溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Pandas有三種主要數據結構,Series、DataFrame、Panel。
Series是帶有標簽的一維數組,可以保存任何數據類型(整數,字符串,浮點數,Python對象等),軸標簽統稱為索引(index)。
DataFrame是帶有標簽的二維數據結構,具有index(行標簽)和columns(列標簽)。如果傳遞index或columns,則會用于生成的DataFrame的index或columns。
Panel是一個三維數據結構,由items、major_axis、minor_axis定義。items(條目),即軸0,每個條目對應一個DataFrame;major_axis(主軸),即軸1,是每個DataFrame的index(行);minor_axis(副軸),即軸2,是每個DataFrame的columns(列)。
Series是能夠保存任何類型數據(整數,字符串,浮點數,Python對象等)的一維標記數組,軸標簽統稱為index(索引)。
series是一種一維數據結構,每一個元素都帶有一個索引,其中索引可以為數字或字符串。Series結構名稱: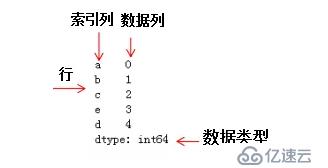
Series構造函數如下:pandas.Series( data, index, dtype, copy)
data:構建Series的數據,可以是ndarray,list,dict,constants。
index:索引值必須是唯一的和散列的,與數據的長度相同。 如果沒有索引被傳遞,默認為np.arange(n)。
dtype:數據類型,如果沒有,將推斷數據類型。
copy:是否復制數據,默認為false。
(1)創建一個空的 Series
import pandas as pd
if __name__ == "__main__":
s = pd.Series()
print(s)
# output:
# Series([], dtype: float64)(2)使用ndarray創建Series
使用ndarray作為數據時,傳遞的索引必須與ndarray具有相同的長度。 如果沒有傳遞索引值,那么默認的索引是range(n),其中n是數組長度,即[0,1,2,3…. range(len(array))-1] - 1]。
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = np.array(['a', 1, 2, 4, 6])
s = pd.Series(data,index=[101, 102, 103, 'hello', 'world'])
print(s)
# output:
# 101 a
# 102 1
# 103 2
# hello 4
# world 6
# dtype: object不傳遞任何索引時,默認分配從0到len(data)-1的索引。
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = np.array(['a', 1, 2, 4, 6])
s = pd.Series(data)
print(s)
# output:
# 0 a
# 1 1
# 2 2
# 3 4
# 4 6
# dtype: object(3)使用字典創建Series
使用字典(dict)作為數據時,如果沒有指定索引,則按排序順序取得字典鍵以構造索引。 如果傳遞索引,索引中與標簽對應的數據中的值將被取出。
import pandas as pd
if __name__ == "__main__":
data = {'a': 1, 2: 'hello', 'b': 'hello world'}
s = pd.Series(data)
print(s)
# output:
# a 1
# 2 hello
# b hello world
# dtype: object傳遞索引時,索引順序保持不變,缺少的元素使用NaN(不是數字)填充。
import pandas as pd
if __name__ == "__main__":
data = {'a': 1, 2: 'hello', 'b': 'hello world', "hello": "world"}
s = pd.Series(data, index=['a', 'b', "hello", 'd'])
print(s)
# output:
# a 1
# b hello world
# hello world
# d NaN
# dtype: object(4)使用標量創建Series
使用標量值作為數據,則必須提供索引,會重復標量值以匹配索引的長度。
import pandas as pd
if __name__ == "__main__":
s = pd.Series(100, index=[1, 2, 3])
print(s)
# output:
# 1 100
# 2 100
# 3 100
# dtype: int64(5)使用list、tuple創建Series
使用list、tuple作為數據時,傳遞的索引必須與list、tuple具有相同的長度。 如果沒有傳遞索引值,那么默認的索引是range(n),其中n是list的長度,即[0,1,2,3…. range(len(list))-1] - 1]。
import pandas as pd
if __name__ == "__main__":
s = pd.Series([1, 2, 3, "hello"])
print(s)
# output:
# 0 1
# 1 2
# 2 3
# 3 hello
# dtype: objectSeries中的數據可以使用有序序列的方式進行訪問。
import pandas as pd
if __name__ == "__main__":
s = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s[0])
print(s[-1])
print(s[-3:])
# output:
# 1
# 5
# c 3
# d 4
# e 5
# dtype: int64Series像一個固定大小的字典,可以通過索引標簽獲取和設置值,使用索引標簽值檢索單個元素,使用索引標簽值列表檢索多個元素。如果使用不包含在索引內的標簽,則會出現異常。
import pandas as pd
if __name__ == "__main__":
s = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
s['a'] = 101
print(s['a'])
print(s[0])
print(s[['a', 'b', 'e']])
