溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
標準庫queue模塊,提供FIFO的queue、LIFO的隊列,優先隊列
Queue 類是線程安全的,適用于多線程間安全的交換數據,內部使用了Lock和Condition
為什么說容器的大小不準確,其原因是如果不加鎖,是不可能獲取到準確的大小的,因為你剛讀取了一個大小,還沒取走,有可能被就被其他線程修改了,queue類的size雖然加了鎖,但是依然不能保證立即get,put就能成功,因為讀取大小和get,put方法是分來的。
全局解釋器鎖,進程級別的鎖GIL
Cpython在解釋器進程中有一把鎖,叫做GIL全局解釋器鎖。GIL 保證Cpython進程中,當前時刻只有一個線程執行代碼,甚至在多核情況下,也是如此。
Cpython中
IO 密集型,由于線程阻塞,就會調度其他線程
CPU密集型,當前線程可能連續獲取GIL,導致其他線程幾乎無法使用CPU,若要喚醒其他線程,則需要準備數據,其代價是高昂的。
IO 密集型,多線程解決,CPU密集型,多進程解決,繞開GIL。
python中絕大多數內置數據結構的讀寫操作都是原子操作
由于GIL 的存在,python的內置數據類型在多線程編程的時候就變得安全了,但是實際上他們本身不是線程安全類型的
Guido堅持的簡單哲學,對于初學者門檻低,不需要高深的系統知識也能安全,簡單的使用python。
而移除GIL。會降低Cpython單線程的執行效率。
相關實例
import logging
import datetime
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc():
sum=0
for _ in range(1000000000):
sum+=1
calc()
calc()
calc()
calc()
calc()
delta=(datetime.datetime.now()-start).total_seconds()
logging.info(delta)
多線程模式下的計算結果
import logging
import datetime
import threading
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc():
sum=0
for _ in range(1000000000):
sum+=1
lst=[]
for _ in range(5):
t=threading.Thread(target=calc)
t.start()
lst.append(t)
for t in lst:
t.join()
delta=(datetime.datetime.now()-start).total_seconds()
print (delta)結果如下

從這兩個程序來看,Cpython中多線程根本沒有優勢,和一個線程執行的時間相當,因為存在GIL
由于python中的GIL ,多線程不是CPU密集型程序的最好選擇
多進程可以在完全獨立的進程中運行程序,可以充分利用多處理器
但是進程本身的隔離帶來數據不共享也是一個問題,且線程比進程輕量的多
多進程也是解決并發的一種手段
相同點:
進程是可以終止的,線程是不能通過命令終止的,線程的終止要么拋出異常,要么程序本身執行完成。
進程間同步提供了和線程同步一樣的類,使用方式也是一樣的,使用效果也是類似,不過,進程間同步的代價要高于線程,而且底層實現不同。
multiprocessing 還提供了共享內存,服務器進程來共享數據,還提供了queue隊列,匹配管道用于進程間通信
不同點
通信方式不同
1 多進程就是啟用多個解釋器進程,進程間通信必須序列化,反序列化
2 數據的安全性問題多進程最好是在main中執行
多線程已經將數據進行處理了,其不需要再次進行序列化了多進程傳遞必須序列化和反序列化。
遠程調用,RPC,跨網絡
multiprocessing中的process類
process 類遵循了Thread類的API,減少了學習難度
不同進程可以完全調度到不同的CPU上執行IO 密集型最好使用多線程
CPU 密集型最好使用多進程進程提供的相關屬性
| 名稱 | 含義 |
|---|---|
| pid | 進程ID |
| exitcode | 進程退出的狀態碼 |
| terminate() | 終止指定進程 |
import logging
import datetime
import multiprocessing
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc(i):
sum=0
for _ in range(1000000000):
sum+=1
lst=[]
for i in range(5):
p=multiprocessing.Process(target=calc,args=(i,),name="P-{}".format(i))
p.start()
