溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹怎么用Node.js編寫內存效率高的應用程序,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
如果有人被要求用 NodeJS 寫一段文件復制的程序,那么他會迅速寫出下面這段代碼:
const fs = require('fs');
let fileName = process.argv[2];
let destPath = process.argv[3];
fs.readFile(fileName, (err, data) => {
if (err) throw err;
fs.writeFile(destPath || 'output', data, (err) => {
if (err) throw err;
});
console.log('New file has been created!');
});這段代碼簡單地根據輸入的文件名和路徑,在嘗試對文件讀取后把它寫入目標路徑,這對于小文件來說是不成問題的。
現在假設我們有一個大文件(大于4 GB)需要用這段程序來進行備份。就以我的一個達 7.4G 的超高清4K 電影為例子好了,我用上述的程序代碼把它從當前目錄復制到別的目錄。
$ node basic_copy.js cartoonMovie.mkv ~/Documents/bigMovie.mkv
然后在 Ubuntu(Linux )系統下我得到了這段報錯:
/home/shobarani/Workspace/basic_copy.js:7
if (err) throw err;
^
RangeError: File size is greater than possible Buffer: 0x7fffffff bytes
at FSReqWrap.readFileAfterStat [as oncomplete] (fs.js:453:11)
正如你看到的那樣,由于 NodeJS 最大只允許寫入 2GB 的數據到它的緩沖區,導致了錯誤發生在讀取文件的過程中。為了解決這個問題,當你在進行 I/O 密集操作的時候(復制、處理、壓縮等),最好考慮一下內存的情況。
為了解決上述問題,我們需要一個辦法把大文件切成許多文件塊,同時需要一個數據結構去存放這些文件塊。一個 buffer 就是用來存儲二進制數據的結構。接下來,我們需要一個讀寫文件塊的方法,而 Streams 則提供了這部分能力。
我們能夠利用 Buffer 對象輕松地創建一個 buffer。
let buffer = new Buffer(10); # 10 為 buffer 的體積 console.log(buffer); # prints <Buffer 00 00 00 00 00 00 00 00 00 00>
在新版本的 NodeJS (>8)中,你也可以這樣寫。
let buffer = new Buffer.alloc(10); console.log(buffer); # prints <Buffer 00 00 00 00 00 00 00 00 00 00>
如果我們已經有了一些數據,比如數組或者別的數據集,我們可以為它們創建一個 buffer。
let name = 'Node JS DEV'; let buffer = Buffer.from(name); console.log(buffer) # prints <Buffer 4e 6f 64 65 20 4a 53 20 44 45 5>
Buffers 有一些如buffer.toString()和buffer.toJSON()之類的重要方法,能夠深入到其所存儲的數據當中去。
我們不會為了優化代碼而去直接創建原始 buffer。NodeJS 和 V8 引擎在處理 streams 和網絡 socket 的時候就已經在創建內部緩沖區(隊列)中實現了這一點。
簡單來說,流就像 NodeJS 對象上的任意門。在計算機網絡中,入口是一個輸入動作,出口是一個輸出動作。我們接下來將繼續使用這些術語。
流的類型總共有四種:
可讀流(用于讀取數據)
可寫流(用于寫入數據)
雙工流(同時可用于讀寫)
轉換流(一種用于處理數據的自定義雙工流,如壓縮,檢查數據等)
下面這句話可以清晰地闡述為什么我們應該使用流。
Stream API (尤其是stream.pipe()方法)的一個重要目標是將數據緩沖限制在可接受的水平,這樣不同速度的源和目標就不會阻塞可用內存。
我們需要一些辦法去完成任務而不至于壓垮系統。這也是我們在文章開頭就已經提到過的。
