代表了有序集合和無序集合:
1)List 的特點是「元素有序、可重復」,這里所謂的有序意思是:「元素的存入順序和取出順序一致」。例如,存儲元素的順序是 11、22、33,那么我們從 List 中取出這些元素的時候也會按照 11、22、33 這個順序。List 接口的常用實現類有:
「ArrayList」:底層數據結構是數組,線程不安全
「LinkedList」:底層數據結構是鏈表,線程不安全
除了包括 Collection 接口的所有方法外,List 接口而且還增加了一些根據元素索引來操作集合的特有方法:
public void add(int index, E element); // 將指定的元素,添加到該集合中的指定位置上public E get(int index); // 返回集合中指定位置的元素public E remove(int index); // 移除列表中指定位置的元素, 返回的是被移除的元素public E set(int index, E element); // 用指定元素替換集合中指定位置的元素
2)Set 接口在方法簽名上與 Collection 接口其實是完全一樣的,只不過在方法的說明上有更嚴格的定義,最重要的特點是他「拒絕添加重復元素,不能通過整數索引來訪問」,并且「元素無序」。所謂無序也就是元素的存入順序和取出順序不一致。其常用實現類有:
「HashSet」:底層基于 HashMap 實現,采用 HashMap 來保存元素
「LinkedHashSet」:LinkedHashSet 是 HashSet 的子類,并且其底層是通過 LinkedHashMap 來實現的。
至于為什么要定義一個方法簽名完全相同的接口,我的理解是為了讓集合框架的結構更加清晰,將單列集合從以下兩點區分開來:
可以添加重復元素(List)和不可以添加重復元素(Set)
可以通過整數索引訪問(List)和不可以通過整數索引(Set)
這樣當我們聲明單列集合時能夠更準確的繼承相應的接口。
Map 接口
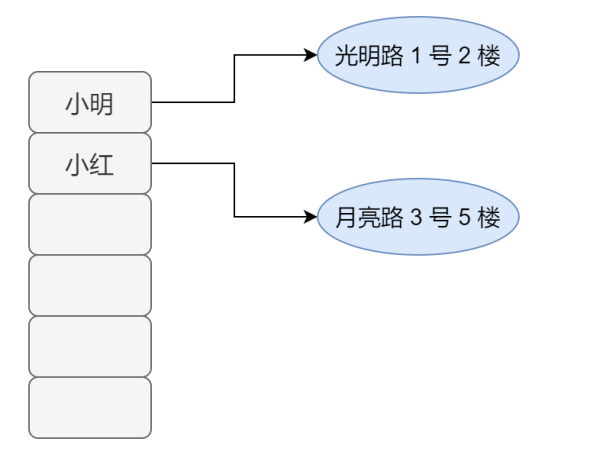
「雙列集合」 java.util.Map:元素是成對存在的。每個元素由鍵(key)與值(value)兩部分組成,通過鍵可以找對所對應的值。顯然這個雙列集合解決了數組無法存儲映射關系的痛點。另外,需要注意的是,「Map 不能包含重復的鍵,值可以重復;并且每個鍵只能對應一個值」。

來看 Map 接口的繼承體系圖:

