溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹怎么在Redis中實現持久化與主從復制,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
Redis是基于內存的NoSQL數據庫,讀寫速度自然快,但內存是瞬時的,在redis服務關閉或重啟之后,redis存放在內存的數據就會丟失,為了解決這個問題,redis提供了兩種持久化方式,以便在發生故障后恢復數據。
redis提供了兩種不同的持久化方式來將數據存儲到硬盤中。一種是快照方式(也叫RDB方式),它可以將莫一時刻存在于redis中的所有數據存儲到硬盤;另一種叫只追加文件(AOF)方式,它會定時的復制redis執行的所有寫命令到硬盤。這兩種持久化方式各有千秋,既可以同時使用,也可以獨立使用,在某些情況下甚至可以兩種都不使用。
RDB方式
RDB方式也稱快照方式,通過創建快照來保存某個時間點上的數據副本(.rdb)到硬盤。在重啟服務器后,redis會加載這個rdb文件來還原數據。先來看一下rdb持久化配置。vi redis.conf打開redis的配置文件,找到SNAPSHOTTING部分,發現如下內容:
save 900 1 save 300 10 save 60 10000 …… dbfilename dump.rdb dir ./
說明
save seconds changes:表示在seconds秒后,如果有不少與changes個key發生改變,則保存一次快照。可以看到,rdb持久化默認是開啟的,并且配置了三個save選項,如果想要關閉rdb持久化,將所有的save注釋掉就好了
dbfilename:rdb文件名
dir:rdb文件存放路徑
創建快照
BGSAVE:BGSAVE命令可以用于創建一個快照,在redis接收到BGSAVE命令后會fork出一個子進程,子進程負責將快照寫入硬盤,而父進程則繼續處理命令請求。需要注意的是redis在創建子進程時會阻塞父進程,時間長短與redis占用的內存大小成正比。
除了手動的調用BGSAVE命令外,BGSAVE命令的觸發條件有如下兩種:
用戶配置了save選項,從redis最近一次創建快照開始算起,當任意一個save選項的條件被滿足時,會觸發一次BGSAVE命令。
在進行主從復制連接時,剛連上來的從服務器會向主服務器發送SYNC命令請求數據同步,在主服務器收到SYNC命令后,會執行一次BGSAVE命令,后將生成的rdb文件發送給從服務器進行數據同步。
