溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Linux陣列RAID的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、 RAID詳解 二、 mdadm工具介紹 三、 創建一個RAID的基本過程 四、 磁盤陣列的管理 五、 RAID優化
RAID詳解:
描述:RAID:(Redundant Array of indenpensive Disk) 獨立磁盤冗余陣列: 磁盤陣列是把多個磁盤組成一個陣列,當作單一磁盤使用,它將數據以分段(striping)的方式儲存在不同的磁盤中,存取數據時,陣列中的相關磁盤一起動作,大幅減低數據的存取時間,同時有更佳的空間利用率。磁盤陣列利用的不同的技術,稱為RAID level,不同的level針對不同的系統及應用,以解決數據安全的問題。簡單來說,RAID把多個硬盤組合成為一個邏輯扇區,因此,操作系統只會把它當作一個硬盤。 一般高性能的磁盤陣列都是以硬件的形式來達成,進一步的把磁盤存取控制及磁盤陣列結合在一個控制器(RAID controler)或控制卡上,針對不同的用戶解決人們對磁盤輸輸入輸出系統的四大要求: (1)增加存取速度, (2)容錯(fault tolerance),即安全性 (3)有效的利用磁盤利用率; (4)盡量的平衡CPU,內存及磁盤的性能差異,提高主機的整體工作性能。可提供的功能:
1.冗余(容錯)
2.性能提升RAID分類: 1. 硬件RAID:用RAId接口卡來實現;需要內核支持其驅動,并且該類設備設備顯示為SCSI設備,代號為/dev/sd*2. 軟件RAID:用內核中的MD(multiple devices)模塊實現,該類設備在/etc/下表示為:md*;在現在的RH 5版本中使用mdadm工具管理軟RAID;(雖然來說可以用軟件模擬實現raid,但是相對對磁盤控制的功能及性能不如硬件實現的好,生產環境中最好使用硬件raid幾種常見RAID類型描述:
圖示:
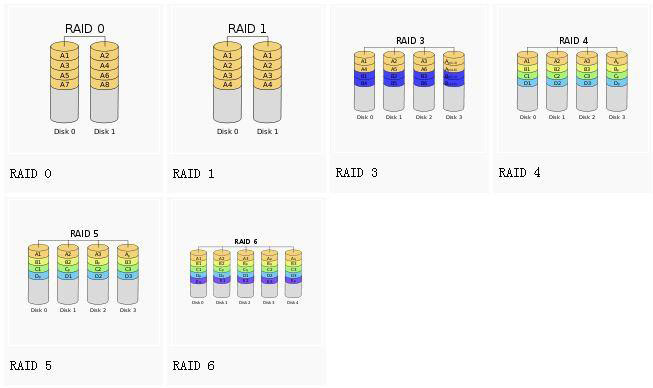
1. RAID-0 :striping(條帶模式),至少需要兩塊磁盤,做RAID分區的大小最好是相同的(可以充分發揮并優勢);而數據分散存儲于不同的磁盤上,在讀寫的時候可以實現并發,所以相對其讀寫性能最好;但是沒有容錯功能,任何一個磁盤的損壞將損壞全部數據;
2. RAID-1:mirroring(鏡像卷),至少需要兩塊硬盤,raid大小等于兩個raid分區中最小的容量(最好將分區大小分為一樣),可增加熱備盤提供一定的備份能力;數據有冗余,在存儲時同時寫入兩塊硬盤,實現了數據備份;但相對降低了寫入性能,但是讀取數據時可以并發,幾乎類似于raid-0的讀取效率;
3. RAID-5 :需要三塊或以上硬盤,可以提供熱備盤實現故障的恢復;采用奇偶效驗,可靠性強,且只有同時損壞兩塊硬盤時數據才會完全損壞,只損壞一塊硬盤時,系統會根據存儲的奇偶校驗位重建數據,臨時提供服務;此時如果有熱備盤,系統還會自動在熱備盤上重建故障磁盤上的數據;
存儲方式:簡單來說就是,磁盤陣列的第一個磁盤分段是校驗值,第二個磁盤至后一個磁盤再折回第一個磁盤的分段是數據,然后第二個磁盤的分段是校驗值,從第三個磁盤再折回第二個磁盤的分段是數據,以此類推,直到放完數據為止。這樣數據與校驗值的循環分離存儲就可以達到一定的故障重建功能;但是raid-5的控制較為復雜,且計算大量的校驗碼,可能給系統造成額外計算的負擔(軟raid來說,硬件有自己的數據處理能力)
注:RAID中的容錯表示即使磁盤故障,數據仍能保持完整,可讓系統存取到正確的數據,而SCSI的磁盤陣列更可在工作中抽換磁盤,并可自動重建故障磁盤的數據。
