溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Java如何高效的讀取一個超大文件”,在日常操作中,相信很多人在Java如何高效的讀取一個超大文件問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Java如何高效的讀取一個超大文件”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我最近在優化我的PDF轉word的開源小工具,有時候會遇到一個問題,就是如果我的PDF文件比較大,幾百兆,如何更快更節省內存的讀取它。于是我分析對比了四種常見的讀取文件的方式,并使用javaVisualVM工具進行了分析。最后的出的結論是commons-io時間和空間都更加的高效。研究分析依然來自哪位baeldung國外大佬。
下面我會給出幾種常見的讀取大文件的方式。
首先我自己在本地壓縮了一個文件夾,大概500M左右。雖然不是很大但是,相對還可以。
方法1:Guava讀取
String path = "G:\\java書籍及工具.zip"; Files.readLines(new File(path), Charsets.UTF_8);
使用guava讀取比較簡單,一行代碼就搞定了。
下面去jdk的bin目錄找到javaVisualVM工具,然后雙擊運行即可。
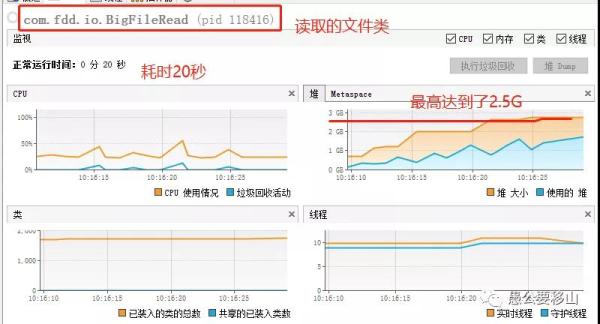
從上圖可以看到:
時間消耗:20秒
堆內存:最高2.5G
CPU消耗:最高50%
我們一個500M的文件,堆內存最高竟然2.5G,如果我們讀取一個2G的文件,可能我們的電腦直接死機了就。
方式2:Apache Commons IO普通方式
String path = "G:\\java書籍及工具.zip"; FileUtils.readLines(new File(path), Charsets.UTF_8);
這種方式也比較簡單,同樣是一行代碼。下面運行,也分析一波:
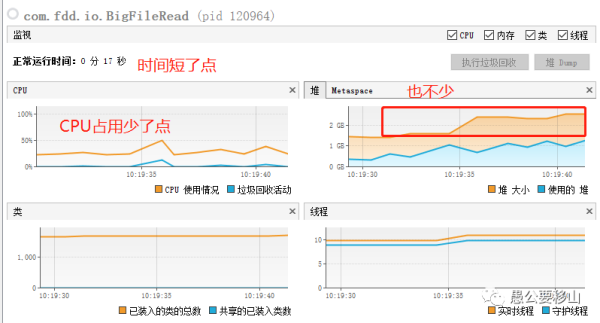
從上圖可以看到:
時間消耗:17秒
堆內存:最高2.5G
CPU消耗:最高50%,平穩運行25%左右
這種方式和上面那種基本上消耗差不多,肯定不是我想要的。
方式3:java文件流
FileInputStream inputStream = null; Scanner sc = null; try { inputStream = new FileInputStream(path); sc = new Scanner(inputStream, "UTF-8"); while (sc.hasNextLine()) { String line = sc.nextLine(); //System.out.println(line); } if (sc.ioException() != null) { throw sc.ioException(); } } finally { if (inputStream != null) { inputStream.close(); } if (sc != null) { sc.close(); } }這種方式其實就是java中最常見的方式,然后我們運行分析一波:
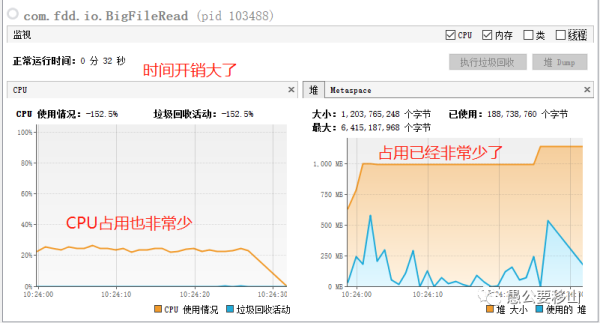
從上圖可以看到:
時間消耗:32秒,增加了一倍
堆內存:最高1G,少了一半
CPU消耗:平穩運行25%左右
這種方式確實很優秀,但是時間上開銷更大。
方式4:Apache Commons IO流
LineIterator it = FileUtils.lineIterator(new File(path), "UTF-8"); try { while (it.hasNext()) { String line = it.nextLine(); } } finally { LineIterator.closeQuietly(it); }這種方式代碼看起來比較簡單,所以直接運行一波吧:
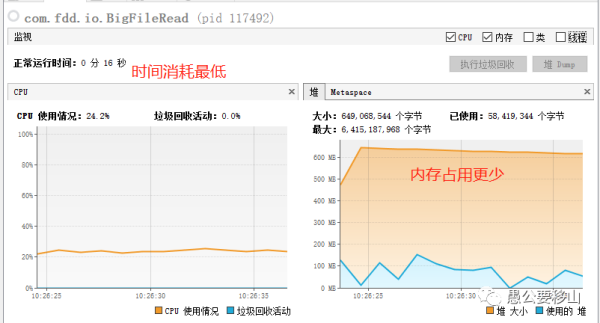
從上圖可以看到:
時間消耗:16秒,最低
堆內存:最高650M,少了一半
CPU消耗:平穩運行25%左右
OK,就它了,牛。
通過以上的分析,我們可以得出一個結論,如果我們想要讀取一個大文件,選擇了錯誤的方式,就有可能極大地占用我的內存和CPU,當文件特別大時,會造成意向不到的問題。
因此為了去解決這樣的問題,有四種常見的讀取大文件的方式。通過分析對比,發現,Apache Commons IO流是最高效的一種方式。
到此,關于“Java如何高效的讀取一個超大文件”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