lst.append(p)
for p in lst:
p.join()
delta=(datetime.datetime.now()-start).total_seconds()
print (delta)結果如下

多進程本身避開了進程和進程之間調度需要的時間,多核心都使用了,此處存在CPU的調度問題
多進程對CPU的提升是顯而易見的。
單線程,多線程都跑了很長時間,而多進程只是用了1分半,是真正的并行
import logging
import datetime
import multiprocessing
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc(i):
sum=0
for _ in range(1000000000):
sum+=1
print (i,sum)
if __name__=='__main__':
start=datetime.datetime.now()
p=multiprocessing.Pool(5) # 此處用于初始化進程池,其池中的資源是可以復用的
for i in range(5):
p.apply_async(calc,args=(i,))
p.close() # 下面要執行join,上面必須先close
p.join()
delta=(datetime.datetime.now()-start).total_seconds()
print (delta)結果如下

進程創建的多,使用進程池進行處理還是一種比較好的處理方式
1 CPU 密集型
Cpython 中使用了GIL,多線程的時候互相競爭,且多核優勢不能發揮,python使用多進程效率更高2 IO密集型
適合使用多線程,減少IO序列化開銷,且在IO等待時,切換到其他線程繼續執行,效率不錯,當然多進程也適用于IO密集型
請求/應答模型: WEB應用中常見的處理模型
master啟動多個worker工作進程,一般和CPU數目相同
worker工作進程中啟動多個線程,提高并發處理能力,worker處理用戶的請求,往往需要等待數據
這就是nginx的工作模式工作進程一般都和CPU核數相同,CPU的親原性,進程在CPU的遷移成本比較高。
concurrent.futures
3.2 版本引入的模塊
異步并行任務編程模塊,提供一個高級的異步可執行的便利接口提供了2個池執行器
ThreadPoolExecutor 異步調用的線程池的Executor
ProcessPoolExecutor 異步調用進程池的Executor
| 方法 | 含義 |
|---|---|
| ThreadPoolExecutor(max_workers=1) | 池中至多創建max_workers個線程的池來同時異步執行,返回Executor實例 |
| submit(fn,*args,**kwagrs) | 提交執行的函數及參數,返回Future實例 |
| shutdown(wait=True) | 清理池 |
Future 類
| 方法 | 含義 |
|---|---|
| result() | 可以查看調用的返回結果 |
| done() | 如果調用被成功的取消或者執行完成,則返回為True |
| cancelled() | 如果調用被成功取消,返回True |
| running() | 如果正在運行且不能被取消,則返回True |
| cancel() | 嘗試取消調用,如果已經執行且不能取消則返回False,否則返回True |
| result(timeout=None) | 取返回的結果,超時時為None,一直等待返回,超時設置到期,拋出concurrent.futures.TimeoutError異常 |
| execption(timeout=None) | 取返回的異常,超時為None,一直等待返回,超時設置到期,拋出concurrent.futures.TimeoutError異常 |
import logging
import threading
from concurrent import futures
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)-15s\t [%(processName)s:%(threadName)s,%(process)d:%(thread)8d] %(message)s")
def worker(n): # 定義未來執行的任務
logging.info("begin to work{}".format(n))
time.sleep(5)
logging.info("finished{}".format(n))
# 創建一個線程池,池容量為3
executor=futures.ThreadPoolExecutor(max_workers=3)
fs=[]
for i in range(3):
f=executor.submit(worker,i) # 傳入參數,返回Future對象