熱備份(hot spare or hot standby driver):為了加強容錯的功能以及使系統在磁盤故障的情況下能迅速的重建數據,以維持系統的性能,一般的磁盤陣列系統都可使用熱備份(hot spare or hot standby driver)的功能,所謂熱備份是在建立(configure) 磁盤陣列系統的時候,將其中一磁盤指定為后備磁盤,該磁盤在平常并不操作,但若陣列中某一磁盤發生故障時,磁盤陣列即以后備磁盤取代故障磁盤,并自動將故障磁盤的數據重建(rebuild)在后備磁盤之上,因為反應快速,加上快取內存減少了磁盤的存取, 所以數據重建很快即可完成,對系統的性能影響很小。
在任何時候都不要用同一個硬盤上的多個區來做RAID,那樣不僅不能提高系統的性能,反而會大大降低整體系統的系能;
對上面幾種常用的RAID類型分析后,可知,RAID-0主要可以提高磁盤性能,RAID-1主要可以實現備份容錯(RAID-5由于控制機制復雜在此暫不使用),所以可以在實際生產環境下考慮結合RAID-0和RAID-1來實現磁盤存儲系統的高性能、高容錯。
下面圖示的兩種raid結合方式解析:
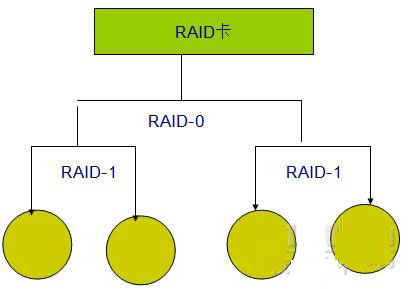
對于一:底層分別用有兩塊硬盤的raid0實現高并發,再集合兩個raid0組實現冗余;下層的任意一個raid0組中有任意一塊硬盤會使改組失效,但是兩外一個組仍能提供全部數據;
對于二:底層用raid-1實現數冗余,上層用raid-2實現高并發,該種結構中任意一個硬盤的故障,不對本組整體數據工作構成破壞性影響;所以感覺該種方案更優異,在實際生產中有部分應用(具體配置過程再文章最后附);
mdadm工具介紹:
描述: mdadm(multiple devices admin)是 linux下標準的的軟raid管理工具,是一個模式化工具(在不同的模式下);程序工作在內存用戶程序區,為用戶提供RAID接口來操作內核的模塊,實現各種功能;RedHat已經內置了該工具;官方最新的版本應該是3.2,需要最新版本可以到官方網站下載或http://www.kernel.org/pub/linux/utils/raid/mdadm/下載源碼包進行編譯安裝(官網一直打不開o(╯□╰)o).
實驗環境:RedHhat5.4 ;mdadm版本為v2.6.9 ;
可能不同的版本選項等略有變動,使用時請注意對照自己版本的man文檔;
基本語法:
# mdadm [mode] <raid-device> [options] <component-devices>
目前支持的模式: LINEAR(線性模式)、RAID0(striping條帶模式)、RAID1(mirroring)、 RAID-4、RAID-5、 RAID-6、 RAID-10、 MULTIPATH和FAULTY
LINEAR:線性模式,該模式不是raid的標準模式,其主要作用是可以實現將幾塊小的硬盤組合為一塊大硬盤來使用;數組存儲時一次存滿一個硬盤在使用下一個硬盤;對上層來說操作的是一個大硬盤
模式(7種): Assemble:裝配模式:加入一個以前定義的陣列;可以使挺值得陣列或從其他主機移出的陣列
Build: 創建:創建一個沒有超級塊的陣列Create: 創建一個新的陣列,每個設備具有超級塊
Follow or Monitor: 監控RAID的狀態,一般只對RAID-1/4/5/6/10等有冗余功能的模式來使用
Grow:(Grow or shrink) 改變RAID的容量或陣列中的設備數目;收縮一般指的是數據收縮或重建;
Manage: 管理陣列(如添加spare盤和刪除故障盤)
Incremental Assembly:添加一個設備到一個適當的陣列。
Misc: 允許單獨對陣列中的某個設備進行操作(如抹去superblocks 或停止陣列)
Auto-detect: 此模式不作用于特定的設備或陣列,而是要求在Linux內核啟動任何自動檢測到的陣列。
OPTIONS:
選擇一個模式的選項:(Options for selecting a mode)
-A, --assemble: 加入并開啟一個以前定義的陣列
-B, --build: 創建一個沒有超級塊的陣列(Build a legacy array without superblocks.)
