溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
當年學爬蟲的第一個想法就是想把雙色球的數據爬下來,然后看能不能用什么牛叉的算法,或者數據分析把后面的雙色球概率算出來;
知道現在才抽空寫了這幾行代碼爬取了雙色球的數據,我也真是夠懶的;
也算是閑來無事,練手的爬蟲吧;
好了,多余的就不說了,直接上代碼吧,代碼注釋已經很清楚了;
import sys
import requests
from lxml import etree
def get_url(url): #請求url的方法,返回html
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
response = requests.get(url,headers=headers) #獲取請求的返回數據
response.encoding = 'utf-8' #定義編碼,不然中文輸出會亂碼;
if response.status_code == 200: #如果請求成功,則返回;
return response.text
return None
for q in range(1,125): #for循環,一共124頁;
url = 'http://kaijiang.zhcw.com/zhcw/html/ssq/list_%s.html' % (q) #定義請求的鏈接
html = get_url(url) #請求url獲取返回代碼
xpath_html = etree.HTML(html) #xpath初始化html代碼
dates = xpath_html.xpath('//table[@class="wqhgt"]//tr//td[1]//text()') #獲取開獎日期
result = xpath_html.xpath('//table[@class="wqhgt"]//tr//em//text()') #獲取上色球號
issues = xpath_html.xpath('//table[@class="wqhgt"]//tr//td[2]//text()') #獲取期號
# print(result) #輸出所有雙色球的列
# print(len(result)//7) #輸出有幾組雙色球
# print(dates)
# print(issues)
sta = 0
end = 7
for n in range(len(result)//7): #雙色球7個號一組,
print("開獎日期:" + str(dates[n]) + " --- " + "期號:" + str(issues[n]) + " --- " + str(result[sta:end]))
sta = sta + 7
end = end + 7python版本用的3.7,開發工具用的pycharm;
爬取的結果可以根據自己需求進行調整,后面怎么用這些數據就不說了哈;具體根據自己需求進行分析吧;
運行的結果: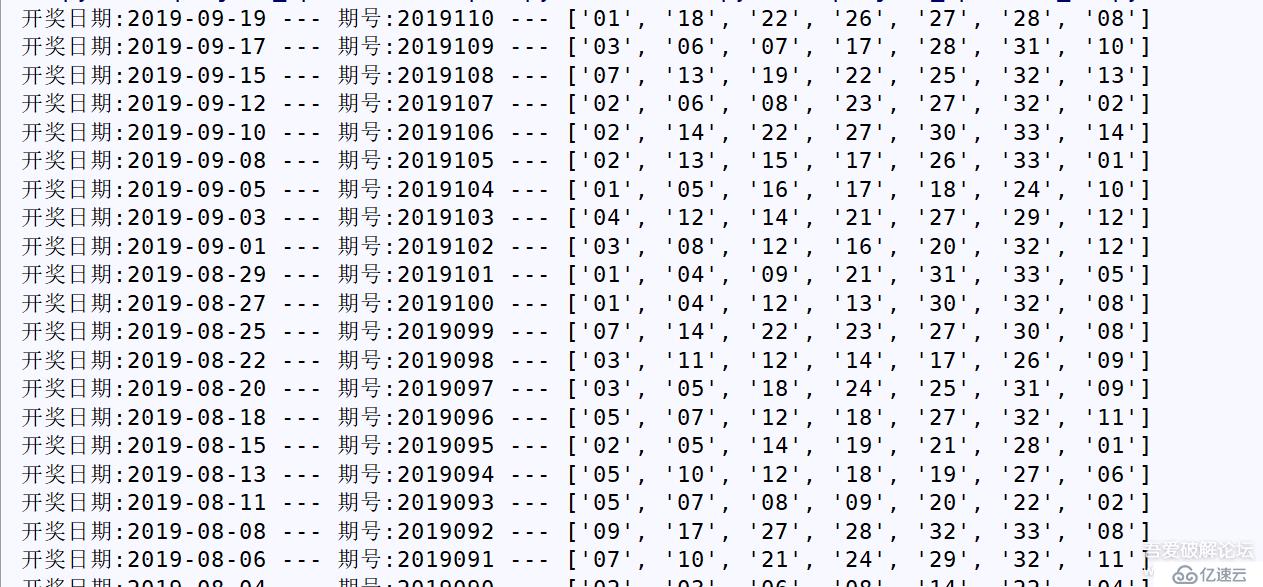
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





