溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如果想要大規模抓取數據,那么一定會用到分布式爬蟲,對于分布式爬蟲來說,我們一定需要多臺主機,每臺主機多個爬蟲任務,但是源代碼其實只有一份。那么我們需要做的就是將一份代碼同時部署到多臺主機上來協同運行,那么怎么去部署就又是一個值得思考的問題。
對于 Scrapy 來說,它有一個擴展組件叫做 Scrapyd,我們只需要安裝 Scrapyd 即可遠程管理 Scrapy 任務,包括部署源碼、啟動任務、監聽任務等操作。另外還有 ScrapydClient 和 ScrapydAPI 來幫助我們更方便地完成部署和監聽操作。
另外還有一種部署方式就是 Docker 集群部署,我們只需要將爬蟲制作為 Docker 鏡像,只要主機安裝了 Docker,就可以直接運行爬蟲,而無需再去擔心環境配置、版本問題。
本節我們就來介紹一下相關環境的配置過程。
Docker 是一種容器技術,它可以將應用和環境等進行打包,形成一個獨立的,類似于 iOS 的 APP 形式的「應用」,這個應用可以直接被分發到任意一個支持 Docker 的環境中,通過簡單的命令即可啟動運行。Docker 是一種最流行的容器化實現方案。和虛擬化技術類似,它極大的方便了應用服務的部署;又與虛擬化技術不同,它以一種更輕量的方式實現了應用服務的打包。使用 Docker 可以讓每個應用彼此相互隔離,在同一臺機器上同時運行多個應用,不過他們彼此之間共享同一個操作系統。Docker 的優勢在于,它可以在更細的粒度上進行資源的管理,也比虛擬化技術更加節約資源。Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎
本段參考:DaoCloud官方文檔
對于爬蟲來說,如果我們需要大規模部署爬蟲系統的話,用 Docker 會大大提高效率,工欲善其事,必先利其器。
本節來介紹一下三大平臺下 Docker 的安裝方式。
詳細的分步驟的安裝說明可以參見官方文檔:https://docs.docker.com/engin...。
在官方文檔中詳細說明了不同 Linux 系統的安裝方法,安裝流程根據文檔一步步執行即可安裝成功。
但是為了使得安裝更加方便,Docker 官方還提供了一鍵安裝腳本,使用它會使得安裝更加便捷,不用再去一步步執行命令安裝了,在此介紹一下一鍵腳本安裝方式。
首先是 Docker 官方提供的安裝腳本,相比其他腳本,官方提供的一定更靠譜,安裝命令如下:
curl -sSL https://get.docker.com/ | sh只要執行如上一條命令,等待一會兒 Docker 便會安裝完成,非常方便。
但是官方腳本安裝有一個缺點,那就是慢,也可能下載超時,所以為了加快下載速度,我們可以使用國內的鏡像來安裝,所以在這里還有阿里云和 DaoCloud 的安裝腳本。
阿里云安裝腳本:
curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -DaoCloud 安裝腳本:
curl -sSL https://get.daocloud.io/docker | sh兩個腳本可以任選其一,速度都非常不錯。
等待腳本執行完畢之后,就可以使用 Docker 相關命令了,如運行測試 Hello World 鏡像:
docker run hello-world運行結果:
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
78445dd45222: Pull complete
Digest: sha256:c5515758d4c5e1e838e9cd307f6c6a0d620b5e07e6f927b07d05f6d12a1ac8d7
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.如果出現上文類似提示內容則證明 Docker 可以正常使用了。
Mac 平臺同樣有兩種選擇,Docker for Mac 和 Docker Toolbox。
Docker for Mac 要求系統為 OS X EI Captain 10.11 或更新,至少 4GB 內存,如果你的系統滿足此要求,則強烈建議安裝 Docker for Mac。
可以使用 HomeBrew 安裝,安裝命令如下:
brew cask install docker
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎另外也可以手動下載安裝包安裝,安裝包下載地址為:https://download.docker.com/m...
