溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關JavaScript中Debugger的原理分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
代碼的運行方式可以分為直接執行和解釋執行兩類。
不知道平時你有沒有注意,可執行文件直接 ./xxx 就可以執行,而執行 js 文件需要 node ./xxx,執行 python 文件需要 python ./xxx,這就是編譯執行(直接執行)和解釋執行的區別。
直接執行
cpu 提供了一套指令集,基于這套指令集就可以控制整個計算機的運轉,機器語言的代碼就是由這些指令和對應的操作數構成的,這些機器碼可以直接跑在計算機上,也就是可直接執行。由它們構成的文件叫做可執行文件。
不同操作系統可執行文件的格式不同,在 windows 上是 pe(Portable Executable) 格式,在 linux、unix 系統上是 elf(Executable Linkable Format) 格式,在 mac 上是 mash-o 格式。它們規定了不同的內容(.text 是代碼、.data .bass 等是數據)放在文件中的什么位置。但其中真正可執行的部分還是由 cpu 提供的機器指令構成的。
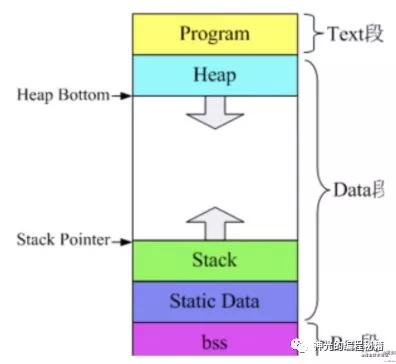
編譯型語言會經過編譯、匯編、鏈接的階段,編譯是把源代碼轉成匯編語言構成的中間代碼,匯編是把中間代碼變成目標代碼,鏈接會把目標代碼組合成可執行文件。這個可執行文件是可以在操作系統上直接執行的。就因為它是由 cpu 的機器指令構成的,可以直接控制 cpu。所以可以直接 ./xxx 就可以執行。

解釋執行
編譯型語言都是生成可執行文件直接在操作系統上來執行的,不需要安裝解釋器,而 js、python 等解釋型語言的代碼需要用解釋器來跑。
為什么有了解釋器就不需要生成機器碼了,cpu 仍然不認識這些代碼啊?
那是因為解釋器是需要編譯成機器碼的,cpu 知道怎么執行解釋器,而解釋器知道怎么執行更上層的腳本代碼,就這樣,由機器碼解釋執行解釋器,再由解釋器解釋執行上層代碼,這就是腳本語言的原理。 包括 js、python 等都是這樣。
但是解釋器畢竟多了一層,所以有的時候會把它編譯成機器碼來直接執行,這就是 JIT 編譯器。比如 js 引擎一般就是由 parser、解釋器、JIT 編譯器、GC 構成,大部分代碼是由解釋器解釋執行的,而熱點代碼會經過 JIT 編譯器編譯成由機器碼,直接在操作系統上執行以提高性能。
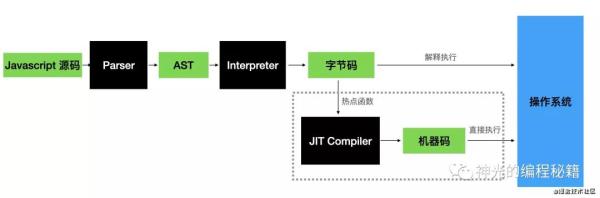
編譯成機器碼直接執行,或者是從源碼解釋執行,代碼就這兩種執行方式。兩者各有各的好處,編譯型速度快,解釋型跨平臺。這就是代碼運行的原理。
王垠說過,計算機的本質就是解釋器。就是說 cpu 用電路解釋機器碼,解釋器用機器碼解釋更上層的腳本代碼,所以計算機的本質是解釋器。
我們知道,圖靈完備的語言可以解釋任何可計算問題,所以不管是編譯型還是解釋型都能夠描述所有可計算的業務邏輯。
我們利用不同的語言描述業務邏輯,然后運行它看效果,當代碼的邏輯比較復雜的時候,難免會出錯,我們希望能夠一步步運行或是運行到某個點停下來,然后看一下當時的環境中的變量,執行某個腳本。完成這個功能的就是 debugger。
也許還有很多初級程序員只會用 console.log 打日志,但是日志不能完全展現當時的環境,最好的方式還是 debugger。
狼叔說過,是否會用 debugger 是 nodejs 水平的一個明顯的區分。
我們知道了 debugger 是調試程序必不可少的,那么它是怎么實現的呢?