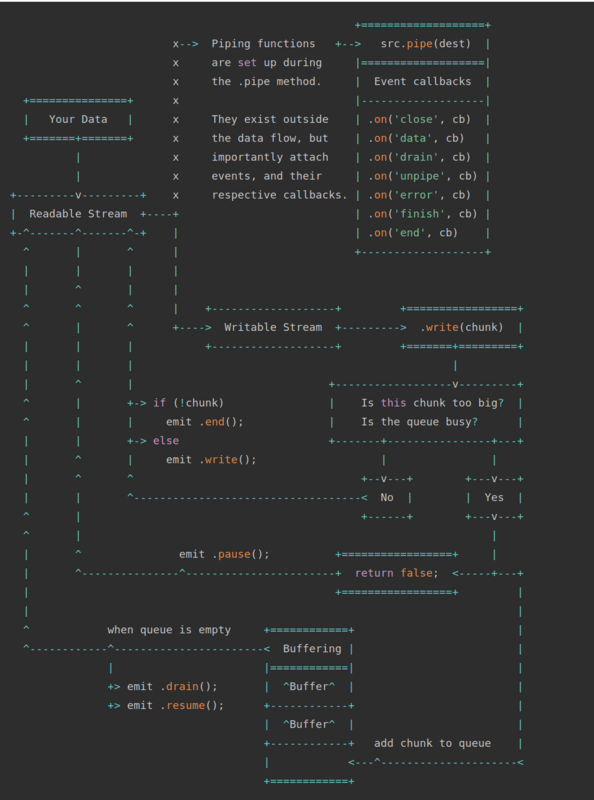
上面的示意圖中我們有兩個類型的流,分別是可讀流和可寫流。.pipe()方法是一個非常基本的方法,用于連接可讀流和可寫流。如果你不明白上面的示意圖,也沒關系,在看完我們的例子以后,你可以回到示意圖這里來,那個時候一切都會顯得理所當然。管道是一種引人注目的機制,下面我們用兩個例子來說明它。
讓我們設計一種解法來解決前文中大文件復制的問題。首先我們要創建兩個流,然后執行接下來的幾個步驟。
1.監聽來自可讀流的數據塊
2.把數據塊寫進可寫流
3.跟蹤文件復制的進度
我們把這段代碼命名為streams_copy_basic.js
/*
A file copy with streams and events - Author: Naren Arya
*/
const stream = require('stream');
const fs = require('fs');
let fileName = process.argv[2];
let destPath = process.argv[3];
const readabale = fs.createReadStream(fileName);
const writeable = fs.createWriteStream(destPath || "output");
fs.stat(fileName, (err, stats) => {
this.fileSize = stats.size;
this.counter = 1;
this.fileArray = fileName.split('.');
try {
this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1];
} catch(e) {
console.exception('File name is invalid! please pass the proper one');
}
process.stdout.write(`File: ${this.duplicate} is being created:`);
readabale.on('data', (chunk)=> {
let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100;
process.stdout.clearLine(); // clear current text
process.stdout.cursorTo(0);
process.stdout.write(`${Math.round(percentageCopied)}%`);
writeable.write(chunk);
this.counter += 1;
});
readabale.on('end', (e) => {
process.stdout.clearLine(); // clear current text
process.stdout.cursorTo(0);
process.stdout.write("Successfully finished the operation");
return;
});
readabale.on('error', (e) => {
console.log("Some error occured: ", e);
});
writeable.on('finish', () => {
console.log("Successfully created the file copy!");
});
});在這段程序中,我們接收用戶傳入的兩個文件路徑(源文件和目標文件),然后創建了兩個流,用于把數據塊從可讀流運到可寫流。然后我們定義了一些變量去追蹤文件復制的進度,然后輸出到控制臺(此處為 console)。與此同時我們還訂閱了一些事件:
data:當一個數據塊被讀取時觸發
end:當一個數據塊被可讀流所讀取完的時候觸發
error:當讀取數據塊的時候出錯時觸發
運行這段程序,我們可以成功地完成一個大文件(此處為7.4 G)的復制任務。
$ time node streams_copy_basic.js cartoonMovie.mkv ~/Documents/4kdemo.mkv
然而,當我們通過任務管理器觀察程序在運行過程中的內存狀況時,依舊有一個問題。
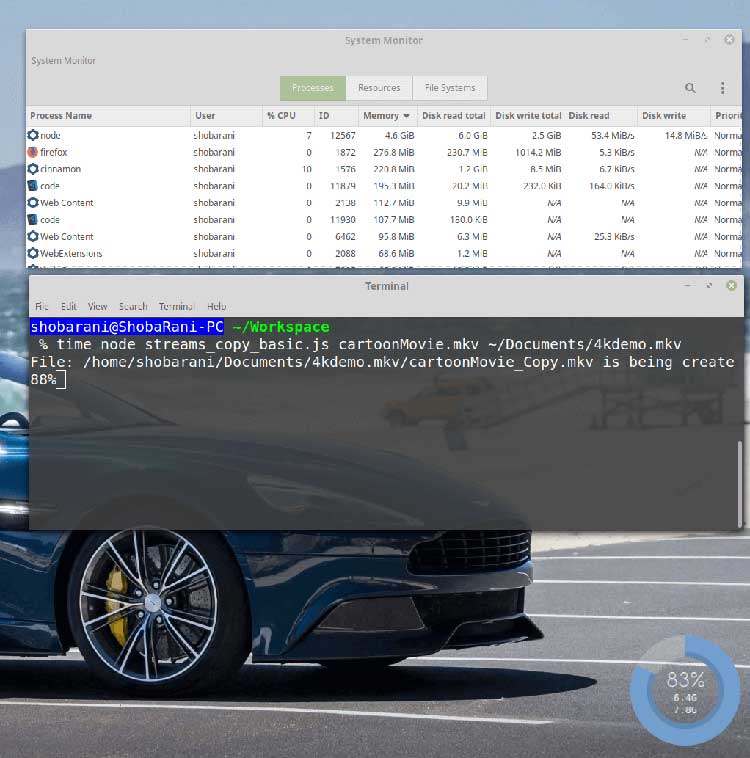
4.6GB?我們的程序在運行時所消耗的內存,在這里是講不通的,以及它很有可能會卡死其他的應用程序。
發生了什么?
