溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python如何通過分隔符分割文件后按特定次序重新組合的操作,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
#-*-encoding:utf-8-*-
import os, sys, time, datetime, glob
fo1 = open("C:/Users/Administrator/Desktop/areainfo.txt", "w")
fo2 = open("C:/Users/Administrator/Desktop/personinfo.txt", "w")
for root, dirs, files, in os.walk("E:/test", topdown=False):
for name in files:
file_name = os.path.join(root,name)
if os.path.splitext(file_name)[1] == '.txt':
print(file_name)
with open(file_name) as a_file:
for data in a_file.readlines():
str2=[]
str4=[]
for i in [0, 1, 2, 3, 7]:
str2.append(data.split('||~||')[i])
fo1.write("||~||".join(str2)+"\n")
for i in [4, 5, 6, 7, 8, 9, 10, 11]:
str4.append(data.split('||~||')[i])
fo2.write("||~||".join(str4)+"\n")
fo1.close()
fo2.close()補充:python按照某個分隔符切分text文件字符串并存入excel
有一份如圖所示的文件信息,信息量較大需要將text文件轉為excel處理,按照圖中的分隔符“&”分列數據存儲至excel文件。

# -*- coding: utf-8 -*-
"""
Created on Mon Mar 30 18:05:35 2020
@author: fengzi
"""
import os
import pandas as pd
from datetime import datetime
def main():
source_dir = 'E:/服管部/滿意度調研/滿意度影響因子分析/3.18\BI提單數據/BI2020031700005分開/分列測試/集團成員.txt'
target_dir = 'E:/服管部/滿意度調研/滿意度影響因子分析/3.18\BI提單數據/BI2020031700005分開/分列測試/集團成員.xlsx'
new_colums = "look\r\n"
start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("開始時間:",start_time)
#文件開頭增加新的一列內容作為列名(原列名太長/不可用)
f = open(source_dir, 'r')
content = f.read() # 讀取文件內容
f_new = open('b.txt', 'w')
f_new.write(new_colums) # 開頭寫入內容并換行
f_new.write(content) # 寫入原文件內容
f_list=list(set(f.readlines())) #先把內容readlines()為列表,然后用set集合去重后再轉化為列表,賦值于變量f_list
for i in f_list: #for循環列表f_list,判斷是否有“\n”字符,如果有,將元素‘\n'移除
if i=='\n':
f_list.remove(i)
f_new.writelines(f_list) #將列表f_list的內容(此時列表已去除換行空白行),通過writelines的方式寫入新文件,
f.close()
f_new.close()
os.remove(source_dir) # 移除老文件
os.rename('b.txt', source_dir) # 新文件命名為老文件名
data = pd.read_csv(source_dir,"rb",engine='python') #讀入數據出現亂碼可添加engine='python'
#字符串切分后結果分列展示
df = pd.DataFrame(data, columns=["look"]) #需要分列的列名
df=df["look"].str.split('&', expand=True) # 分列的字符,split默認輸出list,設置expand=True結果會分列展示
#print(df)
df.to_excel(target_dir) #列表df存儲至excel
end_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("完成時間",end_time)
if __name__ == "__main__":
main()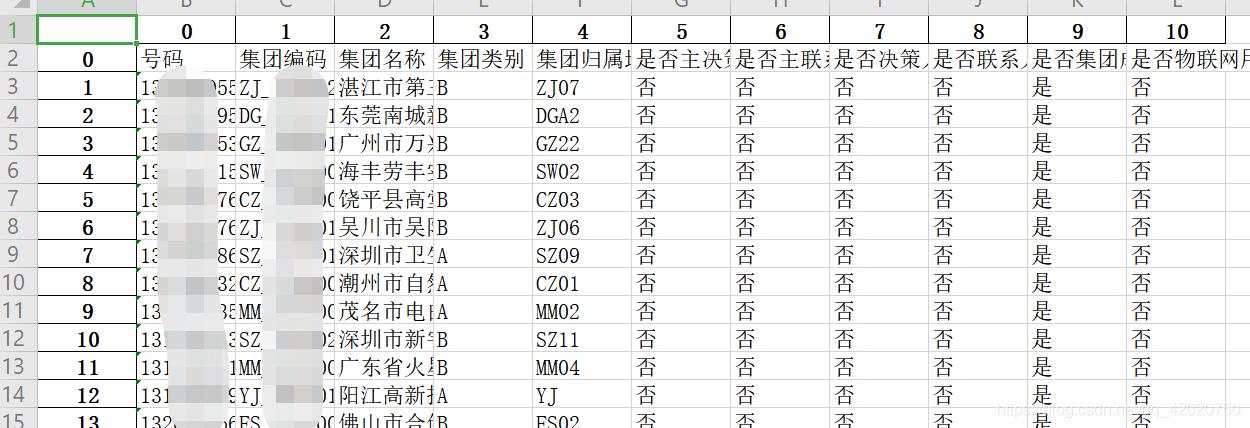
此代碼的缺陷是實現效果不佳,增加了首列和首行的序號,后期有時間再學著改善。
以上是“Python如何通過分隔符分割文件后按特定次序重新組合的操作”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