SAVE:SAVE命令同樣可以創建一個快照,但與BGSAVE命令不同的是SAVE命令不會創建子進程,所以接收到SAVE命令的redis服務器在快照創建完畢之前不會響應其他任何命令。由于在創建快照的過程中沒有其他進程搶奪資源,所以SAVE命令創建快照的速度會比BGSAVE命令創建快照更快一些。即使這樣,SAVE命令也并不常用,通常只會在沒有足夠內存或等待快照生成完畢也無所謂的情況下才會使用。
例如,當redis收到SHUTDOWN命令關閉服務時,就會執行一次SAVE命令,阻塞所有客戶端,并在SAVE命令執行完畢后關閉。
RDB方式的優劣
優勢:
僅用一個文件備份數據,災后易于恢復相比于aof,rdb文件更小,并且加載rdb文件恢復數據也更快
劣勢:
如果redis服務因故障關閉或重啟,會丟失最近一次快照創建后寫入的數據當數據量很大的時候,創建子進程會導致redis較長時間的停頓
AOF方式
簡單來說,AOF持久化會將被執行的寫命令寫到aof文件的末尾,以此來記錄數據發生的變化。因此,redis只要從頭到尾重新執行一遍aof文件中包含的所有寫命令,就可以恢復數據。
打開redis配置文件可以看到:
# 是否開啟aof持久化,默認為關閉(no) appendonly yes # 設置對aof文件的同步頻率 # 每接收到一條寫命令就進行一次同步,數據保障最有力,但對性能影響十分嚴重 appendfsync always # 每秒進行一次同步,推薦 appendfsync everysec # 由操作系統來決定何時進行同步 appendfsync no # 重寫aof相關 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
重寫/壓縮aof文件
由于aof持久化會不斷地記錄redis的寫命令,隨著redis的運行,aof文件會越來越大,占用過多的硬盤空間,并增加redis進行數據還原操作的時間。因此,必須要有避免aof文件體積過大的控制方案。
redis提供了BGREWRITEAOF命令對aof文件進行重寫,BGREWRITEAOF會通過移除原aof文件中冗余的命令來盡可能的減小aof文件的體積。BGREWRITEAOF的工作原理與BGSAVE很像,會由redis創建一個子進程,再由子進程對aof文件進行重寫。
