溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
AOF持久化及AOF重寫的配置:
默認AOF方式是關閉的,如下圖:
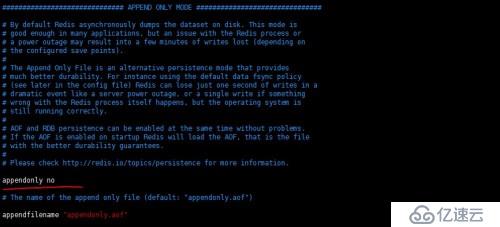
如果要開啟的話,就是把no改寫成yes。如下圖:

默認文件名稱appendonly.aof,你也可以修改文件名。默認保存目錄同樣也是配置文件中dir配置項中的設置,它和RDB共用一個目錄。如下圖:

默認同步策略是每秒,如下圖:

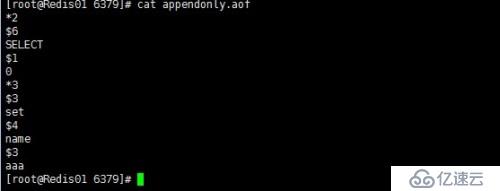
我們對數據庫做一些操作然后查看一下appendonly.aof文件內容

它會記錄所有寫操作內容。
| *2 | 表示2個參數 |
| $6 | 表示第一個參數長度為6 |
| SELECT | 第一個參數 |
| $1 | 第二個參數長度為1 |
| 0 | 第二個參數 |
AOF重寫策略
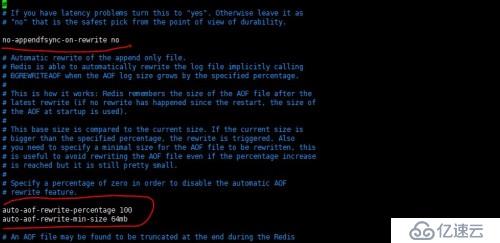
AOF持久化實現原理:
當AOF持久化開啟后,當對數據庫進行一次更新操作后,更新命令就會被追加到aof_buf緩沖區的末尾,然后由緩沖區寫入到AOF文件。
AOF文件中記錄的內容就是對數據更新操作的指令。這個文件本身就是以文本來記錄的,如下圖:
當需要恢復數據的時候,通過執行AOF文件中記錄的更新指令,就可以完成。人為的看里面的指令,然后手動敲命令也可以完成。
AOF重寫實現原理:
因為AOF持久化是通過記錄命令的方式來保存數據庫狀態的,隨著時間的推移AOF文件肯定會逐漸增大,如果不加以控制會對AOF持久化性能以及數據恢復造成影響。下面舉例來更加形象的說明重寫的必要:
我們以一個壓縮列表為例

