溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們目前為止,已經可以完成一些軟件的基本功能了,現在我們自己來實現一個len,但是不能使用len
a = "sadsfsfg"
count = 0
for i in a:
count += 1
print(count)我們現在實現了一個求長度,我還想讓你們求一下列表和元組的長度 是不是就要將我們寫的內容再次拿過來
我們在求一個字典的長度,也需要將我們寫好的內容拿過來使用 好像程序中好多都是一樣的,所以可以將它封裝起來,多次重復使用
def 是python中關鍵字主要用來定義函數的
len這個是函數的名字
()這個括號是個神奇的東西,用來定義參數
: 冒號是表示咱們這個語句寫完了
函數體就是有4個空格的縮進
def len():
a = "sadassb"
count = 0
for i in a:
count += 1
print(count)我們來看一下函數的定義在內存空間發生了什么:
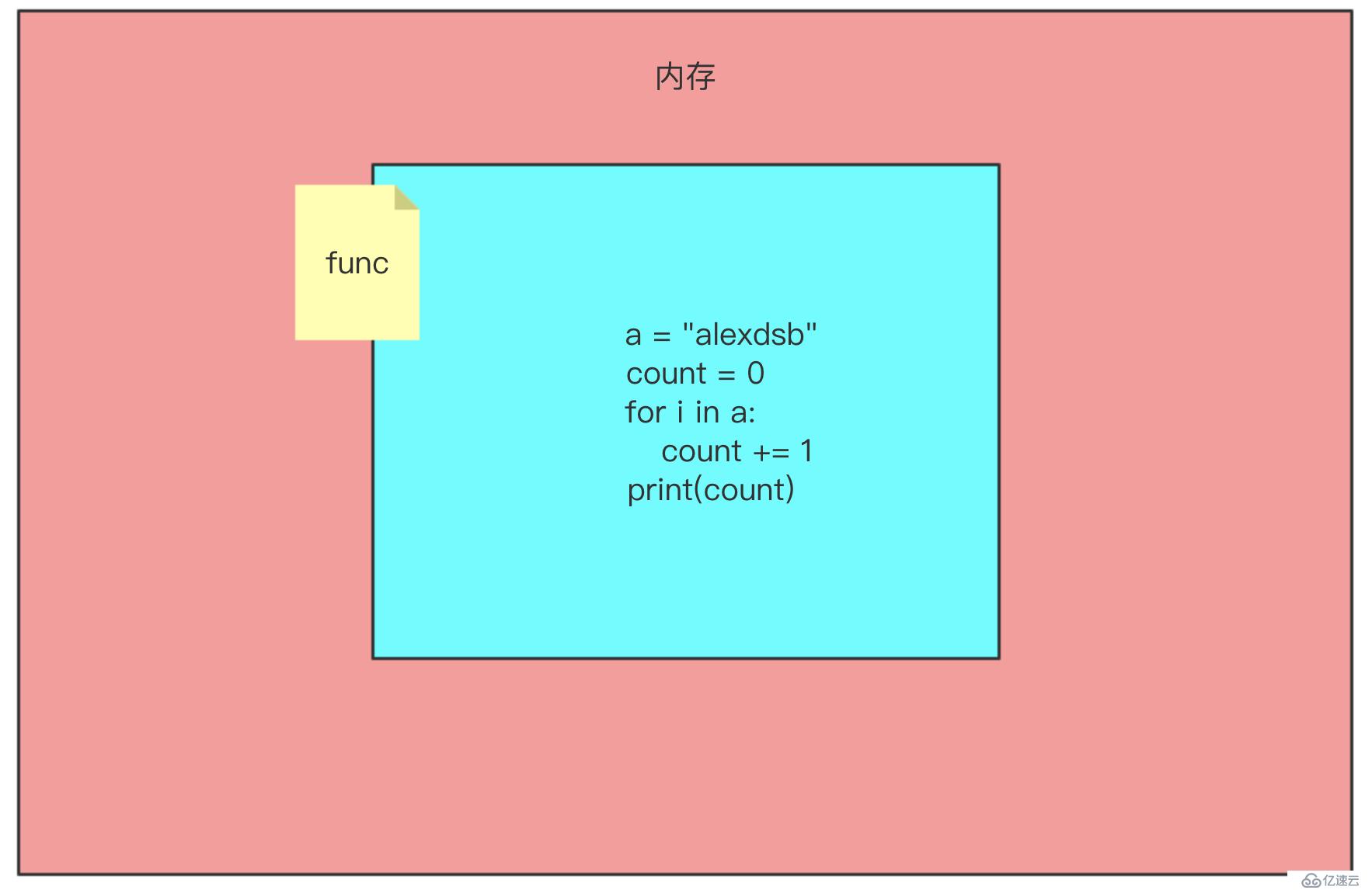
內存開辟了一個空間,但是里邊存放是代碼.
