溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何用Python替代Mapinfo更快查找兩張表中距離最近的點,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
工作中有時需要把A表中的經緯度點,從B表中匹配一個最近的點出來,用Mapinfo也可以實現,但處理速度慢,特別是數據量大時根本處理不動,此時用Python就能輕松實現,還能顯示處理進度,詳細如下。
用Python實現兩張表間最近點的計算。
軟件:PyCharm
需要的庫:pandas, xlrd,os
利用os、xlrd,選擇要讀取處理的Excel文件。
利用pandas庫讀取兩張表的內容,再定義函數計算兩個經緯度點的距離。
利用For循環,對兩張表的內容進行循環讀取,通過If判斷保留最近的距離點數據。
利用to_excel保存,得到最近點的數據。
import pandas as pd import xlrd import os
path="D:/a/" #獲取文件夾下所有EXCEL名 bb = path + 'result.xlsx' writer = pd.ExcelWriter(bb,engine='openpyxl') xlsx_names = [x for x in os.listdir(path) if x.endswith(".xlsx")] # 獲取第一個EXCEL名 xlsx_names1 = xlsx_names[0] aa = path + xlsx_names1 #打開第一個EXCEL first_file_fh=xlrd.open_workbook(aa) # 獲取SHEET名 first_file_sheet=first_file_fh.sheets()for i in range(h2): w1=df1.loc[i,'緯度'] j1 = df1.loc[i,'經度'] d1 = df1.loc[i, :] d0=10000000000000000000000000.0000 print("原小區第%d個。" %(i+1)) test_dict = {'距離': [d0]} d3 = pd.DataFrame(test_dict) for l in range(h3): w2=df2.loc[l, '緯度'] j2=df2.loc[l,'經度'] d=haversine(j1, w1, j2, w2) if d<d0: d0=d d2 = df2.loc[l, :] test_dict = {'距離': [d0]} d3 = pd.DataFrame(test_dict) else:continueresultdata1.to_excel(excel_writer=writer, sheet_name='原小區', encoding="utf-8", index=False) resultdata2.to_excel(excel_writer=writer, sheet_name='最近小區', encoding="utf-8", index=False) resultdata3.to_excel(excel_writer=writer, sheet_name='距離', encoding="utf-8", index=False) writer.save() writer.close()
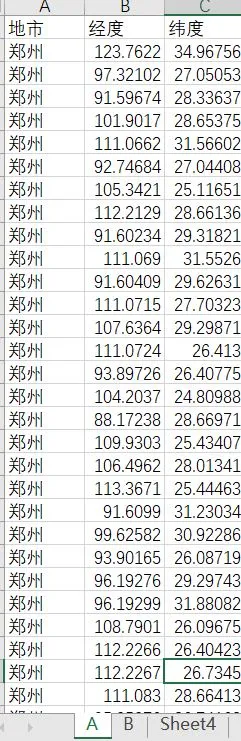
1、處理前數據:
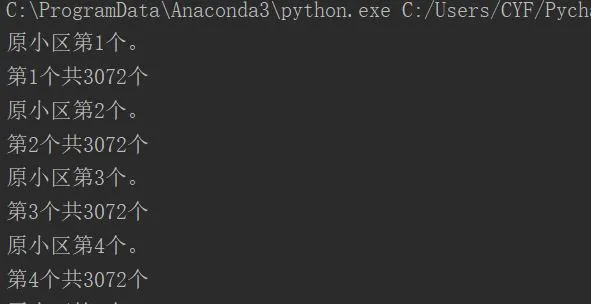
2、處理進度顯示:
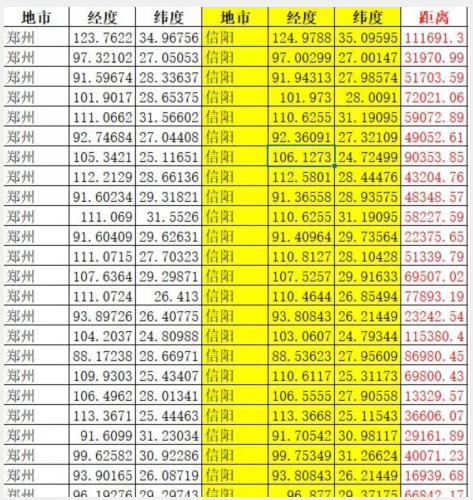
3、處理結果:
以上就是如何用Python替代Mapinfo更快查找兩張表中距離最近的點,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