當然,BGREWRITEAOF命令同樣也有自動觸發的機制,可通過配置auto-aof-rewrite-percentage和auto-aof-rewrite-min-size來自動執行。例如,配置了auto-aof-rewrite-percentage 100 和 auto-aof-rewrite-min-size 64mb,并且開啟了aof持久化,那么在aof文件體積大于64mb且當前文件比上一次重寫后的文件體積大了一倍(100%)以上時,redis會自動執行BGREWRITEAOF命令。
AOF持久化的優劣
優勢
可以將丟失數據的時間窗口降低至1秒,并且不會對性能在成太大影響aof對于日志文件采用的是追加模式,因此在寫入過程中即使出現宕機,也不會破壞日志文件中已經存在的內容;若只寫入一半數據就宕機,在redis下次啟動時,可通過redis-check-aod工具來解決數據一致性的問題
劣勢
aof文件的體積一直是AOF持久化最大的缺陷,即使有重寫aof文件的機制存在載入aof文件恢復數據的過程會比載入rdb文件耗時更長
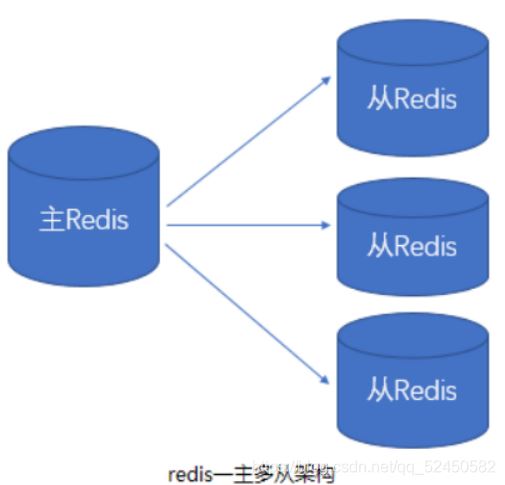
盡管redis性能十分優秀,但還是會遇到無法快速處理請求的問題,為了抗高并發帶來的數據庫性能問題,redis可以像關系型數據庫一樣進行主從復制、讀寫分離。即向主服務器寫入數據,從服務器實時收到更新,并使用從服務器處理所有的讀請求,而不是像以前一樣將所有讀請求都發送給主服務器,造成主服務器壓力過大,通常讀請求會隨機地選擇使用哪一個從服務器,從而使負載均衡地分配到每一個從服務器上。下圖是一個簡單的redis主從架構。
首先在你的redis目錄下執行vi redis6380.conf在當前目錄下創建一個redis配置文件,寫入如下內容:
include /usr/local/redis-4.0.13/redis.conf port 6380 pidfile /var/run/redis_6380.pid logfile 6380.log dbfilename dump6380.rdb
說明:
include:向當前配置文件中引入所指向的配置文件的配置信息,這里引入的是redis默認配置文件,其中已經設置過遠程訪問、密碼等,沒必要在新的配置文件中重新設置。對于有必要重新配置的配置信息來說(如端口號),include行下進行的配置可以覆蓋引用的配置。
port:端口號,我們的主從服務器是跑在同一臺虛擬機上的,因此需要配置不同的端口號。
pidfile:自定義的pid文件,后臺程序的pid存在這個文件里。
logfile:日志文件。
