溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“什么是k8s的可觀測性”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
“可觀測性”這個名詞其實是最近幾年才從控制理論中借用的舶來概念,不過實際上,計算機科學中關于可觀測性的研究內容已經有了很多年的實踐積累。通常,人們會把可觀測性分解為三個更具體的方向進行研究,分別是:日志收集、鏈路追蹤和聚合度量。
在 2017 年的分布式追蹤峰會(2017 Distributed Tracing Summit)結束后,彼得 · 波本(Peter Bourgon)撰寫了總結文章《Metrics, Tracing, and Logging》,就系統地闡述了這三者的定義、特征,以及它們之間的關系與差異,受到了業界的廣泛認可。
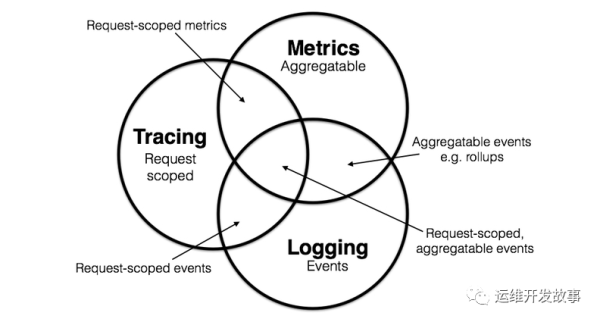
度量的主要目的是監控(Monitoring)和預警(Alert)。比如說,當某些度量指標達到了風險閾值時就觸發事件,以便自動處理或者提醒管理員介入。監控數據格式標準化,做關聯指標聚合,方便快速定位故障。
基礎層:監控主機和底層資源,比如:CPU、內存、網絡吞吐、硬盤 I/O、硬盤使用等。通信情況:這里是指主機與主機之間的網絡情況。通信是互聯網中最重要的基石之一,如果兩臺主機之間出現如網絡延遲時間大、丟包率高這樣的網絡問題,會導致業務受阻。
中間層:VM 指標監控,指的是 JVM 監控,比如 GC 時間、線程數、FGC/YGC 耗時等信息。當然,其他語言也有其獨特的統計指標信息。就是中間件層的監控,比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat 的資源消耗。
應用層:HTTP 訪問的吞吐量、響應時間、返回碼、性能瓶頸,還包括用戶端的監控。
統一的監控告警平臺:Prometheus+grafana
日志的職責是記錄離散事件,通過這些記錄事后分析出程序的行為,比如曾經調用過什么方法、曾經操作過哪些數據,等等。通常,打印日志被認為是程序中最簡單的工作之一,你在調試問題的時候,可能也經歷過這樣的情景“當初這里記得打點日志就好了”,可見這就是一項舉手之勞的任務。
當然,也有一部分系統是利用日志可追溯、結構化的特點,來實現相關功能的,比如我們最常見的 WAL(Write-Ahead Logging)。WAL 就是在操作之前先進行日志寫入,再執行操作;如果沒有執行操作,那么在下次啟動時就可以通過日志中結構化的,有時間標記的信息恢復操作,其中最典型的就是 MySQL 中的 Redo log。
統一的日志數據化:在特定時間發生的事件,被以結構化的形式記錄并產生的文本數據。
統一的日志分析:elk或者loki+grafana
在單體系統時代,追蹤的范疇基本只局限于棧追蹤(Stack Tracing)。比如說,你在調試程序的時候,在 IDE 打個斷點,看到的 Call Stack 視圖上的內容便是跟蹤;在編寫代碼時,處理異常調用了 Exception::printStackTrace() 方法,它輸出的堆棧信息也是追蹤。
而在微服務時代,追蹤就不只局限于調用棧了,一個外部請求需要內部若干服務的聯動響應,這時候完整的調用軌跡就會跨越多個服務,會同時包括服務間的網絡傳輸信息與各個服務內部的調用堆棧信息。因此,分布式系統中的追蹤在國內通常被稱為“全鏈路追蹤”(后面我就直接稱“鏈路追蹤”了),許多資料中也把它叫做是“分布式追蹤”(Distributed Tracing)。服務調用鏈跟蹤。這個監控系統應該從對外的 API 開始,然后將后臺的實際服務給關聯起來,然后再進一步將這個服務的依賴服務關聯起來,直到最后一個服務(如 MySQL 或 Redis),這樣就可以把整個系統的服務全部都串連起來了。
最近幾年,各種鏈路追蹤產品層出不窮,市面上主流的工具,既有像 Datadog 這樣的一攬子商業方案,也有像 AWS X-Ray 和 Google Stackdriver Trace 這樣的云計算廠商產品,還有像 SkyWalking、Zipkin、Jaeger 這樣來自開源社區的優秀產品。

鏈路追蹤+統計指標(Request-scoped metrics)請求級別的統計:在鏈路追蹤的基礎上,與相關的統計數據結合,從而得知數據與數據、應用與應用之間的關系。
鏈路追蹤+日志(Request-scoped events)請求級別的事件:這是鏈路中一個比較常見的組合模式。日志本身是每一條單獨存在的,將鏈路追蹤收集到的信息集成在日志中,可以讓日志之間具備關聯性,使其具有除了事件維度以外的另一個新的維度,上下文信息。
日志+統計指標(Aggregatable events)聚合級別的事件:這是在日志中的比較常見的組合。通過解析這部分具有統計指標的信息,我們可以獲取相關的指標數據。
三者結合(Request-scoped,aggregatable events)三者結合可以理解為請求級別+聚合級別的事件,由此就形成了一個豐富的、全局的觀測體系。
1.事件日志的職責是記錄離散事件,通過這些記錄事后分析出程序的行為;
2.追蹤的主要目的是排查故障,比如分析調用鏈的哪一部分、哪個方法出現錯誤或阻塞,輸入輸出是否符合預期;
3.度量是指對系統中某一類信息的統計聚合,主要目的是監控和預警,當某些度量指標達到風險閾值時就觸發事件,以便自動處理或者提醒管理員介入。
“什么是k8s的可觀測性”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