這樣我就將咱們寫的代碼封裝起來了,我們現在執行一下程序看看它會不會進行求長度,它并沒有執行,我們來看看怎么能夠執行上呢?
使用函數名加小括號就可以調用了 寫法:函數名() 這個時候函數的函數體會被執行
def len():
a = "alexdsb"
count = 0
for i in a:
count += 1
print(count)
len() # 函數的調用當我們調用執行的時候,才會執行func這個空間里的代碼,執行的時候在開辟空間,這次是在func里邊開辟的空間
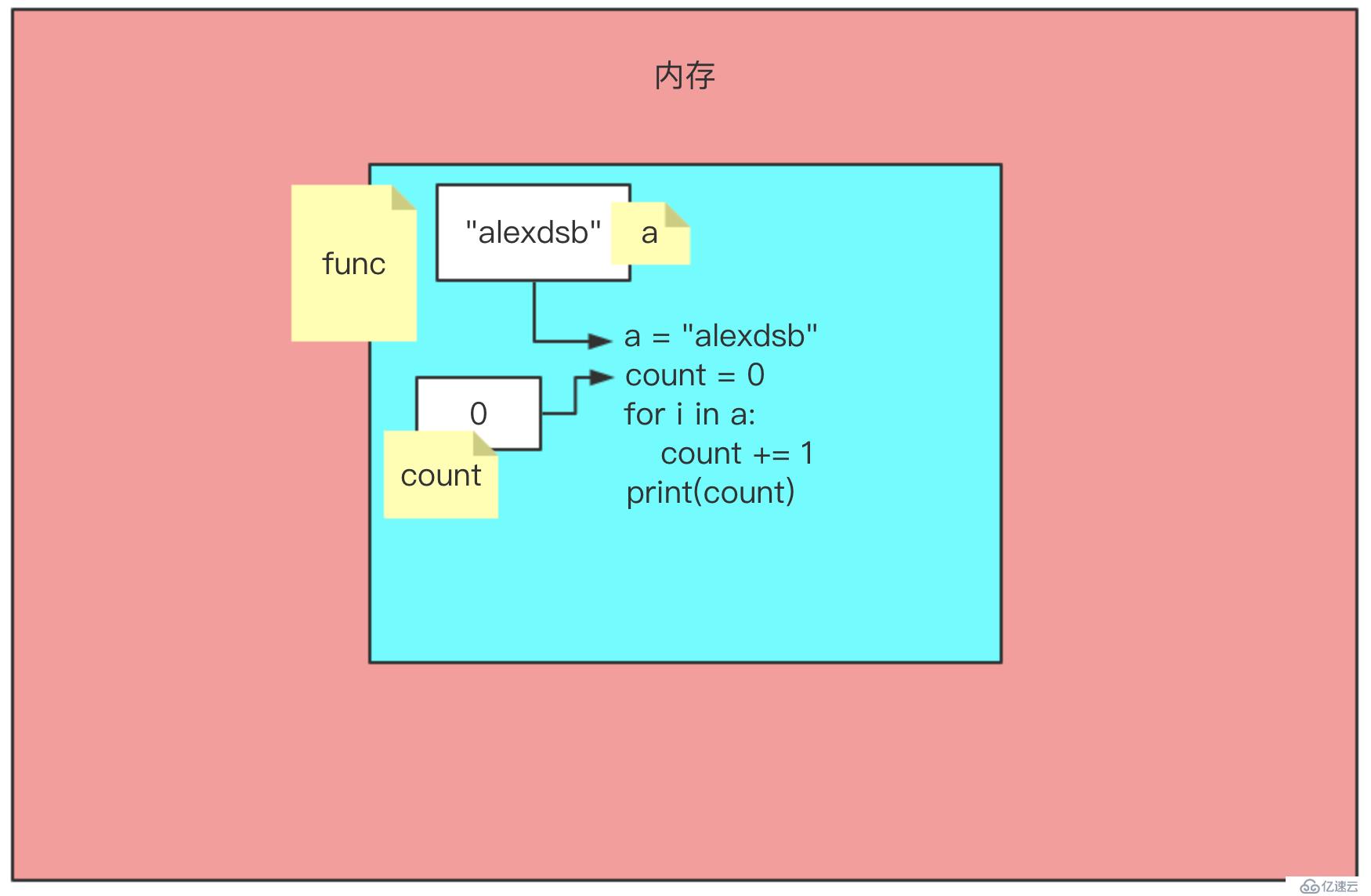
現在就實現了求一次長度,我想要多求幾次我就只需要
len()
len()
len()直接調用定義好的函數就可以了
當我們執行完函數后,函數里開辟的空間就銷毀了,我們如果想用函數里的值就需要從函數中傳遞出來
參數,也就是函數括號里的內容 函數在調用的時候指定一個具體的變量的值 就是參數.寫法如下:
def 函數名(參數):
函數體我們應該把代碼改一下,能夠實現我剛說的那種效果
def yue(app):
print("拿出?手機")
print("打開"+app)
print("搜一下宋冬野")
print("戴上耳機聽一聽")
yue("網易云")
yue("酷我")
yue("酷狗")