根據AOF的原理,那么上面紅色方框中的5條命令都要追加到AOF文件中,其實我們看到最后list的狀態就是BCDEF值。也就是說為例實現最后的狀態,需要追加5條命令。所以在大量內存讀寫的業務里AOF文件增長的很快,為例解決這個問題,Redis提供了AOF重寫功能。
AOF重寫就是創建一個新的AOF文件來替換現有的AOF文件,實際上AOF重寫并不對現有的舊AOF文件進行操作。
以上面例子來說,當進行重寫的時候直接從數據庫里去獲取list的最新狀態,然后在新的AOF文件中直接寫一條rpushlist B C D E F命令,從而避免寫5條的操作,這樣AOF文件的增長速度就會降低,同時容量也不會特別大。
AOF重寫程序aof_rewrite函數去完成創建新的AOF文件的任務,但是該函數并不會由Redis主進程去直接調用,而是使用子進程后臺去執行(BGREWRITEAOF,該命令其實就是執行aof_rewrite,只不過是由子進程去調用的),這時主進程就會不被阻塞,那么就可以在執行重寫的過程中父進程可以繼續對外提供響應。整個過程如下:
當重寫被觸發時父進程調用一個函數,該函數創建一個子進程用于執行BGREWRITEAOF,該子進程創建一個臨時文件,然后父進程繼續對外提供讀寫服務
子進程遍歷數據庫,將每個鍵值的最新狀態輸出到臨時文件中,在BGREWRITEAOF過程中,父進程把所有對數據庫的更新命令同時寫入到AOF緩沖區和AOF重寫緩沖區(aof_rewrite_buf_blocks),AOF緩沖區(aof_buf)會繼續同步到現有AOF文件中(一般情況下在AOF重寫期間不建議把AOF緩沖區的內容同步到現有的AOF文件中,這會降低性能,默認為NO)
AOF重寫完成后子進程通知父進程,父進程調用信號處理函數
信號處理函數會阻塞父進程對外提供讀寫操作(時間很短,不阻塞就又會出現數據不一致的情況),然后將AOF重寫緩沖區的內容寫入到新的AOF文件中,最后用新的AOF文件替換現有AOF文件(更名操作)
APPENDFSYNC選項說明:
| 參數 | 說明 |
| always | 將aof_buf緩沖區中的所有內容寫入并同步到AOF文件中,立即執行write()和fsync()系統調用。對于數據的安全性最高,但是執行最慢,如果出現故障只會丟失一個事件循環的內容。 |
| everysec | 將aof_buf緩沖區的所有內容寫入到AOF文件,如果上次同步AOF的時間距離本次超過1秒,則執行同步,每隔一秒執行一次write()和fsync()系統調用。數據安全性居中,執行快,僅會丟失1秒的數據。 |
| no | 將aof_buf緩沖區的所有內容寫入到AOF文件,但是何時同步由操作系統決定,僅執行write()系統調用。寫入動作效率高,但是不執行同步,但是單次同步消耗時間最長,數據安全性最低,會丟失上一次同步之后的所有數據。 |
這里要特別說明一下Linux系統的文件寫入和同步原理,為什么要說這個,因為不解釋一下這個過程,你就很難理解APPENDFSYNC選項中的no參數,如果把Always理解為總是、一直或者實時;而把everysec理解為每秒的話,那no的含義難道是不執行AOF文件同步嗎?如果不同步文件,那開啟AOF持久化干嘛呢?
在Redis調用appendfsync函數的時候,其實是先調用一個write()函數,然后再調用sync()或者fsync()函數(對于任何程序來說只要想把數據寫入磁盤其過程都一樣,有些也有例外)。
用戶空間:常規進程所在區域,用戶發起的,此區域的代碼不能直接訪問硬件
內核空間:操作系統所在區域,能和設備控制器通訊
當調用了write()函數時,該函數一旦返回正常值,我們可能就認為數據已經寫入到了磁盤,但實際上,操作系統在實現磁盤文件的IO時,為了保證IO的效率,會在內存中使用一段專門的地址空間,該空間叫做內核空間,而內核空間之內又會有一段是用作IO的數據緩沖區(這個緩沖區和之前說的aof_buf緩沖區不是一個概念,雖然都在內存中),write()函數的作用就是把數據寫入到內核空間的IO緩沖區中。

內核空間的IO緩沖區也有一定大小,當該緩沖區沒有寫滿時或者沒有到一個同步周期時,會持續的把write()函數傳遞的數據寫入到該緩沖區中,而當該緩沖區寫滿或者到了一個同步周期,則會把該緩沖區的內容提交到輸出隊列,當需要數據到達隊列隊首的時候,開始執行真正的磁盤IO操作,把數據寫入磁盤(這里雖然用來寫入磁盤,但是真正的動作不是移動而是復制,復制完成之后,內核空間的IO緩沖區才會釋放該數據占用的空間)。這種方式叫做延遲寫入。
所以這就會出現一個問題,當調用了write()函數后并不等于數據真的保存到了磁盤,但是這里又會有一個錯覺,就是你再次請求該文件的時候,可以顯示你最后一次更新的內容,其實這個內容并不是從磁盤上讀取過來的,而是從用戶空間的緩沖區讀取的。接著剛才提到的問題,如果數據在內核空間的IO緩沖區內,而此時操作系統出現故障、斷電等異常情況就會造成數據丟失。
為了解決數據丟失問題,Unix系統提供了sync、fsync和fdatasync三個函數。
| 函數 | 功能 |
| sync | 函數返回0表示成功,該函數負責把所有內核空間中IO緩沖區內修改過的內容推送到輸入隊列,然后就返回,它并不等待所有磁盤IO操作完成。所以即使調用了sync函數,也不等于成功保存到磁盤了。 |
| fsync | 函數返回0表示成功,與sync不同,它只會對指定文件描述符的單一文件生效,強制與該文件相連的所有修改過的數據傳送到磁盤上,并且等待磁盤IO完畢,然后返回。當該函數返回0時,才真正表示成功保存到磁盤。數據庫會在調用了write()之后調用fsync()。 |
| fdatasync | 它與fsync類似,它只影響文件數據部分,不涉及數據屬性,比如inode信息。所以相對于fsync它需要較少的寫磁盤操作。 |
所以看了上面的內容,你就知道APPENDFSYNC中no參數的含義.
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





