溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何在R語言中使用quantile()函數,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
> data <- c(1,2,3,4,5,6,7,8,9,10) > quantile(data,0.5) 50% 5.5 > quantile(data,c(0.25,0.75)) 25% 75% 3.25 7.75
> quantile(data,seq(0.1,1,0.1)) 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 1.9 2.8 3.7 4.6 5.5 6.4 7.3 8.2 9.1 10.0
> unname(quantile(data,seq(0.1,1,0.1))) [1] 1.9 2.8 3.7 4.6 5.5 6.4 7.3 8.2 9.1 10.0
補充:基于R語言的分位數回歸(quantile regression)
這一講,我們談談分位數回歸的知識,我想大家傳統回歸都經常見到。分位數回歸可能大家見的少一些,其實這個方法也很早了,大概78年代就有了,但是那個時候這個理論還不完善。到2005年的時候,分位數回歸的創立者Koenker R寫了一本分位數回歸的專著,劍橋大學出版社出版的。今年本來老爺子要出一本《handbook of quantile regression》,還沒有正式出來呢,目前來看,分位數回歸應用的范圍非常廣。在金融領域尤為重要。下面先給大家簡單介紹一下,分位數回歸的基本原理,完后拿R做一個完整的案例。為什么拿R軟件,因為分位數回歸的發明者最早拿R寫了一個包,叫quantreag,是當時唯一一個分位數回歸的包,現在的話,看到python,julia也有相關的包了。但是感覺這個R的還是最好的。
那么什么是分位數回歸呢,這個就要從傳統的回歸說起,傳統回歸呢,一般叫最小二乘回歸,也叫均值回歸。這個均值是指條件均值。比較抽象,在前面有一篇博文中,我比較詳細地解釋過。那么分位數回歸就是均值回歸的拓展,也就是它可以擬合均值以外的其它分位點,形成多條回歸線,這里首先需要強調的是分位數回歸的分位點是指因變量y的分位點,不是x的。這樣我們如果設定多個分位點就得到了多條回歸直線。當然分位數回歸現在也發展出來非線性分位數回歸,就是可以擬合出多條曲線,或者和廣義線性回歸模型一樣可以適用二值變量。要說分位數回歸具體的原理,后面有空再細談。下面我們拿R語言做一個案例,大家就可以逐漸感受到分位數回歸具體的含義了。
案例所用的數據呢,大家應該都比較熟悉,就是收入和食品消費支出的數據
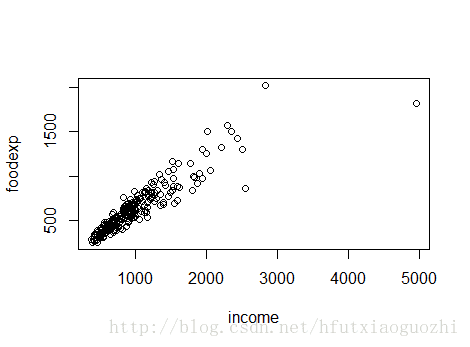
#導入分位數回歸的包 library(quantreg) # 引入數據 data(engel) #查看數據格式 mode(engel) [1] "list" #查看變量名 names(engel) [1] "income" "foodexp" #查看格式 class(engel) [1] "data.frame" #查看數據的前五行 head(engel) income foodexp 1 420.1577 255.8394 2 541.4117 310.9587 3 901.1575 485.6800 4 639.0802 402.9974 5 750.8756 495.5608 6 945.7989 633.7978 #畫個散點圖看看數據 plot(engel$income, engel$foodexp, xlab='income', ylab='foodexp')
圖是這樣的
下面我們繼續簡單查看一下數據
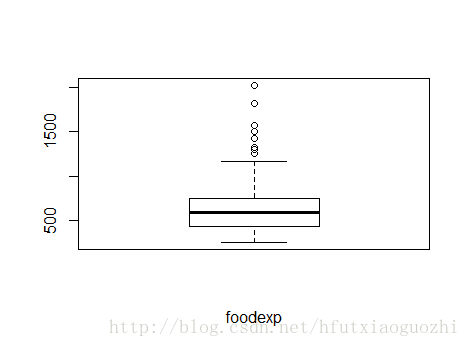
#查看foodexp的變化范圍 boxplot(engel$foodexp, xlab='foodexp') #簡單驗證一下因變量foodexp是否服從正態分布 qqnorm(engel$foodexp, main='QQ plot') qqline(engel$foodexp, col='red', lwd=2)
結果如下:
下面是QQ圖