dbfilename:rdb文件的名字。
經過上述操作,一個新的主服務器就配置好了,接下來配置從服務器,同樣在當前目錄下創建一個redis配置文件起名redis6382vi redis6382.conf
include /usr/local/redis-4.0.13/redis.conf port 6382 pidfile /var/run/redis_6382.pid logfile 6382.log dbfilename dump6382.rdb slaveof 127.0.0.1 6380 masterauth 主服務器的密碼
其中有一些從服務器額外的配置:
slaveof:表示我是誰的從服務器,需要制定主服務器的ip地址和端口號
masterauth:假如你的主服務器配置了密碼,那么需要在此進行配置,否則從服務器將無法連接到主服務器
其他的從服務器配置也都類似,注意分配端口號,我這里又配置了一個6384。
配置成功后,在src目錄下使用./redis-server ../redis6380.conf就可以開啟主服務器了,接下來開啟從服務器會自動連到主服務器上,注意指定對應的配置文件。
執行ps -ef | grep redis看到如下內容則表示主從服務器啟動成功:
root 2625 1 0 16:15 ? 00:00:00 ./redis-server *:6380 root 2630 1 0 16:15 ? 00:00:00 ./redis-server *:6382 root 2636 1 0 16:15 ? 00:00:00 ./redis-server *:6384
在主從服務器都啟動好了以后,進入主服務器的客戶端./redis-cli -p 6380 -a 你的密碼,執行info replication可以查看主從服務器信息,如下
127.0.0.1:6380> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6382,state=online,offset=336,lag=1 slave1:ip=127.0.0.1,port=6384,state=online,offset=336,lag=1 master_replid:b5c68a979b28d2a9ef53476510758b5d1795418b master_replid2:0000000000000000000000000000000000000000 master_repl_offset:336 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:336
