溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python的另外兩種重要的數據類型Dict和Set,可以快速按照關鍵字檢索信息
list 和 tuple 可以用來表示順序集合,例如,班里同學的名字:
['Adam', 'Lisa', 'Bart']
或者考試的成績列表:
[95, 85, 59]
但是,要根據名字找到對應的成績,用兩個 list 表示就不方便。
如果把名字和分數關聯起來,組成類似的查找表:
'Adam' ==> 95
'Lisa' ==> 85
'Bart' ==> 59
給定一個名字,就可以直接查到分數。
Python的 dict 就是專門干這件事的。用 dict 表示“名字”-“成績”的查找表如下:
我們把名字稱為key,對應的成績稱為value,dict就是通過 key 來查找 value。
花括號 {} 表示這是一個dict,然后按照 key: value, 寫出來即可。最后一個 key: value 的逗號可以省略。
由于dict也是集合,len() 函數可以計算任意集合的大小:
注意: 一個 key-value 算一個,因此,dict大小為3。
訪問dict
創建了一個dict,用于表示名字和成績的對應關系:
那么,如何根據名字來查找對應的成績呢?
可以簡單地使用 d[key] 的形式來查找對應的 value,這和 list 很像,不同之處是,list 必須使用索引返回對應的元素,而dict使用key:
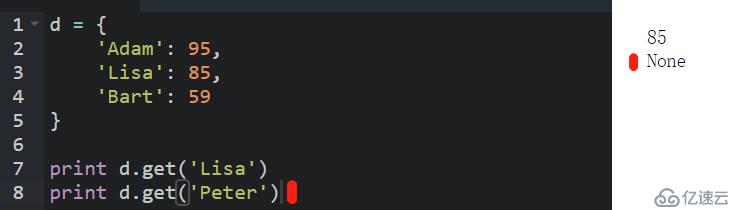
注意: 通過 key 訪問 dict 的value,只要 key 存在,dict就返回對應的value。如果key不存在,會直接報錯:KeyError:
要避免 KeyError 發生,有兩個辦法:
一是先判斷一下 key 是否存在,用 in 操作符:
如果 'Paul' 不存在,if語句判斷為False,自然不會執行 print d['Paul'] ,從而避免了錯誤。
二是使用dict本身提供的一個 get 方法,在Key不存在的時候,返回None:
### dict的特點
dict的第一個特點是查找速度快,無論dict有10個元素還是10萬個元素,查找速度都一樣。而list的查找速度隨著元素增加而逐漸下降。
不過dict的查找速度快不是沒有代價的,dict的缺點是占用內存大,還會浪費很多內容,list正好相反,占用內存小,但是查找速度慢。
由于dict是按 key 查找,所以,在一個dict中,key不能重復。
dict的第二個特點就是存儲的key-value序對是沒有順序的!這和list不一樣:
打印的順序不一定是我們創建時的順序,而且,不同的機器打印的順序都可能不同,這說明dict內部是無序的,不能用dict存儲有序的集合。
dict的第三個特點是作為 key 的元素必須不可變,Python的基本類型如字符串、整數、浮點數都是不可變的,都可以作為 key。但是list是可變的,就不能作為 key。
不可變這個限制僅作用于key,value是否可變無所謂:
最常用的key還是字符串,因為用起來最方便。
更新dict:
dict是可變的,也就是說,我們可以隨時往dict中添加新的 key-value。比如已有dict:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}要把新同學'Paul'的成績 72 加進去,用賦值語句:
>>> d['Paul'] = 72再看看dict的內容:
>>> print d
{'Lisa': 85, 'Paul': 72, 'Adam': 95, 'Bart': 59}如果 key 已經存在,則賦值會用新的 value 替換掉原來的 value:
>>> d['Bart'] = 60
>>> print d
{'Lisa': 85, 'Paul': 72, 'Adam': 95, 'Bart': 60}遍歷dict:
由于dict也是一個集合,所以,遍歷dict和遍歷list類似,都可以通過 for 循環實現。
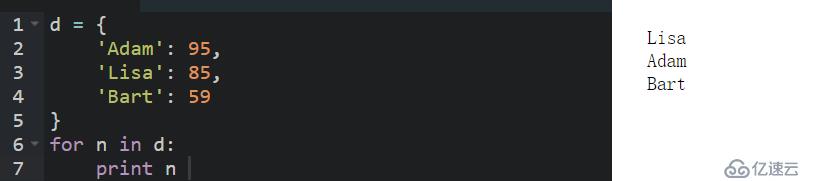
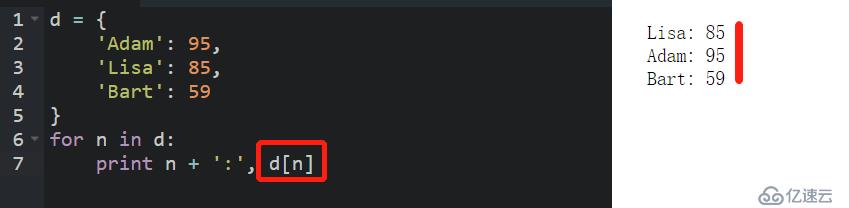
直接使用for循環可以遍歷 dict 的 key:
由于通過 key 可以獲取對應的 value,因此,在循環體內,可以獲取到value的值。
## set
dict的作用是建立一組 key 和一組 value 的映射關系,dict的key是不能重復的。
有的時候,我們只想要 dict 的 key,不關心 key 對應的 value,目的就是保證這個集合的元素不會重復,這時,set就派上用場了。
set 持有一系列元素,這一點和 list 很像,但是set的元素沒有重復,而且是無序的,這點和 dict 的 key很像。
創建 set 的方式是調用 set() 并傳入一個 list,list的元素將作為set的元素:
>>> s = set(['A', 'B', 'C'])
可以查看 set 的內容:
print s```
set(['A', 'C', 'B'])請注意,上述打印的形式類似 list, 但它不是 list,仔細看還可以發現,打印的順序和原始 list 的順序有可能是不同的,因為set內部存儲的元素是無序的。
因為set不能包含重復的元素,所以,當我們傳入包含重復元素的 list 會怎么樣呢?