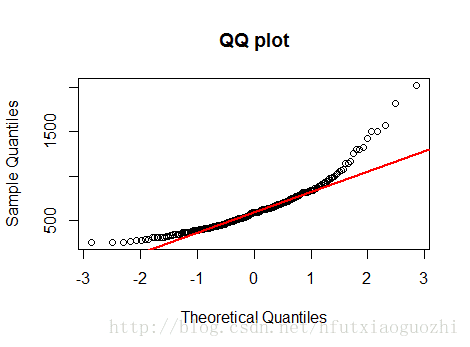
結果表明,因變量y明顯不服從正態分布,但是呢,分位數回歸不要求y服從正態分布,不僅如此,而且分位數回歸還對異常值點不敏感。
下面我們繼續,為了對比,我們仍然做一個均值回歸,再做一個分位數回歸。
#可以直接調用數據框里變量
attach(engel)
#設置0.05, 0.25, 0.5, 0.75, 0.95五個分位點,并且進行分位數回歸,這樣可以得到五條分位數回歸線
rq_result <- rq(foodexp ~ income, tau=c(0.05, 0.25, 0.5, 0.75, 0.95))
summary(rq_result)
Call: rq(formula = foodexp ~ income, tau = c(0.05, 0.25, 0.5, 0.75,
0.95))
tau: [1] 0.05
Coefficients:
coefficients lower bd upper bd
(Intercept) 124.88004 98.30212 130.51695
income 0.34336 0.34333 0.38975
Call: rq(formula = foodexp ~ income, tau = c(0.05, 0.25, 0.5, 0.75,
0.95))
tau: [1] 0.25
Coefficients:
coefficients lower bd upper bd
(Intercept) 95.48354 73.78608 120.09847
income 0.47410 0.42033 0.49433
Call: rq(formula = foodexp ~ income, tau = c(0.05, 0.25, 0.5, 0.75,
0.95))
tau: [1] 0.5
Coefficients:
coefficients lower bd upper bd
(Intercept) 81.48225 53.25915 114.01156
income 0.56018 0.48702 0.60199
Call: rq(formula = foodexp ~ income, tau = c(0.05, 0.25, 0.5, 0.75,
0.95))
tau: [1] 0.75
Coefficients:
coefficients lower bd upper bd
(Intercept) 62.39659 32.74488 107.31362
income 0.64401 0.58016 0.69041
Call: rq(formula = foodexp ~ income, tau = c(0.05, 0.25, 0.5, 0.75,
0.95))
tau: [1] 0.95
Coefficients:
coefficients lower bd upper bd
(Intercept) 64.10396 46.26495 83.57896
income 0.70907 0.67390 0.73444
#上面就是沒條回歸線的回歸系數,我們做個圖看一下
plot(income, foodexp, cex=0.25, type='n', xlab='income', ylab='foodexp')
points(income, foodexp, cex=0.5, col='blue')
#加中位數數回歸的直線
abline(rq(foodexp~income, tau=0.5), col='blue')
#加均值回歸的五條直線
abline(lm(foodexp~income), lty=2, col='red')
#將分位數回歸的五條線加上去
taus <- c(0.05, 0.1, 0.25, 0.75, 0.9, 0.95)
#
for (i in 1:length(taus)){
abline(rq(foodexp~income, tau=taus[i]), col='gray')
}效果如下:
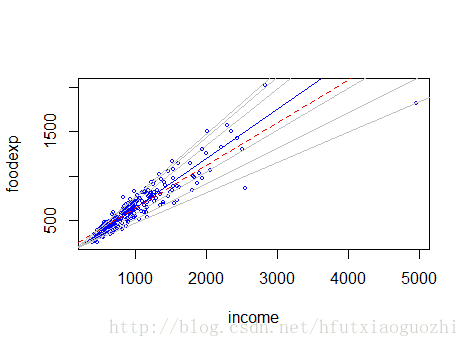
上述就是小編為大家分享的如何在R語言中使用quantile()函數了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