-C, --create: 創建一個新的陣列
-F, --follow, --monitor:選擇監控(Monitor)模式-
G, --grow: 改變激活陣列的大小或形態-I,
--incremental: 添加一個單獨的設備到合適的陣列,并可能啟動陣列
--auto-detect: 請求內核啟動任何自動檢測到的陣列
不特定于一個模式的選項:(Options that are not mode-specific)
-c, --config=: 指定配置文件,缺省為 /etc/mdadm.conf
-s, --scan: 掃描配置文件或 /proc/mdstat以搜尋丟失的信息。默認配置文件:/etc/mdadm.conf
-h, --help: 幫助信息,用在以上選項后,則顯示該選項信息
-v, --verbose: 顯示細節,一般只能跟 --detile 或 --examine一起使用,顯示中級的信息;
-b, --brief: 較少的細節。用于 --detail 和 --examine 選項
--help-options: 顯示更詳細的幫助
-V, --version: 版本信息
-q,--quit: 安靜模式;加上該選項能使mdadm不顯示純消息性的信息,除非那是一個重要的報告;
create build 或grow時使用的選項:
-n, --raid-devices=: 指定陣列中活動的device數目,不包括spare磁盤,這個數目只能由--grow修改
-x, --spare-devices=:指定初始陣列的冗余device 數目即spare device數目;
-c, --chunk=: Specify chunk size of kibibytes. 缺省為 64. chunk-size是一個重要的參數,決定了一次向陣列中每個磁盤寫入數據的量
(Chunk :,可以理解為raid分儲數據時每個數據段的大小(通常為32/64/128等這類數字大小);合理的選擇chunk大小非常重要,若chunk過大可能一塊磁盤上的帶區空間就可以滿足大部分的I/O操作,使得數據的讀寫只局限于一塊硬盤上,這便不能充分發揮RAID并發的優勢;如果chunk設置過小,任何很小的I/O指令都 可能引發大量的讀寫操作,不能良好發揮并發性能,占用過多的控制器總線帶寬,也影響了陣列的整體性能。所以,在創建帶區時,我們應該根據實際應用的需要,合理的選擇帶區大小。)
-z, --size=:組建RAID1/4/5/6后從每個device獲取的空間總數;但是大小必須為chunk的倍數,還需要在每個設備最后給RAID的superblock留至少128KB的大小。
--rounding=: Specify rounding factor for linear array (==chunk size)
-l, --level=: 設定 raid level.raid的幾倍-
-create: 可用:linear, raid0, 0, stripe, raid1,1, mirror, raid4, 4, raid5, 5, raid6, 6, multipath, mp.