可執行文件的 debugger
其實 cpu、操作系統在設計的時候就支持了 debugger 的能力(可見 debugger 的重要性),cpu 里面有 4 個寄存器可以做硬中斷,操作系統提供了系統調用來做軟中斷。這是編譯型語言的 debugger 實現的基礎。
中斷
cpu 只會不斷的執行下一條指令,但程序運行過程中難免要處理一些外部的消息,比如 io、網絡、異常等等,所以設計了中斷的機制,cpu 每執行完一條指令,就會去看下中斷標記,是否需要中斷了。就像 event loop 每次 loop 完都要檢查下是否需要渲染一樣。
INT 指令
cpu 支持 INT 指令來觸發中斷,中斷有編號,不同的編號有不同的處理程序,記錄編號和中斷處理程序的表叫做中斷向量表。其中 INT 3 (3 號中斷)可以觸發 debugger,這是一種約定。
那么可執行文件是怎么利用這個 3 號中斷來 debugger 的呢?其實就是運行時替換執行的內容,debugger 程序會在需要設置斷點的位置把指令內容換成 INT 3,也就是 0xCC,這就斷住了。就可以獲取這時候的環境數據來做調試。
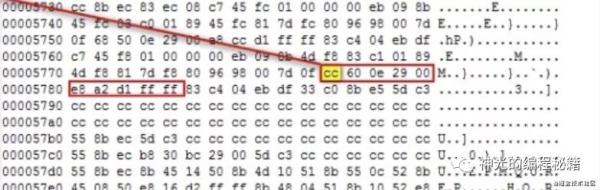
通過機器碼替換成 0xcc (INT 3)是把程序斷住了,可是怎么恢復執行呢?其實也比較簡單,把當時替換的機器碼記錄下來,需要釋放斷點的時候再換回去就行了。
這就是可執行文件的 debugger 的原理了,最終還是靠 cpu 支持的中斷機制來實現的。
中斷寄存器
上面說的 debugger 實現方式是修改內存中的機器碼的方式,但有的時候修改不了代碼,比如 ROM,這種情況就要通過 cpu 提供的 4 個中斷寄存器(DR0 - DR3)來做了。這種叫做硬中斷。
總之,INT 3 的軟中斷,還有中斷寄存器的硬中斷,是可執行文件實現 debugger 的兩種方式。
解釋型語言的 debugger
編譯型語言因為直接在操作系統之上執行,所以要利用 cpu 和操作系統的中斷機制和系統調用來實現 debugger。但是解釋型語言是自己實現代碼的解釋執行的,所以不需要那一套,但是實現思路還是一樣的,就是插入一段代碼來斷住,支持環境數據的查看和代碼的執行,當釋放斷點的時候就繼續往下執行。
比如 javascript 中支持 debugger 語句,當解釋器執行到這一條語句的時候就會斷住。
解釋型語言的 debugger 相對簡單一些,不需要了解 cpu 的 INT 3 中斷。
上面我們了解了直接執行和解釋執行的代碼的 debugger 分別是怎么實現的。我們知道了代碼是怎么斷住的,那么斷住之后呢?怎么把環境數據暴露出去,怎么執行外部代碼?
這就需要 debugger 客戶端了。
比如 v8 引擎會把設置斷點、獲取環境信息、執行腳本的能力通過 socket 暴露出去,socket 傳遞的信息格式就是 v8 debug protocol 。
比如:
設置斷點:
{ "seq":117, "type":"request", "command":"setbreakpoint", "arguments":{ "type":"function", "target":"f" }去掉斷點:
{ "seq":117, "type":"request", "command":"clearbreakpoint", "arguments": { "type":"function", "breakpoint":1 } }繼續:
{ "seq":117, "type":"request", "command":"continue" }執行代碼:
{ "seq":117, "type":"request", "command":"evaluate", "arguments":{ "expression":"1+2" } }感興趣的同學可以去 v8 debug protocol 的文檔中去查看全部的協議。
基于這些協議就可以控制 v8 的 debugger 了,所有的能夠實現 debugger 的都是對接了這個協議,比如 chrome devtools、vscode debugger 還有其他各種 ide 的 debugger。
nodejs 代碼的調試
nodejs 可以通過添加 --inspect 的 option 來做調試(也可以是 --inspect-brk,這個會在首行就斷住)。
它會起一個 debugger 的 websocket 服務端,我們可以用 vscode 來調試 nodejs 代碼,也可以用 chrome devtools 來調試(見 nodejs debugger 文檔)。
? node --inspect test.js Debugger listening on ws://127.0.0.1:9229/db309268-623a-4abe-b19a-c4407ed8998d For help see https://nodejs.org/en/docs/inspector
原理就是實現了 v8 debug protocol。
我們如果自己做調試工具、做 ide,那就要對接這個協議。
debugger adaptor protocol
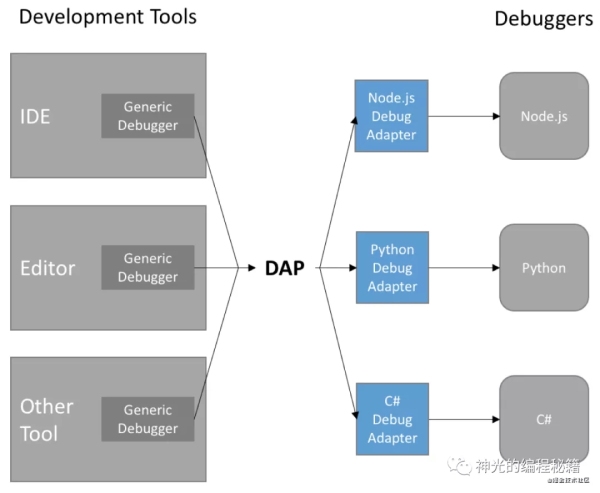
上面介紹的 v8 debug protocol 可以實現 js 代碼的調試,那么 python、c# 等肯定也有自己的調試協議,如果要實現 ide,都要對接一遍太過麻煩。所以后來出現了一個中間層協議,DAP(debugger adaptor protocol)。
debugger adaptor protocol, 顧名思義,就是適配的,一端適配各種 debugger 協議,一端提供給客戶端統一的協議。這是適配器模式的一個很好的應用。
感謝各位的閱讀!關于“JavaScript中Debugger的原理分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