如果你有仔細觀察上圖中的讀寫率,你會發現一些端倪。
Disk Read: 53.4 MiB/s
Disk Write: 14.8 MiB/s
這意味著生產者正在以更快的速度生產,而消費者無法跟上這個速度。計算機為了保存讀取的數據塊,將多余的數據存儲到機器的RAM中。這就是RAM出現峰值的原因。
上述代碼在我的機器上運行了3分16秒……
17.16s user 25.06s system 21% cpu 3:16.61 total
為了克服上述問題,我們可以修改程序來自動調整磁盤的讀寫速度。這個機制就是背壓。我們不需要做太多,只需將可讀流導入可寫流即可,NodeJS 會負責背壓的工作。
讓我們將這個程序命名為streams_copy_efficient.js
/*
A file copy with streams and piping - Author: Naren Arya
*/
const stream = require('stream');
const fs = require('fs');
let fileName = process.argv[2];
let destPath = process.argv[3];
const readabale = fs.createReadStream(fileName);
const writeable = fs.createWriteStream(destPath || "output");
fs.stat(fileName, (err, stats) => {
this.fileSize = stats.size;
this.counter = 1;
this.fileArray = fileName.split('.');
try {
this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1];
} catch(e) {
console.exception('File name is invalid! please pass the proper one');
}
process.stdout.write(`File: ${this.duplicate} is being created:`);
readabale.on('data', (chunk) => {
let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100;
process.stdout.clearLine(); // clear current text
process.stdout.cursorTo(0);
process.stdout.write(`${Math.round(percentageCopied)}%`);
this.counter += 1;
});
readabale.pipe(writeable); // Auto pilot ON!
// In case if we have an interruption while copying
writeable.on('unpipe', (e) => {
process.stdout.write("Copy has failed!");
});
});在這個例子中,我們用一句代碼替換了之前的數據塊寫入操作。
readabale.pipe(writeable); // Auto pilot ON!
這里的pipe就是所有魔法發生的原因。它控制了磁盤讀寫的速度以至于不會阻塞內存(RAM)。
運行一下。
$ time node streams_copy_efficient.js cartoonMovie.mkv ~/Documents/4kdemo.mkv
我們復制了同一個大文件(7.4 GB),讓我們來看看內存利用率。
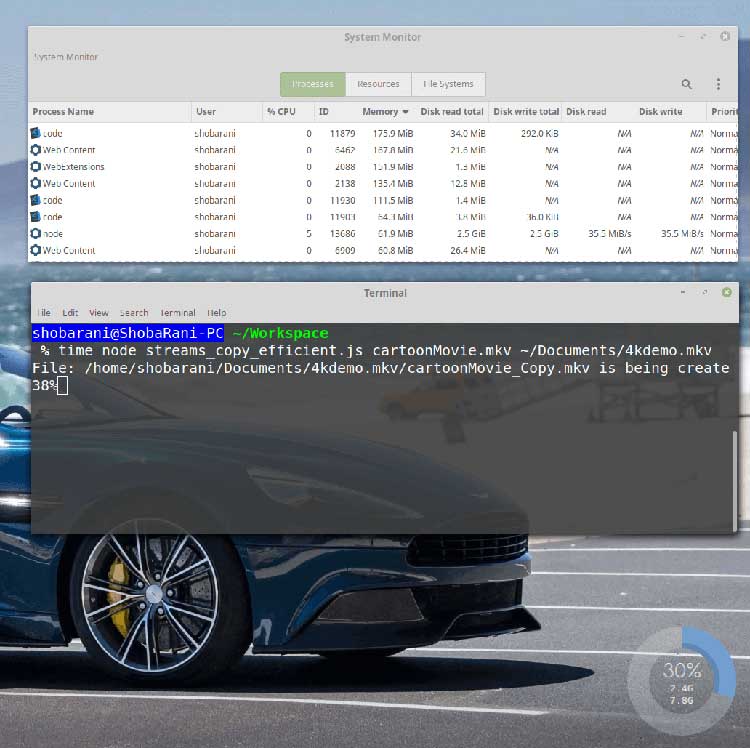
震驚!現在 Node 程序僅僅占用了61.9 MiB 的內存。如果你觀察到讀寫速率的話:
Disk Read: 35.5 MiB/s
Disk Write: 35.5 MiB/s
在任意給定的時間內,因為背壓的存在,讀寫速率得以保持一致。更讓人驚喜的是,這段優化后的程序代碼整整比之前的快了13秒。
12.13s user 28.50s system 22% cpu 3:03.35 total
由于 NodeJS 流和管道,內存負載減少了98.68%,執行時間也減少了。這就是為什么管道是一個強大的存在。
61.9 MiB 是由可讀流創建的緩沖區大小。我們還可以使用可讀流上的 read 方法為緩沖塊分配自定義大小。
const readabale = fs.createReadStream(fileName); readable.read(no_of_bytes_size);
除了本地文件的復制以外,這個技術還可以用于優化許多 I/O 操作的問題:
處理從卡夫卡到數據庫的數據流
處理來自文件系統的數據流,動態壓縮并寫入磁盤
以上是“怎么用Node.js編寫內存效率高的應用程序”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