# output:
# 101
# 101
# a 101
# b 2
# e 5
# dtype: int64Series對象的屬性和方法如下:
Series.axes:返回行軸標簽列表
Series.dtype:返回對象的數據類型
Series.empty:如果對象為空,返回True
Series.ndim:返回底層數據的維數,默認為1
Series.size:返回基礎數據中的元素數
Series.values:將對象作為ndarray返回
Series.head():返回前n行
Series.tail():返回后n行
import pandas as pd
if __name__ == "__main__":
s = pd.Series(["Bauer", 30, 90], index=['Name', 'Age', 'Score'])
print("Series=================")
print(s)
print("axes===================")
print(s.axes)
print("dtype==================")
print(s.dtype)
print("empty==================")
print(s.empty)
print("ndim===================")
print(s.ndim)
print("size===================")
print(s.size)
print("values=================")
print(s.values)
print("head()=================")
print(s.head(2))
print("tail()=================")
print(s.tail(2))
# output:
# Series=================
# Name Bauer
# Age 30
# Score 90
# dtype: object
# axes===================
# [Index(['Name', 'Age', 'Score'], dtype='object')]
# dtype==================
# object
# empty==================
# False
# ndim===================
# 1
# size===================
# 3
# values=================
# ['Bauer' 30 90]
# head()=================
# Name Bauer
# Age 30
# dtype: object
# tail()=================
# Age 30
# Score 90
# dtype: object數據幀(DataFrame)是二維的表格型數據結構,即數據以行和列的表格方式排列,DataFrame是Series的容器。
DataFrame的結構名稱如下: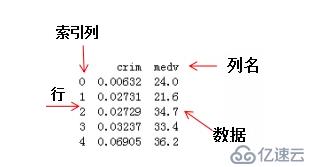
數據幀(DataFrame)的功能特點如下:
(1)底層數據列是不同的類型
(2)大小可變
(3)標記軸(行和列)
(4)可以對行和列執行算術運算
pandas.DataFrame( data, index, columns, dtype, copy)
data:構建DataFrame的數據,可以是ndarray,series,map,lists,dict,constant和其它DataFrame。
index:行索引標簽,如果沒有傳遞索引值,索引默認為np.arrange(n)。
columns:列索引標簽,如果沒有傳遞索列引值,默認列索引是np.arange(n)。
dtype:每列的數據類型。
copy:如果默認值為False,則此命令(或任何它)用于復制數據。
(1)創建空的DataFrame
import pandas as pd
if __name__ == "__main__":
df = pd.DataFrame()
print(df)
# output:
# Empty DataFrame
# Columns: []
# Index: [](2)使用list創建DataFrame
使用單個列表或嵌套列表作為數據創建DataFrame時,如果不指定index或columns,默認使用range(len(list))作為index,對于單列表,默認columns=[0],對于嵌套列表,默認columns為內層列表的長度的range。
import pandas as pd
if __name__ == "__main__":
data = [1, 2, 3, 4, 5]
df = pd.DataFrame(data)
print(df)
df = pd.DataFrame(data, index=['a', 'b', 'c', 'h', 'e'], columns=['A'])
print(df)
# output:
# 0
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# A
# a 1
# b 2
# c 3
# h 4
# e 5指定index或columns時,index的長度必須與list長度匹配,columns的長度必須與list的內層列表長度匹配,否則將報錯。
import pandas as pd
if __name__ == "__main__":
data = [['Alex', 25], ['Bob', 26], ['Bauer', 24]]
df = pd.DataFrame(data, columns=['Name', 'Age'])
print(df)
df = pd.DataFrame(data, columns=['Name', 'Age'], dtype=float)
print(df)
# output:
# Name Age
# 0 Alex 25
# 1 Bob 26
# 2 Bauer 24
# Name Age
# 0 Alex 25.0
# 1 Bob 26.0
# 2 Bauer 24.0(3)使用ndarray和list的字典創建DataFrame
使用ndarray、list組成的字典作為數據創建DataFrame時,所有的ndarray、list必須具有相同的長度。如果傳遞index,則index的長度必須等于ndarray、list的長度,columns為字典的key組成的集合。如果沒有傳遞index,則默認情況下,index將為range(n),其中n為list或ndarray長度。
import pandas as pd
if __name__ == "__main__":
data = {'Name': ['Tom', 'Jack', 'Steve', 'Ricky'], 'Age': [28, 34, 29, 42]}
