溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
>>> s1 = {}
>>> type(s1)
<class 'dict'>
>>> s2 = {1, 2, 3}
>>> type(s2)
<class 'set'>
>>> s3 = {1, 3.14, True, 'hello', [1, 2, 3], (1, 2, 3)}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> s3 = {1, 3.14, True, 'hello',(1, 2, 3)}
>>> type(s3)
<class 'set'>
>>> s4 = set([])
>>> type(s4)
<class 'set'>
>>> s5 = set('abcde')
>>> s5
{'c', 'e', 'b', 'a', 'd'}
>>> type(s5)
<class 'set'>集合(set)是一個無序的不重復元素序列。1,2,3,4,1,2,3 = 1,2,3,4
集合的創建:
1). 使用大括號 { } 或者 set() 函數創建集合;
2). 注意:
l 創建一個空集合必須用 set() 而不是 { }
l { } 是用來創建一個空字典。
#1). 集合的增加
#add: 添加單個元素到集合中
#update: 添加多個元素到集合中
set1 = { 1, 2, 3 }
set1.add(4)
print(set1)
set1.add(3)
print(set1)
set1.update({2, 3, 4, 5, 6})
print(set1)
#2). 集合的刪除
#remove: 如果元素存在, 直接刪除, 如果不存在, 拋出異常KeyError。
#discard:如果元素存在, 直接刪除, 如果不存在, do nothing。
#pop:隨機刪除指定元素, 并返回刪除的值。
#clear:清空集合。
set2 = {1, 2, 3, 4}
set2.remove(2)
print(set2)
#集合是一個無序的數據類型。最后增加的元素不一定存儲在集合最后。
#無序意味著索引值會隨時變化, 因此不可以索引和切片。
set2 = {9991, 29, 33, 4}
print(set2)
set2.add(11)
print(set2)
set2.pop()
print(set2)
set2 = {1, 2, 3, 4}
set2.discard(5)
print(set2)
#set2 = {1, 2, 3, 4}
#set2.remove(5)
#print(set2)
set2.clear()
print(set2)
#3). 集合的查看
set1 = {1, 2, 3}
set2 = {1, 2, 4}
print("交集是: ", set1 & set2) # {1, 2}
print("并集是: ", set1 | set2) # {1, 2, 3, 4}
print("差集是: ", set1 - set2) # {3} set1 - set2 = set1 - (set1 & set2)
print("差集是: ", set2 - set1) # {4} set2 - set1 = set2 - (set1 & set2)
print("對等差分是: ", set2 ^ set1) # {3, 4} (set1 | set2) - (set1 & set1)
"""
set1 = {1, 2, 3}
set2 = {1, 2, 4}
print("交集是: ", set1.intersection(set2)) # {1, 2}
#print("交集是: ", set1.intersection_update(set2)) # {1, 2} set1 = set1 & set2
print("并集是: ", set1.union(set2)) # {1, 2, 3, 4}
print("差集是: ", set1.difference(set2)) # {3} set1 - set2 = set1 - (set1 & set2)
print("差集是: ", set2.difference(set1)) # {4} set2 - set1 = set2 - (set1 & set2)
