溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Node.js中Worker線程的作用是什么,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
在 worker 線程之前,Node.js 中有多種方式執行 CPU 密集型應用。其中的一些為:
使用child_process模塊并在一個子進程中運行 CPU 密集型代碼
使用cluster模塊,在多個進程中運行多個 CPU 密集型操作
使用諸如 Microsoft 的Napa.js這樣的第三方模塊
但是受限于性能、額外引入的復雜性、占有率低、薄弱的文檔化等,這些解決方案無一被廣泛采用。
盡管對于JavaScript的并發性問題來說,worker_threads是一個優雅的解決方案,但其并未給 JavaScript 本身帶來多線程特性。相反,worker_threads通過運行應用使用多個相互隔離的 JavaScript workers 來實現并發,而 workers 和父 worker 之間的通信由 Node 提供。聽懵了嗎? ?♂?
在 Node.js 中,每一個 worker 將擁有其自己的 V8 實例及事件循環(Event Loop)。但和child_process不同的是,workers 不共享內存。
以上概念會在后面解釋。我們首先來大致看一眼如何使用 Worker 線程。一個原生的用例看起來是這樣的:
// worker-simple.js
const {Worker, isMainThread, parentPort, workerData} = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename, {workerData: {num: 5}});
worker.once('message', (result) => {
console.log('square of 5 is :', result);
})
} else {
parentPort.postMessage(workerData.num * workerData.num)
}在上例中,我們向每個單獨的 workder 中傳入了一個數字以計算其平方值。在計算之后,子 worker 將結果發送回主 worker 線程。盡管看上去簡單,但 Node.js 新手可能還是會有點困惑。
JavaScript 語言沒有多線程特性。因此,Node.js 的 Worker 線程以一種異于許多其它高級語言傳統多線程的方式行事。
在 Node.js 中,一個 worker 的職責就是去執行一段父 worker 提供的代碼(worker 腳本)。這段 worker 腳本將會在隔絕于其它 workers 的環境中運行,并能夠在其自身和父 worker 間傳遞消息。worker 腳本既可以是一個獨立的文件,也可以是一段可被eval解析的文本格式的腳本。在我們的例子中,我們將__filename作為 worker 腳本,因為父 worker 和子 worker 代碼都在同一個腳本文件中,由isMainThread屬性決定其角色。
每個 worker 通過message channel連接到其父 worker。子 worker 可以使用parentPort.postMessage()函數向消息通道中寫入信息,父 worker 則通過調用 worker 實例上的worker.postMessage()函數向消息通道中寫入信息。看一下圖 1:
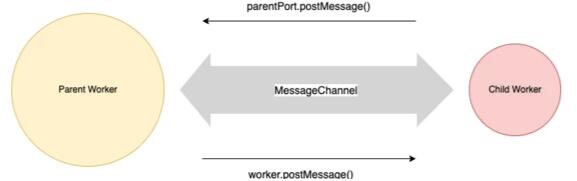
一個 Message Channel 就是一個簡單的通信渠道,其兩端被稱作 ‘ports'。在 JavaScript/NodeJS 術語中,一個 Message Channel 的兩端就被叫做port1和port2
現在關鍵的問題來了,JavaScript 并不直接提供并發,那么兩個 Node.js workers 要如何并行呢?答案就是V8 isolate。
一個V8 isolate就是 chrome V8 runtime 的一個單獨實例,包含自有的 JS 堆和一個微任務隊列。這允許了每個 Node.js worker 完全隔離于其它 workers 地運行其 JavaScript 代碼。其缺點在于 worker 無法直接訪問其它 workers 的堆數據了。
擴展閱讀:JS在瀏覽器和Node下是如何工作的?