--build: 可用:linear, raid0, 0, stripe
.-p, --layout=:設定raid5 和raid10的奇偶校驗規則;并且控制故障的故障模式;其中RAID-5的奇偶校驗可以在設置為::eft-asymmetric, left-symmetric, right-asymmetric, right-symmetric, la, ra, ls, rs.缺省為left-symmetric
--parity: 類似于--layout=
--assume-clean:目前僅用于 --build 選項
-R, --run: 陣列中的某一部分出現在其他陣列或文件系統中時,mdadm會確認該陣列。此選項將不作確認。
-f, --force: 通常mdadm不允許只用一個device 創建陣列,而且此時創建raid5時會使用一個device作為missing drive。此選項正相反
-N,--name=: 設定陣列的名稱
管理模式選項(For Manage mode):
-a, --add: 添加列出的設備到一個工作的陣列中;當陣列處于降級狀態(故障狀態),你添加一個設備,該設備將作為備用設備并且在該備用設備上開始數據重建。-r, --remove:從陣列中移除列出的設備,并且該設備不能處于活動狀態(是冗余盤或故障盤);
-f,--fail:將列出的設備標記為faulty狀態,標記后就可以移除設備;(可以作為故障恢復的測試手段)--set-faulty:同上
監控模式選項(For Monitor mode):
-m, --mail: 設置一個mail地址,在報警時給該mail發信;該地址可寫入conf文件,在啟動陣列是生效
-p, --program, --alert:當檢測到一個事件時運行一個指定的程序
-y, --syslog: 設置所有的事件記錄于syslog中
-t, --test: 給啟動時發現的每個陣列生成test警告信息;該信息傳遞給mail或報警程序;(以此來測試報警信息是否能正確接收)
MISC模式選項: Usage: mdadm options ... devices ...
-Q, --query: 查看一個device,判斷它為一個 md device 或是 一個 md 陣列的一部分
-D, --detail: 打印一個或多個md device 的詳細信息
-E, --examine:打印 device 上的 md superblock 的內容創建一個軟RAID的基本過程:
(以三個分區模擬創建一個raid5為操作示例,對于level0/1的How-To不再寫出,如果理解原理,配置真的很簡單;)
1. 生成raid組成: linux中陣列組成單元是分區,分區可以是整個設備也可以是設備多個分區中的一個;在fdisk分區后需要將分區標志改為Linux raid auto類型;
# 分區后如下:
Device Boot Start End Blocks Id System
/dev/sdb1 1 609 4891761 fd Linux raid autodetect
/dev/sdc1 1 609 4891761 fd Linux raid autodetect
/dev/sdd1 1 609 4891761 fd Linux raid autodetect
2. 建立磁盤陣列
# mdadm -C /dev/md0 -a yes -l 5 -n 3 /dev/sd{b,c,d}1
mdadm: array /dev/md0 started.
-C :創建一個陣列,后跟陣列名稱
-l :指定陣列的級別;
-n :指定陣列中活動devices的數目
3. 查看陣列狀態
[root@bogon ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd1[2] sdc1[1] sdb1[0]
9783296 blocks level 5, 64k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
通過cat /proc/mdstat信息查看所有運行的RAID陣列的狀態,在第一行中首先是MD的設備名md0,active和inactive選項表示陣列是否能讀/寫,接著是陣列的RAID級別raid5,后面是屬于陣列的塊設備,方括號[]里的數字表示設備在陣列中的序號,(S)表示其是熱備盤,(F)表示這個磁盤是 faulty狀態。下一行中首先是陣列的大小,用塊數來表示;后面有chunk-size的大小,然后是layout類型,不同RAID級別的 layout類型不同,[3/3] [UUU]表示陣列有3個磁盤并且3個磁盤都是正常運行的,而[2/3]和[_UU] 表示陣列有3個磁盤中2個是正常運行的,下劃線對應的那個位置的磁盤是faulty狀態的。
查看陣列的詳細信息:
[root@bogon ~]# mdadm --detail /dev/md0
/dev/md0:
Version : 0.90
Creation Time : Tue Mar 15 08:17:52 2011
Raid Level : raid5
Array Size : 9783296 (9.33 GiB 10.02 GB)
Used Dev Size : 4891648 (4.67 GiB 5.01 GB)
Raid Devices : 3
Total Devices : 3
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Tue Mar 15 08:20:25 2011
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric 校驗規則
Chunk Size : 64K
UUID : e0d929d1:69d7aacd:5ffcdf9b:c1aaf02d
Events : 0.2
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1
2 8 49 2 active sync /dev/sdd1