print("對等差分是: ", set1.symmetric_difference(set2)) # {3, 4} (set1 | set2) - (set1 & set1)
set3 = {1, 2}
set4 = {1, 2, 4}
print(set3.isdisjoint(set4)) # False
print(set3.issubset(set4)) # True
print(set4.issuperset(set3)) # True
總結: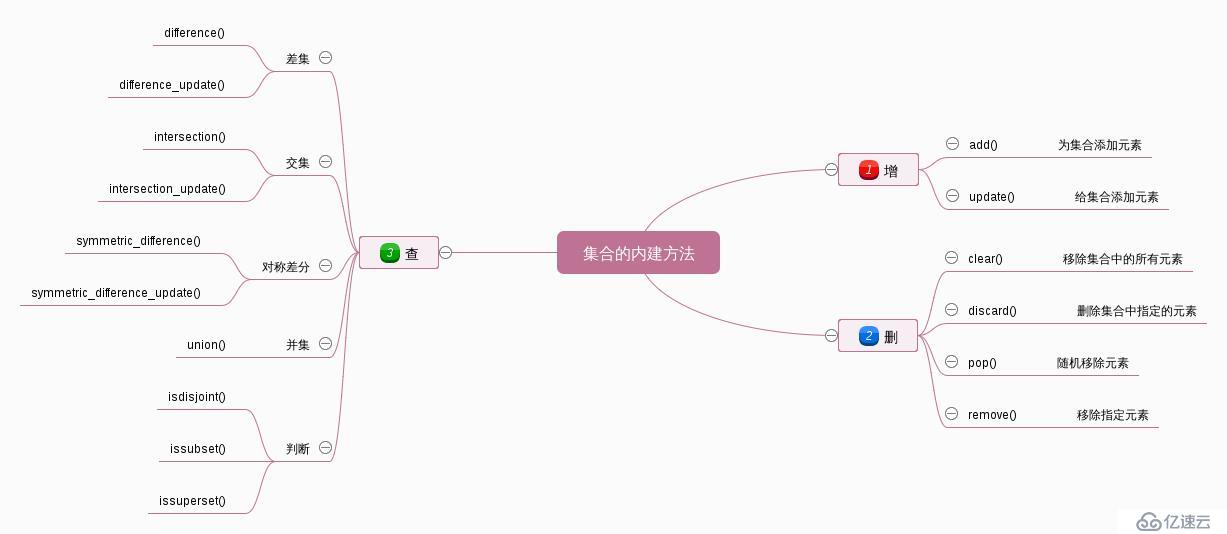
URL地址去重:
urls = [
'http://www.baidu.com',
'http://www.qq.com',
'http://www.qq.com',
'http://www.163.com',
'http://www.csdn.com',
'http://www.csdn.com',
]
#用來存儲去重的url地址
analyze_urls = []
#依次遍歷所有的url
for url in urls:
#如果url不是analyze_urls列表成員, 則追加到列表最后。
#如果url是analyze_urls列表成員,不做任何操作。
if url not in analyze_urls:
analyze_urls.append(url)
print("去重之后的url地址: ", analyze_urls)
"""
urls = [
'http://www.baidu.com',
'http://www.qq.com',
'http://www.qq.com',
'http://www.163.com',
'http://www.csdn.com',
'http://www.csdn.com',
]
print("去重之后的url地址: ",set(urls))華為筆試編程題: 明明的隨機數:
明明想在學校中請一些同學一起做一項問卷調查,為了實驗的客觀性,他先用計算機生成了N個1到1000之間的
隨機整數(N≤1000),對于其中重復的數字,只保留一個,把其余相同的數去掉,不同的數對應著不同的學
生的學號。然后再把這些數從大到小排序,按照排好的順序去找同學做調查。請你協助明明完成“去重”與
“排序”的工作(同一個測試用例里可能會有多組數據,希望大家能正確處理)。
1). 生成了N個1到1000之間的隨機整數(N≤1000)
2). 去重: 其中重復的數字,只保留一個,把其余相同的數去掉
3). 從大到小排序
"""
import random
#2). 去重: 其中重復的數字,只保留一個,把其余相同的數去掉.生成一個空集合
nums = set()
N = int(input('N: '))
#1). 生成了N個1到1000之間的隨機整數(N≤1000)
for count in range(N):
num = random.randint(1, 1000)
nums.add(num)
#3). 從大到小排序, li.sort()智能對列表進行排序; sorted()方法可以對任意數據類型排序。
print(sorted(nums, reverse=True))frozenset應用:
#1). 當集合元素不需要改變時,使用 frozenset 代替 set 更安全。
#2). 當某些 API 需要不可變對象時,必須用 frozenset 代替set。
set1 = frozenset({1, 2, 3, 4})
print(set1, type(set1))
set2 = {1, 2, set1}
print(set2)#1). 字典可以快速通過key值查詢到value值。O(1)
#2). key值是不能重復的, value值無所謂
#3). 字典的key值必須是不可變的數據類型, value值可以是任意數據類型。
info = {
'name' : 'root', # key:value ===> 鍵:值 key-value對/鍵值對
'password': 'westos',
'member': ['kiosk', 'student']
}
print(type(info))
print(info)#pprint==pretty print,更加美觀/友好的打印模塊
import pprint
#需求: 創建100個銀行卡號, 6103452xxx: 6103452001, 6103452002,.........6103452100, 這些銀行卡號的初始密碼為666666.