Map 接口中定義了一些雙列集合通用的方法:
public V put(K key, V value); // 把指定的鍵與指定的值添加到 Map 集合中。 public V remove(Object key); // 把指定的鍵所對應的鍵值對元素在 Map 集合中刪除,返回被刪除元素的值。 public V get(Object key); // 根據指定的鍵,在 Map 集合中獲取對應的值。 boolean containsKey(Object key); // 判斷集合中是否包含指定的鍵。 public Set<K> keySet(); // 獲取 Map 集合中所有的鍵,存儲到 Set 集合中。
Map 有兩個重要的實現類,HashMap 和 LinkedHashMap :
① 「HashMap」:可以說 HashMap 不背到滾瓜爛熟不敢去面試,這里簡單說下它的底層結構,后面會開文詳細講解。JDK 1.8 之前 HashMap 底層由數組加鏈表實現,數組是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的(“拉鏈法” 解決沖突)。JDK1.8 以后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為 8)時,將鏈表轉化為紅黑樹,以減少搜索時間(注意:將鏈表轉換成紅黑樹前會判斷,如果當前數組的長度小于 64,那么會選擇先進行數組擴容,而不是轉換為紅黑樹)。
② 「LinkedHashMap」:HashMap 的子類,可以保證元素的存取順序一致(存進去時候的順序是多少,取出來的順序就是多少,不會因為 key 的大小而改變)。
LinkedHashMap 繼承自 HashMap,所以它的底層仍然是基于拉鏈式散列結構,即由數組和鏈表或紅黑樹組成。另外,LinkedHashMap 在上面結構的基礎上,增加了一條雙向鏈表,使得上面的結構可以保持鍵值對的插入順序。同時通過對鏈表進行相應的操作,實現了訪問順序相關邏輯。
OK,我們已經知道,Map中存放的是兩種對象,一種稱為 key(鍵),一種稱為 value(值),它倆在 Map 中是一一對應關系,這一對對象又稱做 Map 中的一個 「Entry」(項)。Entry 將鍵值對的對應關系封裝成了對象,即鍵值對對象。Map 中也提供了獲取所有 Entry 對象的方法:
public Set<Map.Entry<K,V>> entrySet(); // 獲取 Map 中所有的 Entry 對象的集合。
同樣的,Map 也提供了獲取每一個 Entry 對象中對應鍵和對應值的方法,這樣我們在遍歷 Map 集合時,就可以從每一個鍵值對(Entry)對象中獲取對應的鍵與對應的值了:
public K getKey(); // 獲取某個 Entry 對象中的鍵。 public V getValue(); // 獲取某個 Entry 對象中的值。
下面我們結合上述所學,來看看 Map 的兩種遍歷方式:
1)「遍歷方式一:根據 key 找值方式」
獲取 Map 中所有的鍵,由于鍵是唯一的,所以返回一個 Set 集合存儲所有的鍵。方法提示:keyset()
遍歷鍵的 Set 集合,得到每一個鍵。
根據鍵,獲取鍵所對應的值。方法提示:get(K key)
public static void main(String[] args) { // 創建 Map 集合對象 HashMap<Integer, String> map = new HashMap<Integer,String>(); // 添加元素到集合 map.put(1, "小五"); map.put(2, "小紅"); map.put(3, "小張"); // 獲取所有的鍵 獲取鍵集 Set<Integer> keys = map.keySet(); // 遍歷鍵集 得到 每一個鍵 for (Integer key : keys) { // 獲取對應值 String value = map.get(key); System.out.println(key + ":" + value); } }這里面不知道大家有沒有注意一個細節,keySet 方法的返回結果是 Set。Map 由于沒有實現 Iterable 接口,所以不能直接使用迭代器或者 for each 循環進行遍歷,但是轉成 Set 之后就可以使用了。至于迭代器是啥請繼續往下看。
2)「遍歷方式二:鍵值對方式」
獲取 Map 集合中,所有的鍵值對 (Entry) 對象,以 Set 集合形式返回。方法提示:entrySet()。
遍歷包含鍵值對 (Entry) 對象的 Set 集合,得到每一個鍵值對 (Entry) 對象。
獲取每個 Entry 對象中的鍵與值。方法提示:getkey()、getValue()
// 獲取所有的 entry 對象 Set<Entry<Integer,String>> entrySet = map.entrySet(); // 遍歷得到每一個 entry 對象 for (Entry<Integer, String> entry : entrySet) { Integer key = entry.getKey(); String value = entry.getValue(); System.out.println(key + ":" + value); }3. 迭代器 Iterator什么是 Iterator
在上一章數組中我們講過 for each 循環:
for(variable : collection) { // todo }collection 這一表達式必須是一個數組或者是一個實現了 Iterable 接口的類對象。可以看到 Collection 這個接口就繼承了 Itreable 接口,所以所有實現了Collection 接口的集合都可以使用 for each 循環。
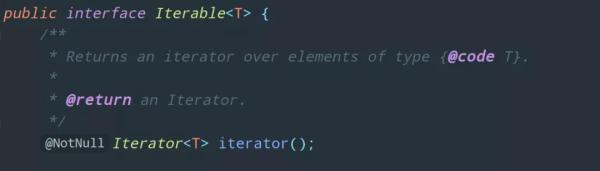
我們點進 Iterable 中看一看:

它擁有一個 iterator 方法,返回類型是 Iterator,這又是啥,我們再點進去看看:

又是三個接口,不過無法再跟下去了,我們去 Collection 的實現類中看看,有沒有實現 Itreator 這個接口,隨便打開一個,比如 ArrayList :

從源碼可知:Iterator 接口在 ArrayList 中是以「內部類」的方式實現的。并且,Iterator 實際上就是在遍歷集合。
所以總結來說:我們可以通過 Iterator 接口遍歷 Collection 的元素,這個接口的具體實現是在具體的子類中,以內部類的方式實現。
這里提個問題,「為什么迭代器不封裝成一個類,而是做成一個接口」?假設迭代器是一個類,這樣我們就可以創建該類的對象,調用該類的方法來實現 Collection的遍歷。
但事實上,Collection 接口有很多不同的實現類,在文章開頭我們就說過,這些類的底層數據結構大多是不一樣的,因此,它們各自的存儲方式和遍歷方式也是不同的,所以我們不能用一個類來規定死遍歷的方法。我們提取出遍歷所需要的通用方法,封裝進接口中,讓 Collection 的子類根據自己自身的特性分別去實現它。
看完上面這段分析,我們來驗證一下,看看 LinkedList 實現的 Itreator 接口和 ArrayList 實現的是不是不一樣:
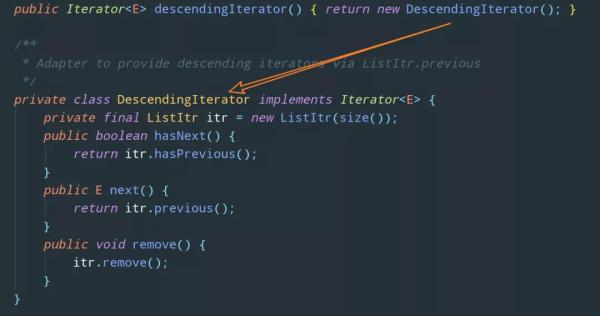
顯然,這兩個雖然同為 Collection 的實現類,但是它們具體實現 Itreator 接口的內部過程是不一樣的。
Iterator 基本使用
OK,我們已經了解了 Iterator 是用來遍歷 Collection 集合的,那么具體是怎么遍歷的呢?
答:「迭代遍歷」!
解釋一下迭代的概念:在取元素之前先判斷集合中有沒有元素,如果有,就把這個元素取出來,再繼續判斷,如果還有就再繼續取出來。一直到把集合中的所有元素全部取出。這種取出方式就稱為迭代。因此Iterator 對象也被稱為「迭代器」。
也就是說,想要遍歷 Collection 集合,那么就要獲取該集合對應的迭代器。如何獲取呢?其實上文已經出現過了,Collection 實現的 Iterable 中就有這樣的一個方法:iterator
再來介紹一下 Iterator 接口中的常用方法:
public E next(); // 返回迭代的下一個元素。 public boolean hasNext(); // 如果仍有元素可以迭代,則返回 true
舉個例子:
public static void main(String[] args) { Collection<String> coll = new ArrayList<String>(); // 添加元素到集合 coll.add("A"); coll.add("B"); coll.add("C"); // 獲取 coll 的迭代器 Iterator<String> it = coll.iterator(); while(it.hasNext()){ // 判斷是否有迭代元素 String s = it.next(); // 獲取迭代出的元素 System.out.println(s); } }當然,用 for each 循環可以更加簡單地表示同樣的循環操作:
Collection<String> coll = new ArrayList<String>(); ... for(String element : coll){ System.out.println(element); }上述內容就是Java 中有哪些集合框架,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