fs.append(f)
for i in range(3,6):
f=executor.submit(worker,i) # 傳入參數,返回Future對象
fs.append(f)
while True:
time.sleep(2)
logging.info(threading.enumerate()) #返回存活線程列表
flag=True
for f in fs:
logging.info(f.done()) # 如果被成功調用或取消完成,此處返回為True
flag=flag and f.done() # 若都調用成功,則返回為True,否則則返回為False
if flag:
executor.shutdown() # 如果全部調用成功,則需要清理池
logging.info(threading.enumerate())
break
結果如下

其線程池中的線程是持續使用的,一旦創建好的線程,其不會變化,唯一不好的就是線程名未發生變化,但其最多影響了打印效果
import logging
import threading
from concurrent import futures
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)-15s\t [%(processName)s:%(threadName)s,%(process)d:%(thread)8d] %(message)s")
def worker(n): # 定義未來執行的任務
logging.info("begin to work{}".format(n))
time.sleep(5)
logging.info("finished{}".format(n))
# 創建一個進程池,池容量為3
executor=futures.ProcessPoolExecutor(max_workers=3)
fs=[]
for i in range(3):
f=executor.submit(worker,i) # 傳入參數,返回Future對象
fs.append(f)
for i in range(3,6):
f=executor.submit(worker,i) # 傳入參數,返回Future對象
fs.append(f)
while True:
time.sleep(2)
flag=True
for f in fs:
logging.info(f.done()) # 如果被成功調用或取消完成,此處返回為True
flag=flag and f.done() # 若都調用成功,則返回為True,否則則返回為False
if flag:
executor.shutdown() # 如果全部調用成功,則需要清理池
break結果如下
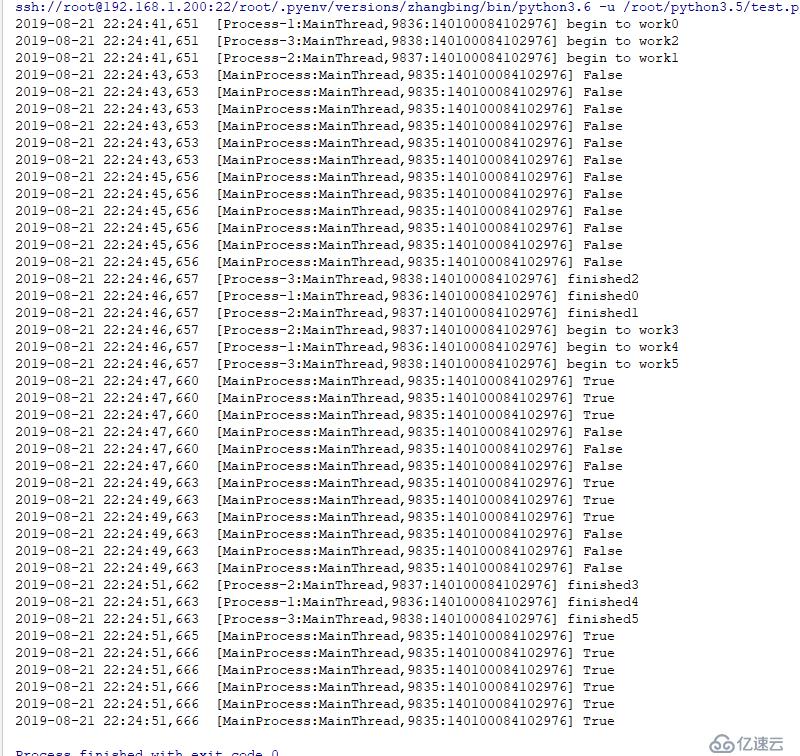
concurrent.futures.ProcessPoolExecutor 繼承自concurrent.futures.base.Executor,而父類有enter,_exit方法,其是支持上下文管理的,可以使用with語句
import logging
import threading
from concurrent import futures
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)-15s\t [%(processName)s:%(threadName)s,%(process)d:%(thread)8d] %(message)s")
def worker(n): # 定義未來執行的任務
logging.info("begin to work{}".format(n))
time.sleep(5)
logging.info("finished{}".format(n))
fs=[]
with futures.ProcessPoolExecutor(max_workers=3) as executor:
for i in range(6):
futures=executor.submit(worker,i)
fs.append(futures)
while True:
time.sleep(2)
flag=True
for f in fs:
logging.info(f.done()) # 如果被成功調用或取消完成,此處返回為True
flag=flag and f.done() # 若都調用成功,則返回為True,否則則返回為False
if flag:
executor.shutdown() # 如果全部調用成功,則需要清理池
break結果如下
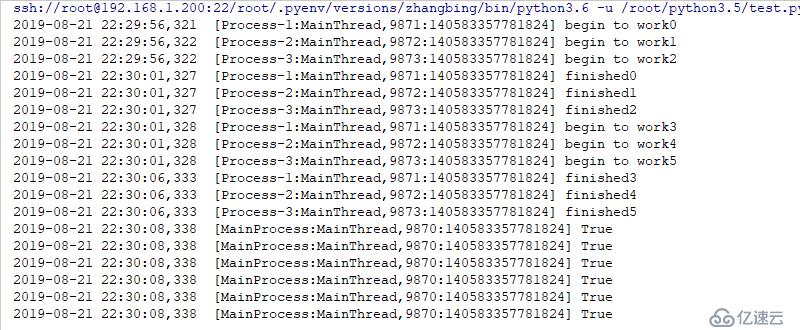
統一了線程池,進程池的調用,簡化了編程,是python簡單的思想哲學的提現
唯一缺點: 無法設置線程名稱
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