下載完成之后直接雙擊安裝包,然后將程序拖動到應用程序中即可。
點擊程序圖標運行 Docker,會發現在菜單欄中出現了 Docker 的圖標,如圖 1-83 中的第三個小鯨魚圖標:

圖 1-83 菜單欄
點擊圖標展開菜單之后,再點擊 Start 按鈕即可啟動 Docker,啟動成功便會提示 Docker is running,如圖 1-84 所示:
圖 1-84 運行頁面
隨后我們就可以在命令行下使用 Docker 命令了。
可以使用如下命令測試運行:
sudo docker run hello-world運行結果如圖 1-85 所示:
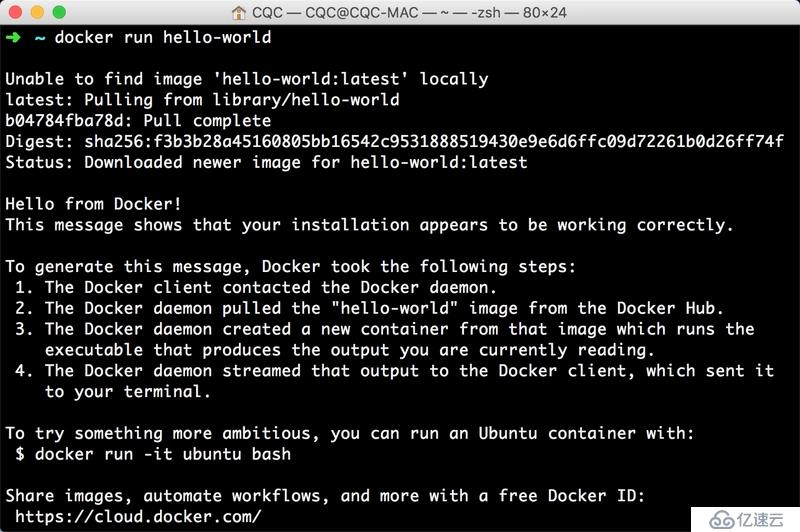
圖 1-85 運行結果
如果出現類似輸出則證明 Docker 已經成功安裝。
如果系統不滿足要求,可以下載 Docker Toolbox,其安裝說明為:https://docs.docker.com/toolb...。
關于 Docker for Mac 和 Docker Toolbox 的區別,可以參見:https://docs.docker.com/docke...。
安裝好 Docker 之后,在運行測試命令時,我們會發現它首先會下載一個 Hello World 的鏡像,然后將其運行,但是下載速度有時候會非常慢,這是因為它默認還是從國外的 Docker Hub 下載的,所以為了提高鏡像的下載速度,我們還可以使用國內鏡像來加速下載,所以這就有了 Docker 加速器一說。
推薦的 Docker 加速器有 DaoCloud 和阿里云。
DaoCloud:https://www.daocloud.io/mirror
阿里云:https://cr.console.aliyun.com...