df = pd.DataFrame(data)
print(df)
df = pd.DataFrame(data, index=['rank1', 'rank2', 'rank3', 'rank4'])
print(df)
# output:
# Name Age
# 0 Tom 28
# 1 Jack 34
# 2 Steve 29
# 3 Ricky 42
# Name Age
# rank1 Tom 28
# rank2 Jack 34
# rank3 Steve 29
# rank4 Ricky 42(4)使用字典列表創建DataFrame
使用字典列表作為數據創建DataFrame時,默認使用range(len(list))作為index,字典鍵的集合作為columns,如果字典沒有相應鍵值對,其值使用NaN填充。當指定columns時,如果columns使用字典鍵集合以外元素作為columns的元素,則使用NaN進行填充,并提取出columns指定的數據源字典中相應的鍵值對。
import pandas as pd
if __name__ == "__main__":
data = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print(df)
df = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b', 'c', 'A', 'B'])
print(df)
# output:
# a b c
# 0 1 2 NaN
# 1 5 10 20.0
# a b c A B
# first 1 2 NaN NaN NaN
# second 5 10 20.0 NaN NaN(5)使用Series字典創建DataFrame
使用Series字典作為數據創建DataFrame時,得到的DataFrame的index是所有Series的index的并集,字典鍵的集合作為columns。
import pandas as pd
if __name__ == "__main__":
data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data, columns=['one', 'two'])
print(df)
df = pd.DataFrame(data, columns=['one', 'two', 'three'])
print(df)
df = pd.DataFrame(data, index=['a', 'b', 'c', 'A'], columns=['one', 'two', 'three'])
print(df)
# output:
# one two
# a 1.0 1
# b 2.0 2
# c 3.0 3
# d NaN 4
# one two three
# a 1.0 1 NaN
# b 2.0 2 NaN
# c 3.0 3 NaN
# d NaN 4 NaN
# one two three
# a 1.0 1.0 NaN
# b 2.0 2.0 NaN
# c 3.0 3.0 NaN
# A NaN NaN NaN通過字典鍵可以進行列選擇,獲取DataFrame中的一列數據。
import pandas as pd
if __name__ == "__main__":
data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data, columns=['one', 'two'])
print(df)
print(df['one'])
# output:
# one two
# a 1.0 1
# b 2.0 2
# c 3.0 3
# d NaN 4
# a 1.0
# b 2.0
# c 3.0
# d NaN
# Name: one, dtype: float64通過向DataFrame增加相應的鍵和Series值,可以為DataFrame增加一列。
import pandas as pd
if __name__ == "__main__":
data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data, columns=['one', 'two'])
print(df)
df['three'] = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(df)
df['four'] = df['one'] + df['three']
print(df)
# output:
# one two
# a 1.0 1
# b 2.0 2
# c 3.0 3
# d NaN 4
# one two three
# a 1.0 1 10.0
# b 2.0 2 20.0
# c 3.0 3 30.0
# d NaN 4 NaN
# one two three four
# a 1.0 1 10.0 11.0
# b 2.0 2 20.0 22.0
# c 3.0 3 30.0 33.0
# d NaN 4 NaN NaN通過del可以刪除DataFrame的列。
import pandas as pd
if __name__ == "__main__":
data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three': pd.Series([10, 20, 30], index=['a', 'b', 'c'])}
df = pd.DataFrame(data, columns=['one', 'two', 'three'])
print(df)
del(df['two'])
print(df)
# output:
# one two three
# a 1.0 1 10.0
# b 2.0 2 20.0
# c 3.0 3 30.0
# d NaN 4 NaN
# one three
# a 1.0 10.0
# b 2.0 20.0
# c 3.0 30.0
# d NaN NaNDataFrame行選擇可以通過將行標簽傳遞給loc函數來選擇行,也可以通過將整數位置傳遞給iloc()函數來選擇行,返回Series,Series的名稱是檢索的標簽,Series的index為DataFrame的columns。
import pandas as pd
if __name__ == "__main__":
data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three': pd.Series([10, 20, 30], index=['a', 'b', 'c'])}