由此,每個 worker 將擁有其自己的一份獨立于父 worker 和其它 workers 的 libuv 事件循環的拷貝。
實例化一個新 worker、提供和父級/同級 JS 腳本的通信,都是由 C++ 實現版本的 worker 完成的。在成文時,該實現為worker.cc(https://github.com/nodejs/node/blob/921493e228/src/node_worker.cc)。
Worker 的實現通過worker_threads模塊被暴露為用戶級的 JavaScript 腳本。該 JS 實現被分割為兩個腳本,我將之稱為:
初始化腳本 worker.js— 負責初始化 worker 實例,并建立初次父子 worker 通信,以確保從父 worker 傳遞 worker 元數據至子 worker。(https://github.com/nodejs/node/blob/921493e228/lib/internal/worker.js)
執行腳本 worker_thread.js— 根據用戶提供的workerData數據和其它父 worker 提供的元數據執行用戶的 worker JS 腳本。(https://github.com/nodejs/node/blob/921493e228/lib/internal/main/worker_thread.js)
圖 2 以更清晰的方式解釋了這個過程:
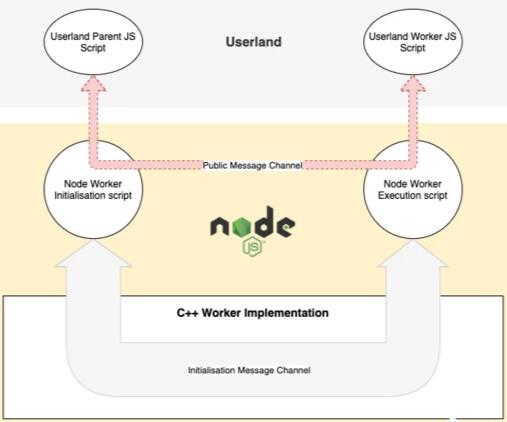
基于上述,我們可以將 worker 設置過程劃分為兩個階段:
worker 初始化
運行 worker
來看看每個階段都發生了什么吧:
1.用戶級腳本通過使用worker_threads創建一個 worker 實例
2.Node 的父 worker 初始化腳本調用 C++ 并創建一個空的 worker 對象。此時,被創建的 worker 還只是個未被啟動的簡單的 C++ 對象
3.當 C++ worker 對象被創建后,其生成一個線程 ID 并賦值給自身
4.同時,一個空的初始化消息通道(讓我們稱之為IMC)被父 worker 創建。圖 2 中灰色的 “Initialisation Message Channel” 部分展示了這點
5.一個公開的 JS 消息通道(稱其為PMC)被 worker 初始化腳本創建。該通道被用戶級 JS 使用以在父子 worker 之間傳遞消息。圖 1 中主要描述了這部分,也在圖 2 中被標為了紅色。
6.Node 父 worker 初始化腳本調用 C++ 并將需要被發送到 worker 執行腳本中的初始元數據寫入IMC。
什么是初始元數據?即執行腳本需要了解以啟動 worker 的數據,包括腳本名稱、worker 數據、PMC 的port2,以及其它一些信息。
按我們的例子來說,初始化元數據如:
:phone: 嘿!worker 執行腳本,請你用{num: 5}這樣的 worker 數據運行一下worker-simple.js好嗎?也請你把 PMC 的port2傳遞給它,這樣 worker 就能從 PMC 讀取數據啦。
下面的小片段展示了初始化數據如何被寫入 IMC:
const kPublicPort = Symbol('kPublicPort');
// ...
const { port1, port2 } = new MessageChannel();
this[kPublicPort] = port1;
this[kPublicPort].on('message', (message) => this.emit('message', message));
// ...
this[kPort].postMessage({
type: 'loadScript',
filename,
doEval: !!options.eval,
cwdCounter: cwdCounter || workerIo.sharedCwdCounter,
workerData: options.workerData,
publicPort: port2,
// ...