4. mdadm.conf配置:mdadm.conf是該軟件的默認配置文件,主要作用是方便跟蹤軟RAID的配置,尤其是可以配置監視和事件上報選項。其中寫入每一個陣列組成的詳細情況,用于在下次開啟陣列后依據此文件重新裝配(assemble)開啟陣列,否則就需要在開啟時手動定義陣列中的成員;當然是推薦創建該文件,防止出現意外情況,具體的詳細配置及示例可以參看man文檔# man mdadm.conf
[root@bogon ~]# echo "DEVICE /dev/sdb1 /dev/sdc1 /dev/sdd1 " >> /etc/mdadm.conf
[root@bogon ~]# mdadm -Ds >> /etc/mdadm.conf
[root@bogon ~]# echo "MAILADDR mospiral@gmail.com" >> /etc/mdadm.conf
MAILADDR指定出問題時監控系統發郵件的地址
# 格式如下:
DEVICE /dev/sdb1 /dev/sdc1 /dev/sdd1
ARRAY /dev/md0 level=raid5 num-devices=3 metadata=0.90 UUID=e0d929d1:69d7aacd:5ffcdf9b:c1aaf02d
MAILADDR mospiral@gmail.com
#DEVICE行指明:依據該配置文件開啟陣列時,去查找那些設備的超級快信息;若沒有該行,
就去搜索mtab中所有設備分區的超級快信息;所以改行可以不寫,但是只要寫上,以后添加spare
設備時就需要同時修改改行信息;
#ARRAY 行指明raid的名稱,級別uuid等基本信息
#可以添加諸如MAILADDR及PROGRAM等指定monitor狀態下的監控報警信息;
磁盤陣列的管理: 可以在manage模式下對磁盤進行各種管理工作;
給raid-5新增一個spare盤:
[root@bogon ~]# mdadm -a /dev/md0 /dev/sda5
mdadm: added /dev/sda5
此時查看狀態:
[root@bogon ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda5[3](S) sdd1[2] sdc1[1] sdb1[0]
9783296 blocks level 5, 64k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
模擬硬盤故障:
[root@bogon ~]# mdadm -f /dev/md0 /dev/sdd1
mdadm: set /dev/sdd1 faulty in /dev/md0
# 此時查看狀態,發現概念剛才的熱備盤已經頂替了故障盤的位置,
# 并且進度條顯示數據重建過程:
[root@bogon ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda5[3] sdd1[4](F) sdc1[1] sdb1[0]
9783296 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_]
[>....................] recovery = 1.3% (66912/4891648) finish=6.0min speed=13382K/sec
unused devices: <none>
熱移除故障的硬盤:
[root@bogon ~]# mdadm -r /dev/md0 /dev/sdd1
mdadm: hot removed /dev/sdd1
[root@bogon ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda5[3] sdc1[1] sdb1[0]
9783296 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_]
[===>.................] recovery = 16.1% (792136/4891648) finish=4.6min speed=14828K/sec
unused devices: <none>
對于有冗余的raid形式,在單一磁盤故障時一般能在一段時間內重建數據;但是數據量非常大時,重建會非常緩慢,且重建過程系統壓力比較大,此時需要多關注系統負載,防止重建過程出現錯誤;在熱移除故障盤一戶,也需要盡快的換上新硬盤,并且添加spare盤;在故障修復,重建重建之后,需要重新生成配置文件,防止在下次開啟時,按照最初的定義模式開啟;
停止RAID:
# 指定停止某個陣列
[root@bogon ~]# mdadm -S /dev/md0
# 停止配置文件中定義的所有陣列
[root@bogon ~]# mdadm -Ss
mdadm: stopped /dev/md0
# -s –scan去查詢配置文件或沒有配置文件時查詢mdstat中的所有陣列
開啟RAID:
[root@bogon ~]# mdadm -As
mdadm: /dev/md0 has been started with 2 drives (out of 3).
# -s –scan:根據配置文件開啟所有的陣列,此時由于故障恢復過,
# 但是由于未重建配置文件,陣列我不能加載上新添加的硬盤;(需要停掉,重新手動指定)
[root@bogon ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb1[0] sdc1[1]
9783296 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_]
unused devices: <none>
若此時沒有配置文件,就需要手動指定設備名稱:
[root@bogon ~]# mdadm -A /dev/md0 /dev/sdb1 /dev/sdc1 /dev/sda5
mdadm: /dev/md0 has been started with 3 drives.
