溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎么在Python中根據模板批量生成docx文檔,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
能夠根據模板批量生成docx文檔。具體而言,讀取excel中的數據,然后使用python批量生成docx文檔。
準備excel數據:
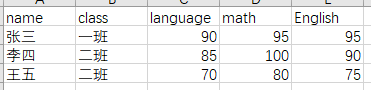
這里是關于學生語數英成績的統計表,文件名為score.xls
準備模板:

這是給學生家長的成績通知書,文件名為template.doc
另外,在使用python進行實驗之前,需要先安裝第三方庫docxtpl和xlrd,直接pip install就行:
pip install docxtpl pip install xlrd
然后將xls和doc和python文件放在同一個目錄下
首先打開xls,讀取數據:
workbook = xlrd.open_workbook(sheet_path)
然后從文件中獲取第一個表格:
sheet = workbook.sheet_by_index(0)
然后遍歷表格的每一行,將數據存入字典列表:
tables = []
for num in range(1, sheet.nrows):
stu = {}
stu['name'] = sheet.cell_value(num, 0)
stu['class'] = sheet.cell_value(num, 1)
stu['language'] = sheet.cell_value(num, 2)
stu['math'] = sheet.cell_value(num, 3)
stu['English'] = sheet.cell_value(num, 4)
tables.append(stu)接下來將列表中的數據寫入docx文檔,其實這個過程可以在讀數據時同時進行,即讀完一行數據,然后生成一個文檔。
首先在指定路徑生成一個docx文檔:
document = Document(word_path)
然后逐行進行正則表達式的替換:
paragraphs = document.paragraphs
text = re.sub('name', stu['name'], paragraphs[1].text)
paragraphs[1].text = text
text = re.sub('name', stu['name'], paragraphs[2].text)
text = re.sub('class', stu['class'], text)
text = re.sub('language', str(stu['language']), text)
text = re.sub('math', str(stu['math']), text)
text = re.sub('English', str(stu['English']), text)
paragraphs[2].text = text其實不關心格式問題的,到現在為止就已經結束了。但是這樣替換后docx中被替換的文字格式也被更改為系統默認的正文格式,所以接下來是將這些改成自己想要的格式:
遍歷需要更改格式的段落,然后更改字體大小和字體格式:
for run in paragraph.runs:
run.font.size = Pt(16)
run.font.name = "宋體"
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"), "宋體")最后保存文件:
document.save(path + "\\" + r"{}的成績通知單.docx".format(stu['name']))完整代碼:
from docxtpl import DocxTemplate
import pandas as pd
import os
import xlrd
path = os.getcwd()
# 讀表格
sheet_path = path + "\score.xls"
workbook = xlrd.open_workbook(sheet_path)
sheet = workbook.sheet_by_index(0)
tables = []
for num in range(1, sheet.nrows):
stu = {}
stu['name'] = sheet.cell_value(num, 0)
stu['class'] = sheet.cell_value(num, 1)
stu['language'] = sheet.cell_value(num, 2)
stu['math'] = sheet.cell_value(num, 3)
stu['English'] = sheet.cell_value(num, 4)
tables.append(stu)
print(tables)
# 寫文檔
from docx import Document
import re
from docx.oxml.ns import qn
from docx.shared import Cm,Pt
for stu in tables:
word_path = path + "\\template.doc"
document = Document(word_path)
paragraphs = document.paragraphs
text = re.sub('name', stu['name'], paragraphs[1].text)
paragraphs[1].text = text
text = re.sub('name', stu['name'], paragraphs[2].text)
text = re.sub('class', stu['class'], text)
text = re.sub('language', str(stu['language']), text)
text = re.sub('math', str(stu['math']), text)
text = re.sub('English', str(stu['English']), text)
paragraphs[2].text = text
for paragraph in paragraphs[1:]:
for run in paragraph.runs:
run.font.size = Pt(16)
run.font.name = "宋體"
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"), "宋體")
document.save(path + "\\" + r"{}的成績通知單.docx".format(stu['name']))文件中的文件:
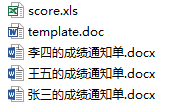
生成的文件樣例:

Python是一種跨平臺的、具有解釋性、編譯性、互動性和面向對象的腳本語言,其最初的設計是用于編寫自動化腳本,隨著版本的不斷更新和新功能的添加,常用于用于開發獨立的項目和大型項目。
看完上述內容,你們對怎么在Python中根據模板批量生成docx文檔有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