搞定了. 我們在調用yue的時候給app一個值. 然后再執行函數體.如果我們再定函數的時候寫了形參,在調用函數的時候沒有傳遞值,調用的時候右邊括號會發黃,所以我們必須要傳遞參數,參數要一一對應,不能多不能少.
? 1.形參
寫在函數聲明的位置的變量叫形參,形式上的一個完整.表示這個函數需要xxx
2.實參
在函數調用的時候給函數傳遞的值.加實參,實際執行的時候給函數傳遞的信息.表示給函數xxx
3.傳參
從調用函數的時候將值傳遞到定義函數的過程叫做傳參
def yue(app): # app 形參
print("拿出?手機")
print("打開"+app)
print("搜一下宋冬野")
print("戴上耳機聽一聽")
yue("酷我") # "酷我"在這里就是實參
len("酷狗") # "字符串"在這里就是實參
print("網易云") # "麻花藤"就是實參def yue(chat,addr,age): # chat 形參
print("拿出手機")
print("打開"+chat)
print("找個" + addr +"附近漂亮的" + str(age) + "歲妹子")
print("約不約")
yue("陌陌","北京",18) # 實參
結果:
拿出手機
打開陌陌
找個北京附近漂亮的18歲妹子
約不約上述代碼分析: 在訪問yue()的時候,我們按照位置的順序分別把"陌陌","北京",18賦值給了chat,addr,age,在傳參過程中.系統會按照位置把實參賦值到形參.
