溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下pandas怎么使用merge實現百倍加速的操作,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
先生成一串目標時間序列,從某個開始日到今天為止,每七天一個日期。
把這些日期map到數據集的日期, Eg. {“2019-06-18”:“2019-06-15”…} 。
把map到的數據抽出來用pd.concat接起來。
target_dates = pd.date_range(end=now, periods=100, freq="7D") full_dates = pd.date_range(start, now).tolist() org_dates = df.date.tolist() last_date = None for d in full_dates: if d in org_dates: date_map[d] = d last_date = d elif last_date is not None: date_map[d] = last_date else: continue new_df = pd.DataFrame() for td in target_dates: new_df = pd.concat([new_df, df[df["date"]==date_map[td]])
這樣的一個算法處理一個接近千萬量級的數據集上大概需要十多分鐘。仔細檢查發現,每一次合并的dataframe數據量并不小,而且總的操作次數達到上萬次。
所以就想如何避免高頻次地使用pd.concat去合并dataframe。
最終想到了一個巧妙的方法,只需要修改一下前面的第三步,把日期的map轉換成dataframe,然后和原始數據集做merge操作就可以了。
target_dates = pd.date_range(end=now, periods=100, freq="7D")
full_dates = pd.date_range(start, now).tolist()
org_dates = df.date.tolist()
last_date = None
for d in full_dates:
if d in org_dates:
date_map[d] = d
last_date = d
elif last_date is not None:
date_map[d] = last_date
else:
continue
#### main change is from here #####
date_map_list = []
for td in target_dates:
date_map_list.append({"target_date":td, "org_date":date_map[td]})
date_map_df = pd.DataFrame(date_map_list)
new_df = date_map_df.merge(df, left_on=["org_date"], right_on=["date"], how="inner")改進之后,所有的循環操作都在一個微數量級上,最后一個merge操作得到了所有有用的數據,運行時間在5秒左右,大大提升了性能。
補充:Pandas DataFrames 中 merge 合并的坑點(出現重復連接鍵)
在我的實際開發中遇到的坑點,查閱了相關文檔 總結一下
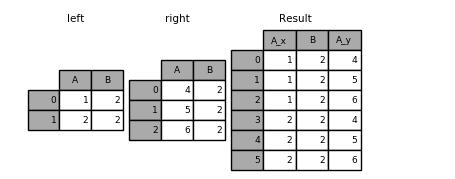
left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
result = pd.merge(left, right, on='B', how='outer')
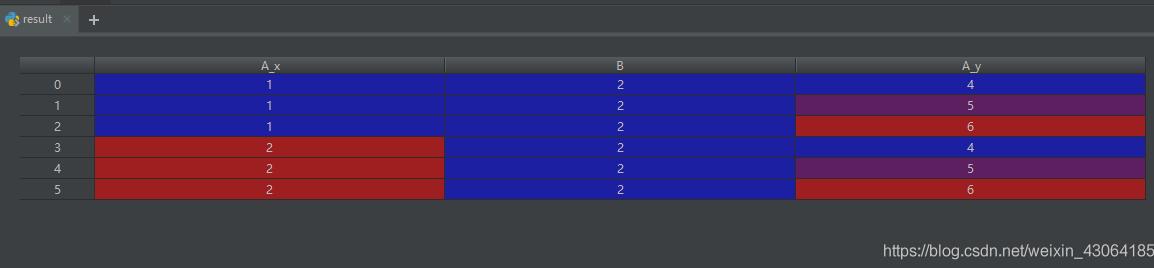
警告:在重復鍵上加入/合并可能導致返回的幀是行維度的乘法,這可能導致內存溢出。在加入大型DataFrame之前,重復值。
檢查重復鍵
如果知道右側的重復項DataFrame但希望確保左側DataFrame中沒有重復項,則可以使用該 validate='one_to_many'參數,這不會引發異常。
pd.merge(left, right, on='B', how='outer', validate="one_to_many") # 打印的結果: A_x B A_y 0 1 1 NaN 1 2 2 4.0 2 2 2 5.0 3 2 2 6.0
參數:
validate : str, optional If specified, checks if merge is of specified type. “one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets. “one_to_many” or “1:m”: check if merge keys are unique in left dataset. “many_to_one” or “m:1”: check if merge keys are unique in right dataset. “many_to_many” or “m:m”: allowed, but does not result in checks.
看完了這篇文章,相信你對“pandas怎么使用merge實現百倍加速的操作”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