# 注:將一個raid設備添加入md陣列后,md的信息會寫入到該設備分區的superblock中;
# 在手動裝配時;mdadm工具會自動驗證陣列配置是否合法,并且做出相應的動作;
若新接手一個raid,沒有配置文件,或忘記設備的準確組成,就需要按分區逐個檢查是否是raid設備及其他信息,然后根據信息裝配陣列:
[root@bogon ~]# mdadm -E /dev/sdb1
/dev/sdb1:
Magic : a92b4efc
Version : 0.90.00
UUID : e0d929d1:69d7aacd:5ffcdf9b:c1aaf02d
Creation Time : Tue Mar 15 08:17:52 2011
Raid Level : raid5
Used Dev Size : 4891648 (4.67 GiB 5.01 GB)
Array Size : 9783296 (9.33 GiB 10.02 GB)
Raid Devices : 3
Total Devices : 3
Preferred Minor : 0
Update Time : Tue Mar 15 09:25:10 2011
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Checksum : b0cd088f - correct
Events : 8
Layout : left-symmetric
Chunk Size : 64K
Number Major Minor RaidDevice State
this 0 8 17 0 active sync /dev/sdb1
0 0 8 17 0 active sync /dev/sdb1
1 1 8 33 1 active sync /dev/sdc1
2 2 8 5 2 active sync /dev/sda5
# 該處顯示出的是該分區superblock中包含的md信息;沒有配置文件時,可以依據該信息裝配md;
刪除陣列:
若需要徹底清除這個陣列:
[root@bogon ~]# umount /dev/md0
mdadm -Ss /dev/md0
[root@bogon ~]# mdadm --zero-superblock /dev/sd{b,c,d}1
# --zero-superblock 加上該選項時,會判斷如果該陣列是否包
# 含一個有效的陣列超級快,若有則將該超級塊中陣列信息抹除。
[root@bogon ~]# rm /etc/mdadm.conf
RAID優化:
(1) 設置stride值
The stride is the software RAID device's chunk-size in filesystem blocks.For example,with an ext3 filesystem that will have an 4KB block size on a RAID device with a chunk-size of 64KB, the stride should be set to 16:(翻譯的很糾結,就貼上教材原文了。)
mk2fs -j -b 4096 -E stride=16 /dev/md0
# 設置時,需要用-E選項進行擴展
設定良好的stride值,可以在后期使用時,減少寫入數據時對數據塊計算的負擔,從而提高RAID性能;
附:RAID 1-0雙層架構的方法:
首先創建兩個底層RAID-1
[root@bogon ~]# mdadm -C /dev/md0 -a yes -l 1 -n 2 /dev/sd[bc]1
mdadm: array /dev/md0 started.
[root@bogon ~]# mdadm -C /dev/md1 -a yes -l 1 -n 2 /dev/sd[bc]2
mdadm: array /dev/md1 started.
用兩個RAID-1實現上層RAID-0:
[root@bogon ~]# mdadm -C /dev/md2 -a yes -l 0 -n 2 /dev/md[01]
mdadm: array /dev/md2 started.
查看陣列狀態:
[root@bogon ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [raid0] [raid1]
md2 : active raid0 md0[0] md1[1]
9783232 blocks 64k chunks
md1 : active raid1 sdb2[0] sdc2[1]
4891712 blocks [2/2] [UU]
md0 : active raid1 sdb1[0] sdc1[1]
4891648 blocks [2/2] [UU]
unused devices: <none>
創建配置文件:
[root@bogon ~]# mdadm -Ds > /etc/mdadm.conf
停止與開啟陣列:
[root@bogon ~]# mdadm -Ss
mdadm: stopped /dev/md2
mdadm: stopped /dev/md1
mdadm: stopped /dev/md0
[root@bogon ~]# mdadm -As
mdadm: /dev/md0 has been started with 2 drives.
mdadm: /dev/md1 has been started with 2 drives.
mdadm: /dev/md2 has been started with 2 drives.
##上述關閉與開啟過程,系統能只能識別層級,關閉先關閉上層,
##后開啟上層;防止了沖突;
關于“Linux陣列RAID的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