同樣,在從服務器客戶端中執行上述命令,也能夠得到信息
127.0.0.1:6384> info replication # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:686 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:b5c68a979b28d2a9ef53476510758b5d1795418b master_replid2:0000000000000000000000000000000000000000 master_repl_offset:686 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:15 repl_backlog_histlen:672
至此,一個一主兩從、讀寫分離的redis架構已經配置好并成功啟動了。
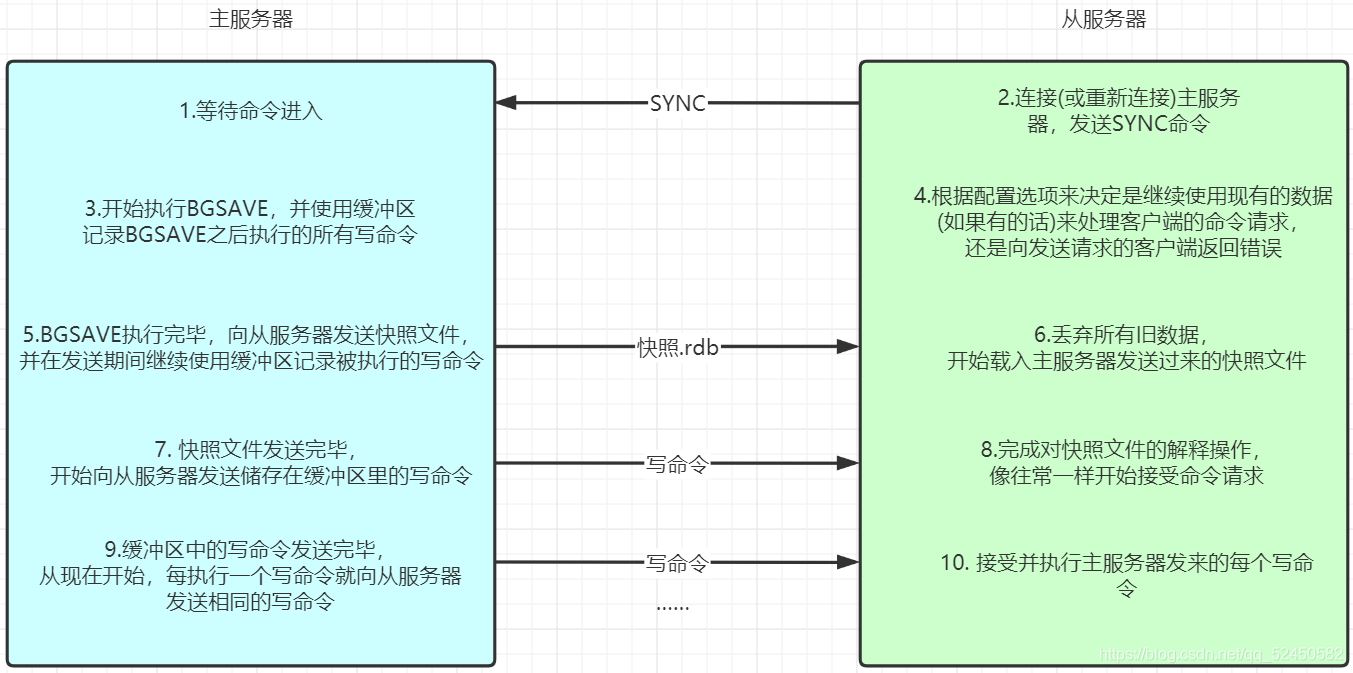
上圖是舊版主從Redis的啟動過程,需要特殊說明的幾點是:
從服務器在進行初始連接的時候,數據庫中原有的所有數據都將被丟失,并替換成主服務器發送來的數據
從服務器不負責key的過期操作,而是被動的接受主服務器發來的命令,當一個 master 讓一個 key 到期(或由于 LRU 算法將之驅逐)時,它會合成一個 DEL 命令并傳輸到所有的 slave
SYNC是一個非常耗費資源的操作,在BGSAVE期間主服務器的總吞吐量下降,接著耗費大量的主從服務器的網絡資源傳送rdb文件,在從服務器載入rdb文件時會無法響應客戶端的請求;但SYNC最大的缺陷是在從服務器因斷線進行重新連接時,沒必要申請一個rdb文件從頭再加載一次,因為這個新的rdb文件中包含的大部分數據很可能在斷線之前就已經寫入了從服務器,此時從服務器只需要得到在斷線期間寫入的數據就得了
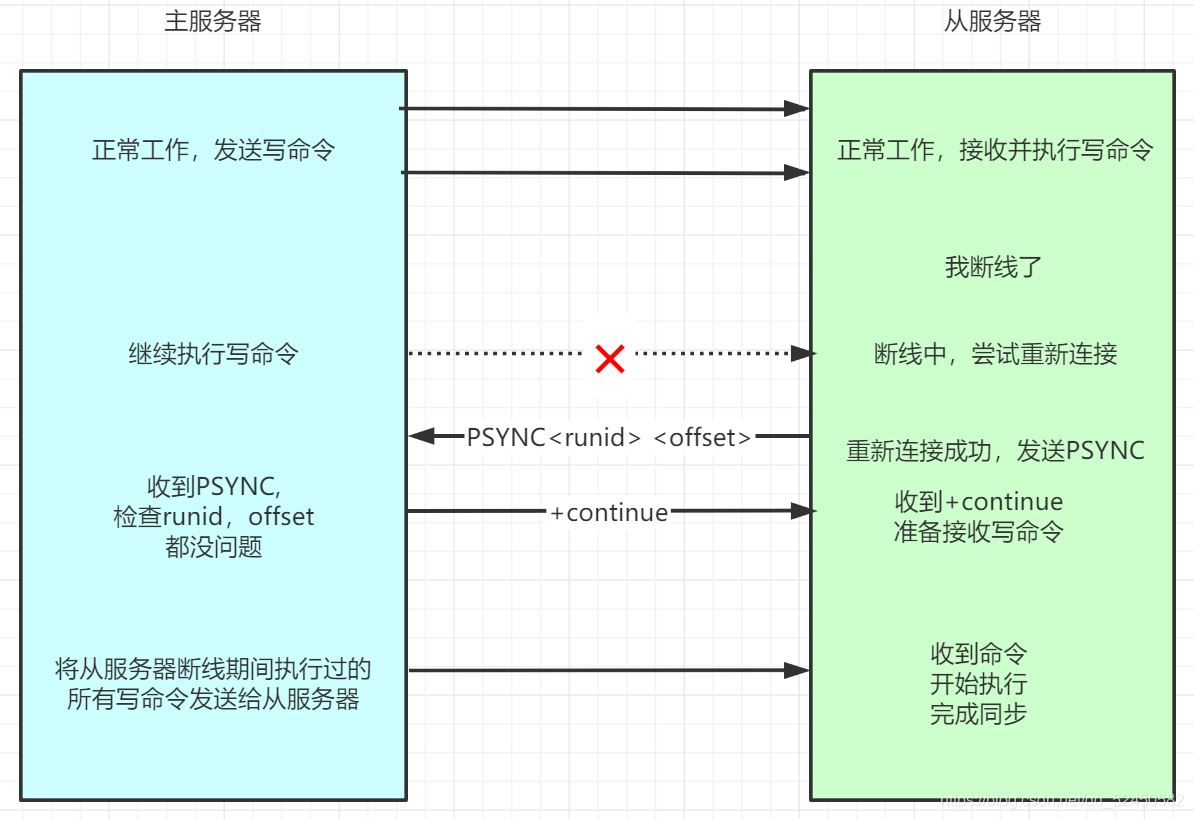
部分重同步
為了彌補舊版復制的缺陷,Redis從2.8版本開始使用PSYNC命令代替SYNC命令。PSYNC有完整重同步和部分重同步兩種模式,其中完整重同步和上述的舊版同步差不多,也是得發個rdb。但是部分重同步很牛X了:它可以只將斷線期間的寫入主服務器的寫命令發送給從服務器,耗費資源更少,速度也快的多。如下圖。