df = pd.DataFrame(data, columns=['one', 'two', 'three'])
print(df.loc['a'])
print(df.iloc[0])
# output:
# one 1.0
# two 1.0
# three 10.0
# Name: a, dtype: float64
# one 1.0
# two 1.0
# three 10.0
# Name: a, dtype: float64DataFrame多行選擇可以通過使用:運算符對DataFrame進行行切片操作,選擇多行。
import pandas as pd
if __name__ == "__main__":
data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three': pd.Series([10, 20, 30], index=['a', 'b', 'c'])}
df = pd.DataFrame(data, columns=['one', 'two', 'three'])
print(df)
print(df[2:4])
# output:
# one two three
# a 1.0 1 10.0
# b 2.0 2 20.0
# c 3.0 3 30.0
# d NaN 4 NaN
# one two three
# c 3.0 3 30.0
# d NaN 4 NaNDataFrame的行追加通過append函數實現。
import pandas as pd
if __name__ == "__main__":
df = pd.DataFrame([["Bauer", 20], ["Jack", 30]], index=["rank1", "rank2"], columns=['Name', 'Age'])
df2 = pd.DataFrame([["Alex", 18], ["Bob", 28]], index=["rank3", "rank3"], columns=['Name', 'Age'])
df = df.append(df2)
print(df)
# output:
# Name Age
# rank1 Bauer 20
# rank2 Jack 30
# rank3 Alex 18
# rank3 Bob 28DataFrame的行刪除通過將索引標簽傳遞給drop函數進行行刪除, 如果標簽重復,則會刪除多行。
import pandas as pd
if __name__ == "__main__":
df = pd.DataFrame([["Bauer", 20], ["Jack", 30]], index=["rank1", "rank2"], columns=['Name', 'Age'])
df2 = pd.DataFrame([["Alex", 18], ["Bob", 28]], index=["rank3", "rank3"], columns=['Name', 'Age'])
df = df.append(df2)
print(df)
df = df.drop("rank2")
print(df)
# output:
# Name Age
# rank1 Bauer 20
# rank2 Jack 30
# rank3 Alex 18
# rank3 Bob 28
# Name Age
# rank1 Bauer 20
# rank3 Alex 18
# rank3 Bob 28DataFrame對象的屬性和方法如下:
DataFrame.T:轉置行和列
DataFrame.axes:返回一個列,行軸標簽和列軸標簽作為唯一的成員。
DataFrame.dtypes:返回對象的數據類型
DataFrame.empty:如果NDFrame完全為空,返回True
DataFrame.ndim:返回軸/數組維度的大小
DataFrame.shape:返回表示DataFrame維度的元組
DataFrame.size:返回DataFrame的元素數
DataFrame.values:將對象作為ndarray返回
DataFrame.head():返回前n行
DataFrame.tail():返回后n行
import pandas as pd
if __name__ == "__main__":
df = pd.DataFrame([["Bauer", 30, 90], ['Jack', 32, 98], ['Bob', 28, 78]], columns=['Name', 'Age', 'Score'])
print("DataFrame=================")
print(df)
print("T======================")
print(df.T)
print("axes===================")
print(df.axes)
print("dtypes==================")
print(df.dtypes)
print("empty==================")
print(df.empty)
print("ndim===================")
print(df.ndim)
print("shape==================")
print(df.shape)
print("size===================")
print(df.size)
print("values=================")
print(df.values)
print("head()=================")
print(df.head(2))
print("tail()=================")
print(df.tail(2))
# output:
# DataFrame=================
# Name Age Score
# 0 Bauer 30 90
# 1 Jack 32 98
# 2 Bob 28 78
# T======================
# 0 1 2
# Name Bauer Jack Bob
# Age 30 32 28
# Score 90 98 78
# axes===================
# [RangeIndex(start=0, stop=3, step=1), Index(['Name', 'Age', 'Score'], dtype='object')]
# dtypes==================
# Name object
# Age int64
# Score int64
# dtype: object
# empty==================
# False
# ndim===================
# 2
# shape==================
# (3, 3)
# size===================
# 9
# values=================
# [['Bauer' 30 90]
# ['Jack' 32 98]
# ['Bob' 28 78]]
# head()=================
# Name Age Score
# 0 Bauer 30 90
# 1 Jack 32 98
# tail()=================
# Name Age Score
# 1 Jack 32 98
# 2 Bob 28 78Panel 是三維的數據結構,是DataFrame的容器,Panel的3個軸如下:
items - axis 0,每個項目對應于內部包含的數據幀(DataFrame)。