形參就是一個變量名,實參就是值 傳參就是在賦值
def func(addr,age):
addr = "北京"
age = 18 # 從實參到形參的過程中,函數體內部幫我做了變量的賦值
print(addr)
print(age)
func("北京",18)練習
編寫函數,給函數傳遞兩個參數a,b a,b相加 返回a參數和b參數相加的和
def f(a,b):
c = a+b
return c
num_sum = f(5,8)
print(num_sum)
結果: 13編寫函數,給函數傳遞兩個參數a,b 比較a,b的大小 返回a,b中最大的那個數
def f(a,b):
if a>b:
return a
else:
return b
num_sum = f(5,8)
print(num_sum)
結果:8比較大小的這個寫法有點麻煩,我們在這里學一個三元運算符
def f(a,b):
c = a if a > b else b #當a>b就把a賦值給c,否則就把b賦值給c
return c
msg = f(5,7)
print(msg)
結果:
7位置參數好不好呢? 如果是少量的參數還算OK, 沒有問題. 但是如果函數在定義的時候參數非常多怎么辦? 程序員必須記住, 我有哪些參數, 而且還有記住每個參數的位置, 否則函數就不能正常調用了. 那則么辦呢? python提出了一種叫做關鍵字參數. 我們不需要記住每個參數的位置. 只要記住每個參數的名字就可以了
def yue(chat, address, age):
print("拿出手機")
print("打開"+chat)
print("找個"+address+"附近漂亮的"+str(age)+"歲妹子")
print("約不約")
yue(chat="微信", age=18, address="北京") # 關鍵字參數.
結果:
拿出手機
打開微信
找個北京附近漂亮的18歲妹子
約不約搞定, 這樣就不需要記住繁瑣的參數位置了.
可以把上面兩種參數混合著使用. 也就是說在調用函數的時候即可以給出位置參數, 也可以指定關鍵字參數.
# 混合參數
yue("微信", age=18, address="上海") # 正確.第一個位置賦值給chat, 后面的參數開始指定關鍵字.
yue(age="18", "微信", address="廣州") # 錯誤, 最開始使用了關鍵字參數, 那么后面的 微信的位置就串了, 容易出現混亂注意: 在使用混合參數的時候, 關鍵字參數必須在位置參數后面
綜上: 在實參的?角度來看. 分為三種:
位置參數:
位置參數,按照位置來賦值,到目前為止,我們編寫的函數都是這種
def yue(chat, address, age):
print("拿出手機")
print("打開"+chat)
print("找個"+address+"附近漂亮的"+str(age)+"歲妹子")
print("約不約")默認值參數:
在函數聲明的時候, 就可以給出函數參數的默認值. 在調用的時候可以 給出具體的值, 也可以不給值, 使?用默認值. 比如, 我們錄入咱們班學生的基本信息. 通過調查發現. 我們班大部分學生都是男生. 這個時 候就可以給出?一個sex='男'的默認值.
def stu_info(name, age, sex='男'):
print("錄入學生信息")
print(name, age, sex)
print("錄入完畢")
stu_info("張強", 18)注意:必須先聲明在位置參數,才能聲明關鍵字參數
形參: 函數的定義中括號里是形參
實參: 函數的調用括號里是實參
位置傳參時 形參和實參必須一一對應
傳參: 將實參傳遞給形參的過程就是傳參
函數的參數:
# 形參: 函數定義的時候叫做形參
# 位置參數
# 默認參數
# 混合參數
# 實參: 函數調用的時候叫做實參
# 位置參數
# 關鍵字參數
# 混合參數
# 傳參: 將實參傳遞給形參的過程叫做傳參動態參數分為兩種:動態接受位置參數 *args,動態接收關鍵字參數**kwargs.
動態接收位置參數:*args
我們按照上面的例子繼續寫,如果我請你吃的內容很多,但是我又不想用多個參數接收,那么我就可以使用動態參數*args
def eat(*args):
print('我請你吃:',args)
eat('蒸羊羔兒','蒸熊掌','蒸鹿尾兒','燒花鴨','燒雛雞','燒子鵝')
# 運行結果:
#我請你吃: ('蒸羊羔兒', '蒸熊掌', '蒸鹿尾兒', '燒花鴨', '燒雛雞', '燒子鵝')解釋一下上面參數的意義:首先來說args,args就是一個普通的形參,但是如果你在args前面加一個,那么就擁有了特殊的意義:在python中除了表示乘號,他是有魔法的。+args,這樣設置形參,那么這個形參會將實參所有的位置參數接收,放置在一個元組中,并將這個元組賦值給args這個形參,這里起到魔法效果的是 而不是args,a也可以達到剛才效果,但是我們PEP8規范中規定就使用args,約定俗成的。
練習:傳入函數中數量不定的int型數據,函數計算所有數的和并返回。
def my_max(*args):
n = 0
for i in args:
n += i
return n動態接收關鍵字參數: kwargs**
實參角度有位置參數和關鍵字參數兩種,python中既然有*args可以接受所有的位置參數那么肯定也有一種參數接受所有的關鍵字參數,那么這個就是kwargs,同理這個是具有魔法用法的,kwargs約定俗成使用作為形參。舉例說明:**kwargs,是接受所有的關鍵字參數然后將其轉換成一個字典賦值給kwargs這個形參。
def func(**kwargs):
print(kwargs) # {'name': '太白金星', 'sex': '男'}
func(name='太白金星',sex='男')我們看一下動態參數的完成寫法:
def func(*args,**kwargs):
print(args) # ('蒸羊羔兒', '蒸熊掌', '蒸鹿尾兒')
print(kwargs) # {'name': '太白金星', 'sex': '男'}
func('蒸羊羔兒', '蒸熊掌', '蒸鹿尾兒',name='太白金星',sex='男')如果一個參數設置了動態參數,那么他可以接受所有的位置參數,以及關鍵字參數,這樣就會大大提升函數拓展性,針對于實參參數較多的情況下,解決了一一對應的麻煩。
剛才我們研究了動態參數,其實有的同學對于魔法用法 * 比較感興趣,那么那的魔性用法不止這么一點用法,我們繼續研究:
函數中分為打散和聚合。
函數外可以處理剩余的元素。
函數的打散和聚合
剛才我們研究了,在函數定義時,如果我只定義了一個形參稱為args,那么這一個形參只能接受幾個實參? 是不是只能當做一個位置參數對待?它只能接受一個參數:
def eat(args):
print('我請你吃:',args) # 我請你吃: 蒸羊羔兒
eat('蒸羊羔兒')但是如果我給其前面加一個* 那么args可以接受多個實參,并且返回一個元組,對吧? (*kwargs也是同理將多個關鍵字參數轉化成一個字典返回)所以在函數的定義時: 起到的是聚合的作用。
此時不著急給大家講這個打散,而是出一個小題:你如何將三個數據(這三個數據都是可迭代對象類型)s1 = 'alex',l1 = [1, 2, 3, 4], tu1 = ('武sir', '太白', '女神',)的每一元素傳給動態參數*args?(就是args最終得到的是 ('a','l','e','x', 1, 2, 3, 4,'武sir', '太白', '女神',)?有人說這還不簡單么?我直接傳給他們不就行了?
s1 = 'alex'
l1 = [1, 2, 3, 4]
tu1 = ('武sir', '太白', '女神',)
def func(*args):
print(args) # ('alex', [1, 2, 3, 4], ('武sir', '太白', '女神'))
func(s1,l1,tu1)這樣肯定是不行,他會將這個三個數據類型當成三個位置參數傳給args,沒有實現我的要求。
好像你除了直接寫,沒有別的什么辦法,那么這里就得用到我們的魔法用法 :*
s1 = 'alex'
l1 = [1, 2, 3, 4]
tu1 = ('武sir', '太白', '女神',)
def func(*args):
print(args) # ('a', 'l', 'e', 'x', 1, 2, 3, 4, '武sir', '太白', '女神')
func(*s1,*l1,*tu1)你看此時是函數的執行時,我將你位置參數的實參(可迭代類型)前面加上,相當于將這些實參給拆解成一個一個的組成元素當成位置參數,然后傳給args,這時候這個好像取到的是打散的作用。所以在函數的執行時:,**起到的是打散的作用。
dic1 = {'name': '太白', 'age': 18}
dic2 = {'hobby': '喝茶', 'sex': '男'}
def func(**kwargs):
print(kwargs) # {'name': '太白', 'age': 18, 'hobby': '喝茶', 'sex': '男'}
func(**dic1,**dic2)*處理剩下的元素
*除了在函數中可以這樣打散,聚合外,函數外還可以靈活的運用:
# 之前講過的分別賦值
a,b = (1,2)
print(a, b) # 1 2
# 其實還可以這么用:
a,*b = (1, 2, 3, 4,)
print(a, b) # 1 [2, 3, 4]
*rest,a,b = range(5)
print(rest, a, b) # [0, 1, 2] 3 4
print([1, 2, *[3, 4, 5]]) # [1, 2, 3, 4, 5]到目前為止,從形參的角度我們講了位置參數,默認值參數,動態參數*args,**kwargs,還差一種參數,需要講完形參順序之后,引出。先不著急,我們先看看已經講的這些形參他的排列順序是如何的呢?