#1). 生成100個卡號, 存儲在列表中
cards = []
for count in range(100):
num = "%.3d" %(count+1)
card = '6103452' + str(num)
cards.append(card)
#2). 快速生成卡號和密碼的對應關系, 存儲在字典中;
cards_info = {}.fromkeys(cards, 'westos')
pprint.pprint(cards_info)"""
#zip間接創建
info = zip(['name', 'passwd'], ['root', 'westos'])
#print(list(info))
print(dict(info))#通過dict傳值的方式創建字典
info = dict(name='root', passwd='westos')
print(info)students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
#通過字典的key獲取對應的value值;
print(students['user1'])
#print(students['user4']) # KeyError: 'user4', 因為key值在字典中不存在
#特別重要: get方法: 如果key存在獲取對應的value值, 反之, 返回默認值(如果不指定,默認返回的是None)
print(students.get('user1')) # [100, 100, 100]
print(students.get('user4', 'no user')) # 'no user'
#查看所有的key值/value值/key-value值
print(students.keys())
print(students.values())
print(students.items()) # key-value值 [(key1, value1),(key2, value2)]##for循環字符串
#for item in 'abc':
#print(item)
##for循環元組
#for item in (1, 2, 3):
#print(item)
##for循環集合
#for item in {1, 2, 3}:
#print(item)
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
#字典遍歷時默認遍歷的時字典的key值
for key in students:
print(key, students[key])
#遍歷字典key-value建議的方法
for key,value in students.items(): # [('user1', [100, 100, 100]), ('user2', [98, 100, 100]), ('user3', [100, 89, 100])]
# key,value = ('user1', [100, 100, 100])
#key,value = ('user2', [98, 100, 100])
#key,value = ('user3', [100, 89, 100])
print(key, value)import pprint
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
#1). 根據key增加 /修改key-value
#如果key存在, 修改key-value
#如果key不存在, 增加key-value
students['user4'] = [90, 99, 89]
print(students)
#2). setdefault方法
#如果key存在, 不做任何操作
#如果key不存在, 增加key-value
students.setdefault('user1', [100, 89, 88])
print(students)
#3). update方法: 批量添加key-value
#如果key存在, 修改key-value
#如果key不存在, 增加key-value
new_student = {
'westos':[100, 100, 100],
'root':[100, 100, 100],
'user1':[0, 0, 0]
}
students.update(new_student)
pprint.pprint(students)students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