major_axis - axis 1,是每個數據幀(DataFrame)的索引(行)。
minor_axis - axis 2,是每個數據幀(DataFrame)的列。
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
data:構建Panel的數據,采取各種形式,如:ndarray,series,map,lists,dict,constant和另一個數據幀(DataFrame)。
items:axis=0
major_axis:axis=1
minor_axis:axis=2
dtype:每列的數據類型
copy:復制數據,默認 - false
(1)創建空Panel
import pandas as pd
if __name__ == "__main__":
p = pd.Panel()
print(p)
# output:
# class 'pandas.core.panel.Panel'>
# Dimensions: 0 (items) x 0 (major_axis) x 0 (minor_axis)
# Items axis: None
# Major_axis axis: None
# Minor_axis axis: None(2)使用3D ndarray創建Panel
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = np.random.rand(2, 4, 5)
p = pd.Panel(data, items=["item1", "item2"], major_axis=[1, 2, 3, 4], minor_axis=['a', 'b', 'c', 'd', 'e'])
print(p)
print("item1")
print(p["item1"])
print(p.major_xs(2))
print(p.minor_xs('b'))
# output:
# <class 'pandas.core.panel.Panel'>
# Dimensions: 2 (items) x 4 (major_axis) x 5 (minor_axis)
# Items axis: item1 to item2
# Major_axis axis: 1 to 4
# Minor_axis axis: a to e
# item1
# a b c d e
# 1 0.185626 0.976123 0.566263 0.273208 0.675442
# 2 0.209664 0.205190 0.217200 0.158447 0.400683
# 3 0.499591 0.963321 0.759330 0.089930 0.362824
# 4 0.723158 0.585642 0.629246 0.886086 0.493039
# item1 item2
# a 0.209664 0.592154
# b 0.205190 0.661562
# c 0.217200 0.743716
# d 0.158447 0.055882
# e 0.400683 0.245760
# item1 item2
# 1 0.976123 0.630320
# 2 0.205190 0.661562
# 3 0.963321 0.741791
# 4 0.585642 0.729366(3)使用DataFrame字典創建Panel
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = {'Table1': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']),
'Table2': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']
)
}
p = pd.Panel(data)
print(p)
# output:
# <class 'pandas.core.panel.Panel'>
# Dimensions: 2 (items) x 4 (major_axis) x 3 (minor_axis)
# Items axis: Table1 to Table2
# Major_axis axis: rank1 to rank4
# Minor_axis axis: Name to Score使用Items訪問Panel可以獲取相應的DataFrame。
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = {'Table1': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']),
'Table2': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']
)
}
p = pd.Panel(data)
print(p['Table1'])
# output:
# Name Age Score
# rank1 -1.240644 -0.820041 1.656150
# rank2 1.830655 -0.258068 -0.728560
# rank3 1.268695 1.259693 -1.005151
# rank4 -0.139876 0.611589 2.343394使用panel.major_axis(key)函數訪問Panel數據,需要傳遞Major_axis的值作為key,返回DataFrame,DataFrame的index為Minor_axis,columns為Items。
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = {'Table1': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']),
'Table2': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']