首先,位置參數,與默認參數他兩個的順序我們昨天已經確定了,位置參數必須在前面,即 :位置參數,默認參數。
那么動態參數*args,**kwargs放在哪里呢?
動態參數*args,肯定不能放在位置參數前面,這樣我的位置參數的參數就接收不到具體的實參了:
# 這樣位置參數a,b始終接收不到實參了,因為args全部接受完了
def func(*args,a,b,sex='男'):
print(args)
print(a,b)
func(1, 2, 3, 4, 5)那么動態參數必須在位置參數后面,他可以在默認參數后面么?
# 這樣也不行,我的實參的第三個參數始終都會將sex覆蓋掉,這樣失去了默認參數的意義。
def func(a,b,sex='男',*args,):
print(args) # (4, 5)
print(sex) # 3
print(a,b) # 1 2
func(1, 2, 3, 4, 5)所以*args一定要在位置參數與默認值參數中間:位置參數,*args,默認參數。
那么我的kwargs放在哪里?kwargs可以放在默認參數前面么?
# 直接報錯:因為**kwargs是接受所有的關鍵字參數,如果你想改變默認參數sex,你永遠也改變不了,因為
# 它會先被**kwargs接受。
def func(a,b,*args,**kwargs,sex='男',):
print(args) # (4, 5)
print(sex) # 3
print(a,b) # 1 2
print(kwargs)
func(1, 2, 3, 4, 5)所以截止到此:所有形參的順序為:位置參數,*args,默認參數,**kwargs。
僅限關鍵字參數是python3x更新的新特性,他的位置要放在*args后面,kwargs前面(如果有kwargs),也就是默認參數的位置,它與默認參數的前后順序無所謂,它只接受關鍵字傳的參數:
# 這樣傳參是錯誤的,因為僅限關鍵字參數c只接受關鍵字參數
def func(a,b,*args,c):
print(a,b) # 1 2
print(args) # (4, 5)
# func(1, 2, 3, 4, 5)
# 這樣就正確了:
def func(a,b,*args,c):
print(a,b) # 1 2
print(args) # (3, 4)
print(5)
func(1, 2, 3, 4, c=5)這個僅限關鍵字參數從名字定義就可以看出他只能通過關鍵字參數傳參,其實可以把它當成不設置默認值的默認參數而且必須要傳參數,不傳就報錯。
所以形參角度的所有形參的最終順序為:*位置參數,args,默認參數,僅限關鍵字參數,kwargs。
課間考一道題:
def foo(a,b,*args,c,sex=None,**kwargs):
print(a,b)
print(c)
print(sex)
print(args)
print(kwargs)
# foo(1,2,3,4,c=6)
# foo(1,2,sex='男',name='alex',hobby='old_woman')
# foo(1,2,3,4,name='alex',sex='男')
# foo(1,2,c=18)
# foo(2, 3, [1, 2, 3],c=13,hobby='喝茶')
# foo(*[1, 2, 3, 4],**{'name':'太白','c':12,'sex':'女'})接下來我們講的內容,理論性的偏多,就是從空間角度,內存級別去研究python。首先我們看看什么是全局名稱空間:
在python解釋器開始執行之后, 就會在內存中開辟一個空間, 每當遇到一個變量的時候, 就把變量名和值之間的關系記錄下來, 但是當遇到函數定義的時候, 解釋器只是把函數名讀入內存, 表示這個函數存在了, 至于函數內部的變量和邏輯, 解釋器是不關心的. 也就是說一開始的時候函數只是加載進來, 僅此而已, 只有當函數被調用和訪問的時候, 解釋器才會根據函數內部聲明的變量來進行開辟變量的內部空間. 隨著函數執行完畢, 這些函數內部變量占用的空間也會隨著函數執行完畢而被清空.
