溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Zookeeper的基礎原理及應用場景”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Tips: 如果之前對Zookeeper不了解的話,這里大概留個印象就好了
Zookeeper是一個分布式協調服務,可以用于元數據管理、分布式鎖、分布式協調、發布訂閱、服務命名等等。
例如,Kafka中就是用Zookeeper來保存其集群中的相關元數據,例如Broker、Topic以及Partition等等。同時,基于Zookeeper的Watch監聽機制,還可以用其實現發布、訂閱的功能。
在平常的常規業務使用場景下,我們幾乎只會使用到分布式鎖這一個用途。
Zookeeper的底層存儲原理,有點類似于Linux中的文件系統。Zookeeper中的文件系統中的每個文件都是節點(Znode)。根據文件之間的層級關系,Zookeeper內部就會形成這個這樣一個文件樹。
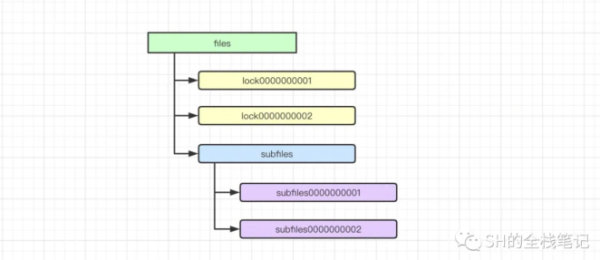
在Linux中,文件(節點)其實是分類型的,例如分為文件、目錄。在Zookeeper中同理,Znode同樣的有類型。在Zookeeper中,所有的節點類型如下:
持久節點(Persistent)
持久順序節點(Persistent Sequential)
臨時節點(Ephemeral)
臨時順序節點(Ephemeral Sequential)
所謂持久節點,就和我們自己在電腦上新建一個文件一樣,除非你主動刪除,否則一直存在。
而持久順序節點除了繼承了持久節點的特性之外,還會為其下創建的子節點保證其先后順序,并且會自動地為節點加上10位自增序列號作為節點名,以此來保證節點名的唯一性。這一點上圖中的subfiles已經給出了示例。
而臨時節點,其生命周期和client的連接是否活躍相關,如果client一旦斷開連接,該節點(可以理解為文件)就都會被刪除,并且臨時節點無法創建子節點;
PS:這里的斷開連接其實不是我們直覺上理解的斷開連接,Zookeeper有其Session機制,當某個client的Session過期之后,會將對應的client創建的節點全部刪除
接下來我們來分別看看幾種節點的創建方式,給出幾個簡單的示例。
創建持久節點
create /node_name SH的全棧筆記

這里需要注意的是,命令中所有的節點名稱必須要以/開頭,否則會創建失敗,因為在Zookeeper中是不能使用相對路徑,必須要使用絕對路徑。

創建持久順序節點
create -s /node_name SH的全棧筆記

可以看到,Zookeeper為key自動的加上了10位的自增后綴。
create -e /test SH的全棧筆記
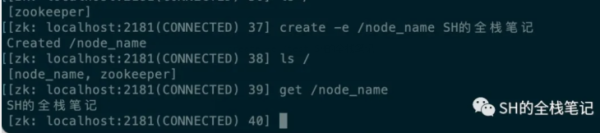
create -e -s /node_name SH的全棧筆記