)
}
p = pd.Panel(data)
print(p.major_xs('rank2'))
# output:
# Table1 Table2
# Name 1.664996 0.326820
# Age 0.952639 0.686095
# Score -0.473985 -0.343404使用panel.minor_axis(key)函數訪問Panel數據,需要傳遞Minor_axis的值作為key,返回DataFrame,DataFrame的index為Major_axis,columns為Items。
import pandas as pd
import numpy as np
if __name__ == "__main__":
data = {'Table1': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']),
'Table2': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']
)
}
p = pd.Panel(data)
print(p.minor_xs('Name'))
# output:
# Table1 Table2
# rank1 -1.314702 -0.198485
# rank2 0.055324 0.295646
# rank3 -0.352192 -0.523549
# rank4 -4.002903 -0.577389Panel對象的屬性和方法如下:
Panel.T:轉置行和列
Panel.axes:返回一個列,行軸標簽和列軸標簽作為唯一的成員。
Panel.dtypes:返回對象的數據類型
Panel.empty:如果NDFrame完全為空,返回True
Panel.ndim:返回軸/數組維度的大小
Panel.shape:返回表示DataFrame維度的元組
Panel.size:返回DataFrame的元素數
Panel.values:將對象作為ndarray返回
import pandas as pd
import numpy as np
if __name__ == "__main__":
array1 = np.random.randn(4, 3)
array2 = np.random.randn(4, 3)
data = {'Table1': pd.DataFrame(array1,
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']),
'Table2': pd.DataFrame(array2,
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']
)
}
p = pd.Panel(data)
print("panel=================")
print(p)
print("axes===================")
print(p.axes)
print("dtypes==================")
print(p.dtypes)
print("empty==================")
print(p.empty)
print("ndim===================")
print(p.ndim)
print("shape==================")
print(p.shape)
print("size===================")
print(p.size)
print("values=================")
print(p.values)
print(p["Table1"])
print(array1)
# output:
# panel=================
# <class 'pandas.core.panel.Panel'>
# Dimensions: 2 (items) x 4 (major_axis) x 3 (minor_axis)
# Items axis: Table1 to Table2
# Major_axis axis: rank1 to rank4
# Minor_axis axis: Name to Score
# axes===================
# [Index(['Table1', 'Table2'], dtype='object'), Index(['rank1', 'rank2', 'rank3', 'rank4'], dtype='object'), Index(['Name', 'Age', 'Score'], dtype='object')]
# dtypes==================
# Table1 float64
# Table2 float64
# dtype: object
# empty==================
# False
# ndim===================
# 3
# shape==================
# (2, 4, 3)
# size===================
# 24
# values=================
# [[[ 0.22914664 -0.88176603 0.48050365]
# [-0.15099586 0.23380446 0.20165317]
# [-0.13652604 1.08191771 0.60361811]
# [-0.81742392 -0.09018878 1.62892609]]
#
# [[-0.72965894 0.58207009 0.15309812]
# [ 0.06467707 1.13494668 -0.19074456]
# [-0.53869056 1.28244925 -0.01832724]
# [-0.26831567 0.65912009 0.38607594]]]
# Name Age Score
# rank1 0.229147 -0.881766 0.480504
# rank2 -0.150996 0.233804 0.201653
# rank3 -0.136526 1.081918 0.603618
# rank4 -0.817424 -0.090189 1.628926
# [[ 0.22914664 -0.88176603 0.48050365]
# [-0.15099586 0.23380446 0.20165317]
# [-0.13652604 1.08191771 0.60361811]
# [-0.81742392 -0.09018878 1.62892609]]免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