我們首先回憶一下Python代碼運行的時候遇到函數是怎么做的,從Python解釋器開始執行之后,就在內存中開辟里一個空間,每當遇到一個變量的時候,就把變量名和值之間對應的關系記錄下來,但是當遇到函數定義的時候,解釋器只是象征性的將函數名讀如內存,表示知道這個函數存在了,至于函數內部的變量和邏輯,解釋器根本不關心。
等執行到函數調用的時候,Python解釋器會再開辟一塊內存來儲存這個函數里面的內容,這個時候,才關注函數里面有哪些變量,而函數中的變量會儲存在新開辟出來的內存中,函數中的變量只能在函數內部使用,并且會隨著函數執行完畢,這塊內存中的所有內容也會被清空。
我們給這個‘存放名字與值的關系’的空間起了一個名字-------命名空間。
代碼在運行伊始,創建的存儲“變量名與值的關系”的空間叫做全局命名空間;
在函數的運行中開辟的臨時的空間叫做局部命名空間也叫做臨時名稱空間。
現在我們知道了,py文件中,存放變量與值的關系的一個空間叫做全局名稱空間,而當執行一個函數時,內存中會臨時開辟一個空間,臨時存放函數中的變量與值的關系,這個叫做臨時名稱空間,或者局部名稱空間。
其實python還有一個空間叫做內置名稱空間:內置名稱空間存放的就是一些內置函數等拿來即用的特殊的變量:input,print,list等等,所以,我們通過畫圖捋一下:
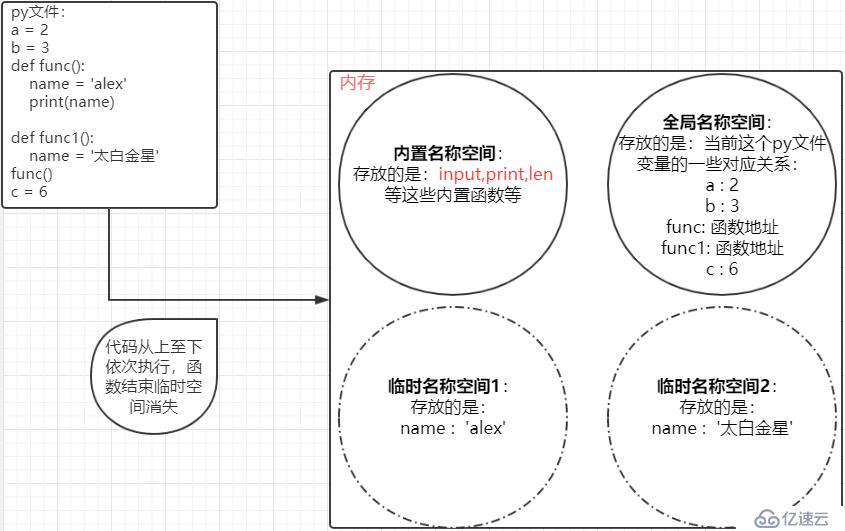
那么這就是python中經常提到的三個空間。
總結:
\1. 全局命名空間--> 我們直接在py文件中, 函數外聲明的變量都屬于全局命名空間
\2. 局部命名空間--> 在函數中聲明的變量會放在局部命名空間
\3. 內置命名空間--> 存放python解釋器為我們提供的名字, list, tuple, str, int這些都是內置命名空間
所謂的加載順序,就是這三個空間加載到內存的先后順序,也就是這個三個空間在內存中創建的先后順序,你想想他們能是同時創建么?肯定不是的,那么誰先誰后呢?我們捋順一下:在啟動python解釋器之后,即使沒有創建任何的變量或者函數,還是會有一些函數直接可以用的比如abs(-1),max(1,3)等等,在啟動Python解釋器的時候,就已經導入到內存當中供我們使用,所以肯定是先加載內置名稱空間,然后就開始從文件的最上面向下一行一行執行,此時如果遇到了初始化變量,就會創建全局名稱空間,將這些對應關系存放進去,然后遇到了函數執行時,在內存中臨時開辟一個空間,加載函數中的一些變量等等。所以這三個空間的加載順序為:內置命名空間(程序運行伊始加載)->全局命名空間(程序運行中:從上到下加載)->局部命名空間(程序運行中:調用時才加載。
取值順序就是引用一個變量,先從哪一個空間開始引用。這個有一個關鍵點:從哪個空間開始引用這個變量。我們分別舉例說明:
# 如果你在全局名稱空間引用一個變量,先從全局名稱空間引用,全局名# 稱空間如果沒有,才會向內置名稱空間引用。
input = 666
print(input) # 666
# 如果你在局部名稱空間引用一個變量,先從局部名稱空間引用,
# 局部名稱空間如果沒有,才會向全局名稱空間引用,全局名稱空間在沒有,就會向內置名稱空間引用。
input = 666
print(input) # 666
input = 666
def func():
input = 111
print(input) # 111
func()所以空間的取值順序與加載順序是相反的,取值順序滿足的就近原則,從小范圍到大范圍一層一層的逐步引用。
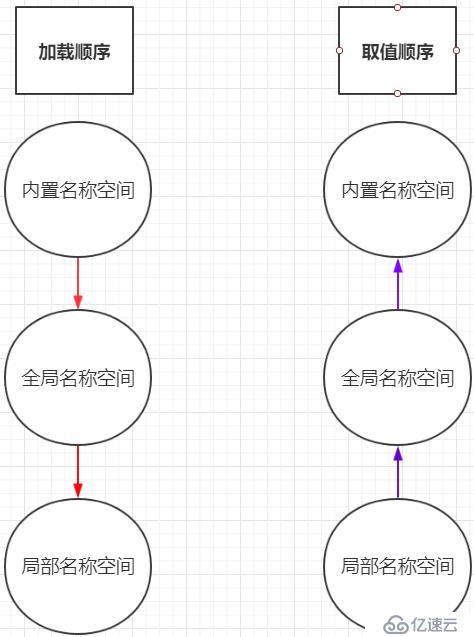
作用域就是作用范圍, 按照生效范圍來看分為全局作用域和局部作用域
全局作用域: 包含內置命名空間和全局命名空間. 在整個文件的任何位置都可以使用(遵循 從上到下逐?執行).
局部作用域: 在函數內部可以使用.
作?域命名空間:
1. 全局作用域: 全局命名空間 + 內置命名空間
2. 局部作?域: 局部命名空間
這兩個內置函數放在這里講是在合適不過的,他們就直接可以反映作用域的內容,有助于我們理解作用域的范圍。
globals(): 以字典的形式返回全局作用域所有的變量對應關系。
locals(): 以字典的形式返回當前作用域的變量的對應關系。
這里一個是全局作用域,一個是當前作用域,一定要分清楚,接下來,我們用代碼驗證:
# 在全局作用域下打印,則他們獲取的都是全局作用域的所有的內容。
a = 2
b = 3
print(globals())
print(locals())
'''
{'__name__': '__main__', '__doc__': None, '__package__': None,
'__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001806E50C0B8>,
'__spec__': None, '__annotations__': {},
'__builtins__': <module 'builtins' (built-in)>,
'__file__': 'D:/lnh.python/py project/teaching_show/day09~day15/function.py',
'__cached__': None, 'a': 2, 'b': 3}
'''
# 在局部作用域中打印。
a = 2
b = 3
def foo():
c = 3
print(globals()) # 和上面一樣,還是全局作用域的內容
print(locals()) # {'c': 3}
foo()免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