不同平臺的鏡像加速方法配置可以參考 DaoCloud 的官方文檔:http://guide.daocloud.io/dcs/...。
配置完成之后,可以發現鏡像的下載速度會快非常多。
以上便是 Docker 的安裝方式說明。
Scrapyd 是一個用于部署和運行 Scrapy 項目的工具。有了它,你可以將寫好的 Scrapy 項目上傳到云主機并通過 API 來控制它的運行。
既然是 Scrapy 項目部署,所以基本上都使用 Linux 主機,所以本節的安裝是針對于 Linux 主機的。
推薦使用 Pip 安裝,命令如下:
pip3 install scrapyd安裝完畢之后需要新建一個配置文件 /etc/scrapyd/scrapyd.conf,Scrapyd 在運行的時候會讀取此配置文件。
在 Scrapyd 1.2 版本之后不會自動創建該文件,需要我們自行添加。
執行命令新建文件:
sudo mkdir /etc/scrapyd
sudo vi /etc/scrapyd/scrapyd.conf寫入如下內容:
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus配置文件的內容可以參見官方文檔:https://scrapyd.readthedocs.i...,在這里的配置文件有所修改,其中之一是 max_proc_per_cpu 官方默認為 4,即一臺主機每個 CPU 最多運行 4 個Scrapy Job,在此提高為 10,另外一個是 bind_address,默認為本地 127.0.0.1,在此修改為 0.0.0.0,以使外網可以訪問。
由于 Scrapyd 是一個純 Python 項目,在這里可以直接調用 scrapyd 來運行,為了使程序一直在后臺運行,Linux 和 Mac 可以使用如下命令:
(scrapyd > /dev/null &)這樣 Scrapyd 就會在后臺持續運行了,控制臺輸出直接忽略,當然如果想記錄輸出日志可以修改輸出目標,如:
(scrapyd > ~/scrapyd.log &)則會輸出 Scrapyd 運行輸出到 ~/scrapyd.log 文件中。
運行之后便可以在瀏覽器的 6800 訪問 WebUI 了,可以簡略看到當前 Scrapyd 的運行 Job、Log 等內容,如圖 1-86 所示:
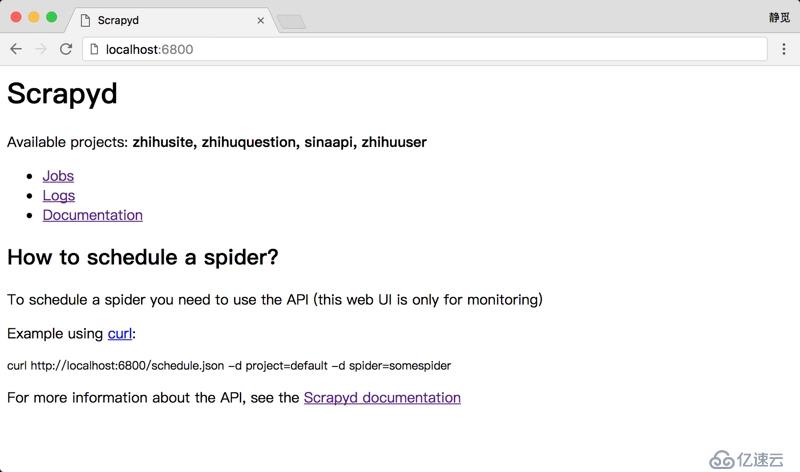
圖 1-86 Scrapyd 首頁
當然運行 Scrapyd 更佳的方式是使用 Supervisor 守護進程運行,如果感興趣可以參考:http://supervisord.org/。
另外 Scrapyd 也支持 Docker,在后文我們會介紹 Scrapyd Docker 鏡像的制作和運行方法。
限制配置完成之后 Scrapyd 和它的接口都是可以公開訪問的,如果要想配置訪問認證的話可以借助于 Nginx 做反向代理,在這里需要先安裝 Nginx 服務器。
在此以 Ubuntu 為例進行說明,安裝命令如下:
sudo apt-get install nginx然后修改 Nginx 的配置文件 nginx.conf,增加如下配置:
http {
server {
listen 6801;
location / {
proxy_pass http://127.0.0.1:6800/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}在這里使用的用戶名密碼配置放置在 /etc/nginx/conf.d 目錄,我們需要使用 htpasswd 命令創建,例如創建一個用戶名為 admin 的文件,命令如下:
htpasswd -c .htpasswd admin接下就會提示我們輸入密碼,輸入兩次之后,就會生成密碼文件,查看一下內容:
cat .htpasswd
admin:5ZBxQr0rCqwbc配置完成之后我們重啟一下 Nginx 服務,運行如下命令:
sudo nginx -s reload
Python資源分享qun 784758214 ,內有安裝包,PDF,學習視頻,這里是Python學習者的聚集地,零基礎,進階,都歡迎這樣就成功配置了 Scrapyd 的訪問認證了。
本節介紹了 Scrapyd 的安裝方法,在后文我們會詳細了解到 Scrapy 項目的部署及項目運行狀態監控方法。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