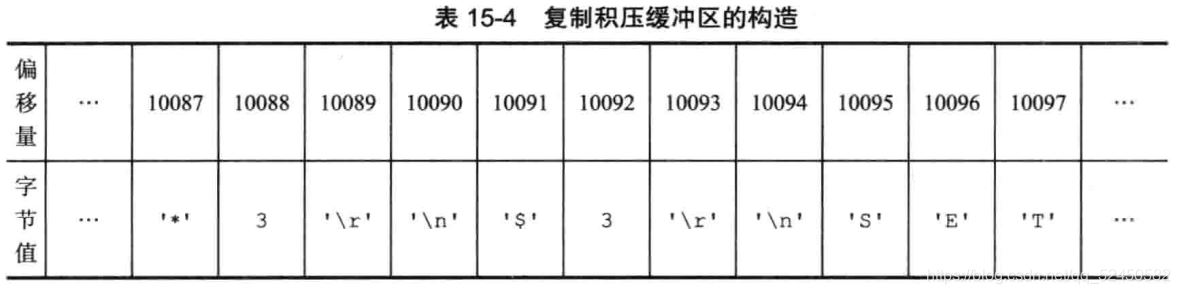
部分重同步的實現原理并不復雜,由三部分構成:復制偏移量(offset)、復制積壓緩沖區和服務器運行id(runid)
復制偏移量
復制偏移量是用來確認主從服務器的同步狀態的。主從服務器各自維護一份復制偏移量,當主服務器向從服務器發送了N個字節的數據時,就將自己的復制偏移量加上N;從服務器收到N個字節的數據也會將自己的復制偏移量加上N。通過比較主從雙方的復制偏移量就可以很容易的確認同步狀態。
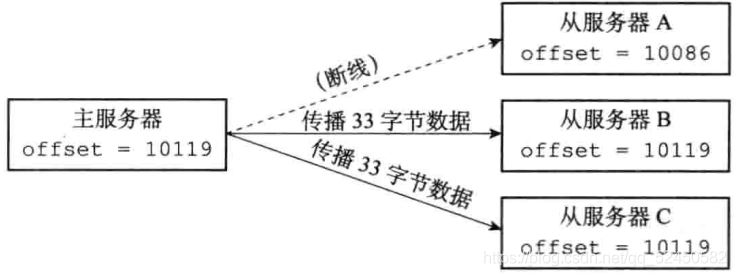
復制積壓緩沖區
復制積壓緩沖區是由主服務器維護的一個固定長度的先進先出的隊列,在主服務器進行命令傳播的時候會順道讓命令入隊到復制積壓緩沖區中,如下:
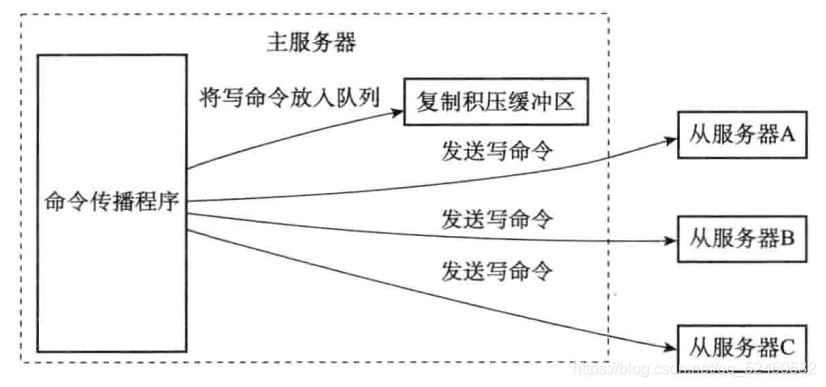
由于復制積壓緩沖區是一個固定長度的隊列,所以它只會保存最近一段時間內執行的寫命令,并為隊列中的每個字節記錄對應的復制偏移量。在從服務器發送PSYNC命令時,會攜帶上自己的復制偏移量,主服務器拿著這個偏移量去自己的復制積壓緩沖區中查看offset+1(即斷線后執行的下一個命令)還在不在隊列中。如果還在,表示可以執行部分重同步,后面會將從offset+1到隊尾的所有數據發送給從服務器;如果不在,那從服務器只能老老實實的去做完全重同步。
服務器運行Id
服務器運行Id說白了就是看主從服務器斷線之前是不是一家子。每一個redis服務器都有自己的運行id,主從初次連接時,主服務器會把自己的服務器運行id發送給從服務器保存起來,從服務器在重連接的時候會把之前保存的主服務器runid一并發給主服務器,主服務器會拿著這個runid和自己的runid進行比對。如果一致,則表示該從服務器之前確實是從自己這里斷線的,接下來進行偏移量的檢查;如果不一致,則表示這個從服務器先前是其他主服務器的slave,直接打去做完全重同步。
在之前執行info replication命令的時候就可以看到服務器運行id和復制偏移量。
綜上,一個新版redis復制的同步過程大致如下:
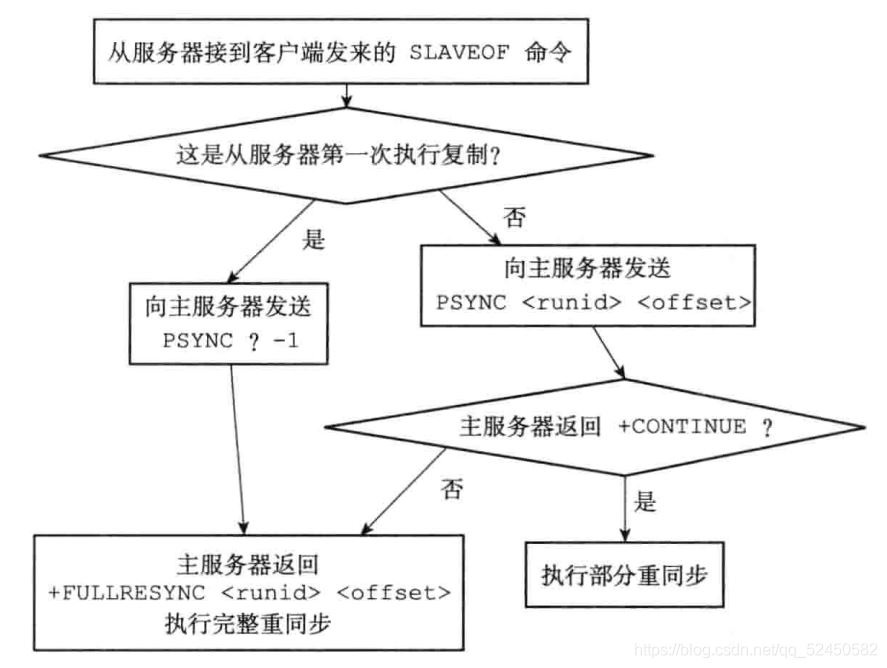
關于怎么在Redis中實現持久化與主從復制就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