我們通過一些具體的例子,來了解Zookeeper的詳細用途,它不僅僅只是被當作分布式鎖使用。
我們都知道,Kafka在運行時會依賴一個Zookeeper的集群。Kafka通過Zookeeper來管理集群的相關元數據,并通過Zookeeper進行Leader選舉。
Tips: 但是即將發布的Kafka 2.8版本中,Zookeeper已經不是一個必需的組件了。這塊我暫時還沒有時間去細看,不過我估計可能會跟RocketMQ中處理的方式差不多,將其集群的元數據放到Kafka本身來處理。
基于Zookeeper的分布式鎖其實流程很簡單。首先我們需要知道加分布式鎖的本質是什么?
答案是創建臨時順序節點
當某個客戶端加鎖成功之后,實際上則是成功的在Zookeeper上創建了臨時順序節點。我們知道,分布式鎖能夠使同一時間只能有一個能夠訪問某種資源。那這就必然會涉及到分布式鎖的競爭,那問題來了,當前這個客戶端是如何感知搶到了鎖呢?
其實在客戶端側會有一定的邏輯,假設加鎖的key為/locks/modify_users。
首先,客戶端會發起加鎖請求,然后會在Zookeeper上創建持久節點locks,然后會在該節點下創建臨時順序節點。臨時順序節點的創建示例,如下圖所示。
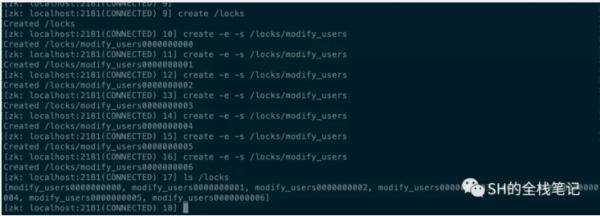
當客戶端成功創建了節點之后,還會獲取其同級的所有節點。也就是上圖中的所有modify_users000000000x的節點。
此時客戶端會根據10位的自增序號去判斷,當前自己創建的節點是否是所有的節點中最小的那個,如果是最小的則自己獲取到了分布式鎖。
你可能會問,那如果我不是最小的怎么辦呢?而且我的節點都已經創建了。如果不是最小的,說明當前客戶端并沒有搶到鎖。按照我們的認知,如果沒有競爭到分布式鎖,則會等待。等待的底層都做了什么?我們用實際例子來捋一遍。
假設Zookeeper中已經有了如下的節點。
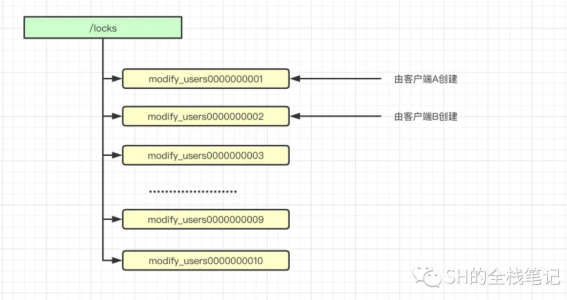
例如當前客戶端是B創建的節點是modify_users0000000002,那么很明顯B沒有搶到鎖,因為已經有比它還要小的由客戶端A創建的節點modify_users0000000001。
此時客戶端B會對節點modify_users0000000001注冊一個監聽器,對于該節點的任意更新都將觸發對應的操作。
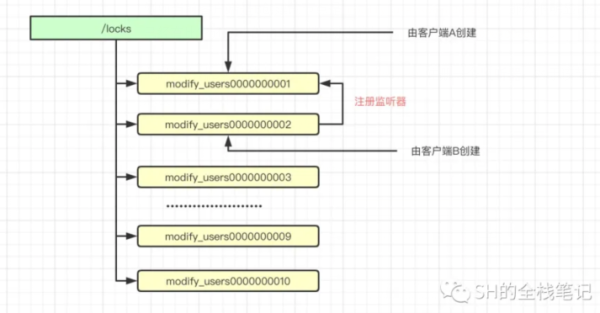
當其被刪除之后,就會喚醒客戶端B的線程,此時客戶端B會再次進行判斷自己是否是序號最小的一個節點,此時modify_users0000000002明顯是最小的節點,故客戶端B加鎖成功。
為了讓你更加直觀的了解這個過程,我把流程濃縮成了下面這幅流程圖。

我們都知道,在很多場景下要保證一致性都會采用經典的2PC(兩階段提交),例如MySQL中Redo Log和Binlog提交的數據一致性保障就是采用的2PC,詳情可以看基于Redo Log和Undo Log的MySQL崩潰恢復流程。
在2PC中存在兩種角色,分別是參與者(Participant)和協調者(Coordinator),協調者負責統一的調度所有分布式節點的執行邏輯。具體協調啥呢?舉個例子。
例如在2PC的Commit階段,兩個參與者A、B,A的commit操作成功了,但不幸的是B失敗了。此時協調者就需要向A發送Rollback操作。Zookeeper大概就是這樣一個角色。
由于Zookeeper自帶了監聽器(Watch)的功能,所以發布訂閱也順理成章的成為了Zookeeper的應用之一。例如在某個配置節點上注冊了監聽器,那么該配置一旦發布變更,對應的服務就能實時的感知到配置更改,從而達到配置的動態更新的目的。
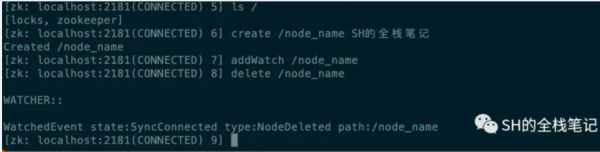
給個簡單的Watch使用示例。
用大白話來說,命名服務主要有兩種。
單純的利用Zookeeper的文件系統特性,存儲結構化的文件
利用文件特性和順序節點的特性,來生成全局的唯一標識
前者可以用于在系統之間共享某種業務上的特定資源,后者則可以用于實現分布式鎖。
“Zookeeper的基礎原理及應用場景”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