>>> s = set(['A', 'B', 'C', 'C'])
>>> print s
set(['A', 'C', 'B'])
>>> len(s)
3結果顯示,set會自動去掉重復的元素,原來的list有4個元素,但set只有3個元素。
由于set存儲的是無序集合,所以我們沒法通過索引來訪問。
訪問 set中的某個元素實際上就是判斷一個元素是否在set中。
例如,存儲了班里同學名字的set:
>>> s = set(['Adam', 'Lisa', 'Bart', 'Paul'])
我們可以用 in 操作符判斷:
Bart是該班的同學嗎?
>>> 'Bart' in s
TrueBill是該班的同學嗎?
>>> 'Bill' in s
Falsebart是該班的同學嗎?
>>> 'bart' in s
False看來大小寫很重要,'Bart' 和 'bart'被認為是兩個不同的元素。
set的內部結構和dict很像,唯一區別是不存儲value,因此,判斷一個元素是否在set中速度很快。
set存儲的元素和dict的key類似,必須是不變對象,因此,任何可變對象是不能放入set中的。
最后,set存儲的元素也是沒有順序的。
set的這些特點,可以應用在哪些地方呢?
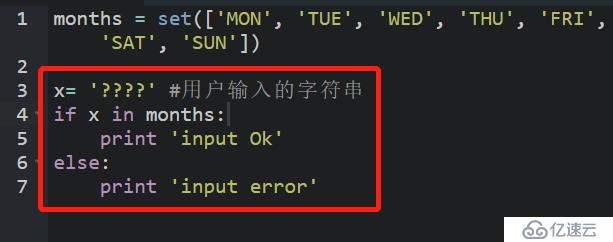
事先創建好一個set,包含'MON' ~ 'SUN':
再判斷輸入是否有效,只需要判斷該字符串是否在set中:
### 遍歷set
由于 set 也是一個集合,所以,遍歷 set 和遍歷 list 類似,都可以通過 for 循環實現。
直接使用 for 循環可以遍歷 set 的元素:
注意: 觀察 for 循環在遍歷set時,元素的順序和list的順序很可能是不同的,而且不同的機器上運行的結果也可能不同。
用 for 循環遍歷set,打印出 name: score 來:
注意:for循環之后變成tuple類型,tuple是有索引號的,所以加上數字分開。
## 更新set
由于set存儲的是一組不重復的無序元素,因此,更新set主要做兩件事:
一是把新的元素添加到set中,二是把已有元素從set中刪除。
添加元素時,用set的add()方法
如果添加的元素已經存在于set中,add()不會報錯,但是不會加進去了:
刪除set中的元素時,用set的remove()方法:
如果刪除的元素不存在set中,remove()會報錯.
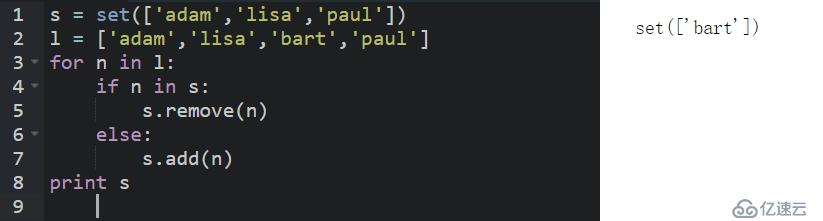
針對下面的set,給定一個list,對list中的每一個元素,如果在set中,就將其刪除,如果不在set中,就添加進去:
做法:
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。