hasStdin: !!options.stdin
}, [port2]);代碼中的this[kPort]是初始化腳本中 IMC 的端點。盡管 worker 初始化腳本向 IMC 寫入了數據,但 worker 執行腳本仍無法訪問該數據。
此時,初始化已告一段落;接下來 worker 初始化腳本調用 C++ 并啟動 worker 線程。
1.一個新的V8 isolate被創建并被分配給 worker。前面講過,一個 “v8 isolate” 就是 chrome V8 runtime 的一個單獨實例。這使得 worker 線程的執行上下文隔離于應用代碼中的其它部分。
2.libuv被初始化。這確保了 worker 線程保有其自己獨立于應用中的其它部分事件循環。
3.worker 執行腳本被執行,并且 worker 的事件循環被啟動。
4.worker 執行腳本調用 C++ 并從 IMC 中讀取初始化元數據。
5.worker 執行腳本執行對應文件或代碼(在我們的例子中就是worker-simple.js),以作為一個 worker 開始運行。
看看下面的代碼片段,worker 執行腳本是如何從 IMC 讀取數據的:
const publicWorker = require('worker_threads');
// ...
port.on('message', (message) => {
if (message.type === 'loadScript') {
const {
cwdCounter,
filename,
doEval,
workerData,
publicPort,
manifestSrc,
manifestURL,
hasStdin
} = message;
// ...
initializeCJSLoader();
initializeESMLoader();
publicWorker.parentPort = publicPort;
publicWorker.workerData = workerData;
// ...
port.unref();
port.postMessage({ type: UP_AND_RUNNING });
if (doEval) {
const { evalScript } = require('internal/process/execution');
evalScript('[worker eval]', filename);
} else {
process.argv[1] = filename; // script filename
require('module').runMain();
}
}
// ...是否注意到以上片段中的workerData和parentPort屬性被指定給了publicWorker對象呢?后者是在 worker 執行腳本中由require('worker_threads')引入的。
這就是為何workerData和parentPort屬性只在子 worker 線程內部可用,而在父 worker 的代碼中不可用了。
如果嘗試在父 worker 代碼中訪問這兩個屬性,都會返回null。
現在我們理解 Node.js 的 worker 線程是如何工作的了,這的確能幫助我們在使用 Worker 線程時獲得最佳性能。當編寫比worker-simple.js更復雜的應用時,需要記住以下兩個主要的關注點:
盡管 worker 線程比真正的進程更輕量,但如果頻繁讓 workers 陷入某些繁重的工作仍會開銷巨大。
使用 worker 線程承擔并行 I/O 操作仍是不劃算的,因為 Node.js 原生的 I/O 機制是比從頭啟動一個 worker 線程去做同樣的事更快的方式。
為了克服第 1 點的問題,我們需要實現“worker 線程池”。
Node.js 的 worker 線程池是一組正在運行且能夠被后續任務利用的 worker 線程。當一個新任務到來時,它可以通過父子消息通道被傳遞給一個可用的 worker。一旦完成了這個任務,子 worker 能將結果通過同樣的消息通道回傳給父 worker。
一旦實現得當,由于減少了創建新線程帶來的額外開銷,線程池可以顯著改善性能。同樣值得一提的是,因為可被有效運行的并行線程數總是受限于硬件,創建一堆數目巨大的線程同樣難以奏效。
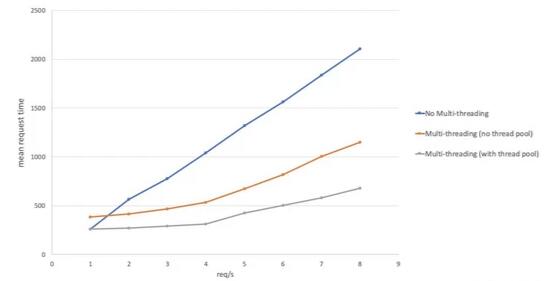
下圖是對三臺 Node.js 服務器的一個性能比較,它們都接收一個字符串并返回做了 12 輪加鹽處理的一個 Bcrypt 哈希值。三臺服務器分別是:
不用多線程
多線程,沒有線程池
有 4 個線程的線程池
一眼就能看出,隨著負載增長,使用一個線程池擁有顯著小的開銷。
看完上述內容,你們對Node.js中Worker線程的作用是什么有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