##1). del dict[key]
##如果key存在, 刪除對應的value值
##如果key不存在, 拋出異常KeyError
#del students['user1']
#print(students)
##2). pop方法
##如果key存在, 刪除對應的value值
##如果key不存在,如果沒有提供默認值, 則拋出異常KeyError
#delete_item = students.pop('user6', 'no user')
#print("刪除的元素是: ", delete_item)
#print(students)
#3). popitem方法: 隨機刪除字典的key-value值
key, value = students.popitem()
print("隨機刪除的內容: ", key, value)總結: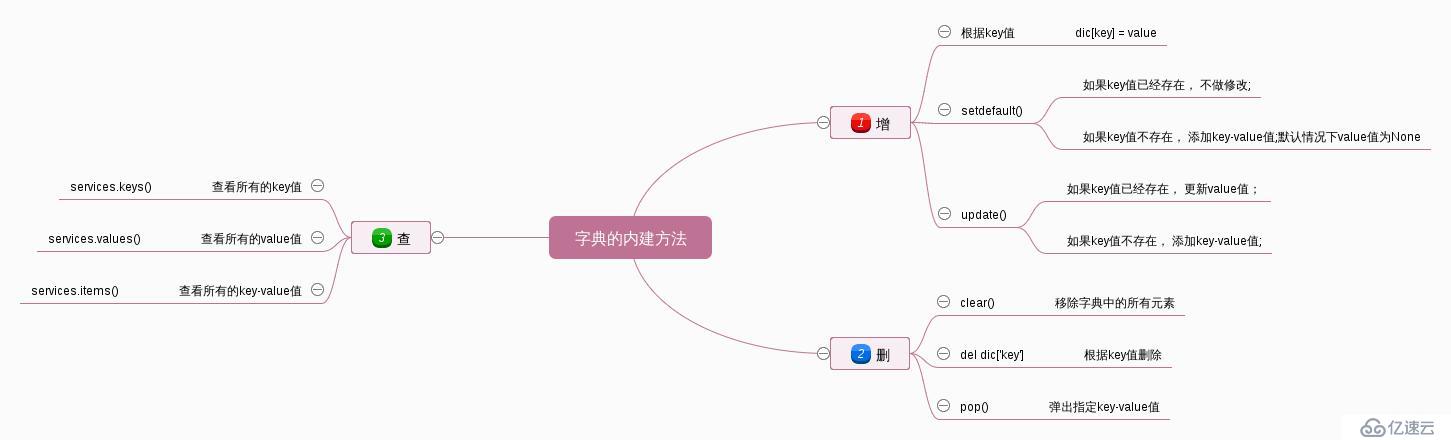
方法三: 通過字典的方式去重, 因為字典的key值是不能重復的.
"""
nums = [1, 2, 3, 1, 2, 3, 6, 7]
print({}.fromkeys(nums).keys()) # {1: None, 2: None, 3: None, 6: None, 7: None} ==> [1, 2, 3, 6, 7]from collections import defaultdict
info = defaultdict(int)
info['a'] += 1
print(info['a'])
info = defaultdict(list)
info['a'].append(1)
print(info['a'])
info = defaultdict(set)
info['a'].add(1)
print(info['a'])
默認字典應用:
from collections import defaultdict
#1). 隨機生成50個1-100之間的隨機數
import random
nums = []
for count in range(50):
nums.append(random.randint(1, 100))
#2). 把list中大于66的元素和小于66的元素分類存儲
sort_nums_dict = defaultdict(list) # 創建一個默認字典, 默認的value為空列表[]
for num in nums:
if num > 66:
sort_nums_dict['大于66的元素'].append(num)
else:
sort_nums_dict['小于66的元素'].append(num)
print(sort_nums_dict)md5加密的實現:
#md5加密需要傳遞的時bytes類型
passwd = b'westos'
md5_passwd = hashlib.md5(passwd).hexdigest()
print(md5_passwd)
#tkinter
#PySimpleGUI
from string import digits
#Python的hashlib提供了常見的摘要算法,如MD5,SHA1等等。hashlib庫進行md5加密,操作如下
import hashlib
#顯示程序運行的進度條
from tqdm import tqdm
import json
db = {}
for item1 in tqdm(digits):
for item2 in digits:
for item3 in digits:
for item4 in digits:
for item5 in digits:
for item6 in digits:
passwd1 = item1 + item2 + item3 + item4 + item5 + item6
#md5加密需要的字符串時bytes類型, 將utf-8的編碼格式編碼成bytes類型
passwd = passwd1.encode('utf-8')
md5_passwd = hashlib.md5(passwd).hexdigest()
db[md5_passwd] = passwd1
#將db字典的信息以json的格式存儲到md5.json文件中
json.dump(db, open('md5.json', 'w'))
print("生成數據庫成功.......")免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





