溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1 Hive簡介
1.1 Hive定義
Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供類SQL查詢功能。
本質是將SQL轉換為MapReduce程序。
1.2 為什么使用Hive
1、面臨的問題
人員學習成本太高
項目周期要求太短
我只是需要一個簡單的環境
MapReduce 如何搞定
復雜查詢好難
Join如何實現
2、為什么要使用Hive
操作接口采用類SQL語法,提供快速開發的能力
避免了去寫MapReduce,減少開發人員的學習成本
擴展功能很方便
1.3 Hive特點
1、可擴展
Hive可以自由的擴展集群的規模,一般情況下不需要重啟服務
2、延展性
Hive支持用戶自定義函數,用戶可以根據自己的需求來實現自己的函數
3、容錯
良好的容錯性,節點出現問題SQL仍可完成執行
1.4 Hive與Hadoop的關系
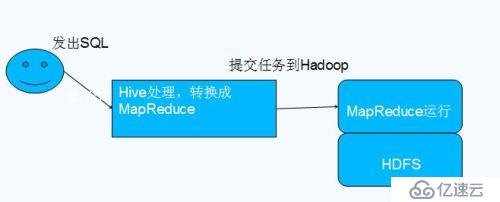
1.5 Hive與傳統數據庫的關系
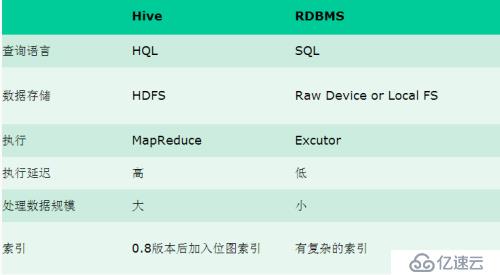
1.6 Hive的歷史
由FaceBook 實現并開源
2011年3月,0.7.0版本 發布,此版本為重大升級版本,增加了簡單索引,HAING等眾多高級特性
2011年06月,0.7.1 版本發布,修復了一些BUG,如在Windows上使用JDBC的的問題
2011年12月,0.8.0版本發布,此版本為重大升級版本,增加了insert into 、HA等眾多高級特性
2012年2月5日,0.8.1版本發布,修復了一些BUG,如使 Hive 可以同時運行在 Hadoop0.20.x 與 0.23.0
2012年4月30日,0.9.0版本發布,重大改進版本,增加了對Hadoop 1.0.0的支持、實現BETWEEN等特性。
1.7 Hive的未來發展
增加更多類似傳統數據庫的功能,如存儲過程
提高轉換成的MapReduce性能
擁有真正的數據倉庫的能力
UI部分加強
2 軟件準備與環境規劃
2.1 Hadoop環境介紹
Hadoop安裝路徑:/home/test/Desktop/hadoop-1.0.0/
Hadoop元數據存放目錄:/home/test/data/core/namenode
Hadoop數據存放路徑:/home/test/data/core/datanode
Hive安裝路徑:/home/test/Desktop/
Hive數據存放路徑:/user/hive/warehouse
Hive元數據
第三方數據庫:derby mysql
2.2 軟件準備
OS
ubuntu
JDK
java 1.6.0_27
Hadoop
hadoop-1.0.0.tar
Hive
hive-0.8.1.tar
2.3 項目結構

2.4 Hive配置文件介紹
1、Hive配置文件介紹
hive-site.xml hive的配置文件
hive-env.sh hive的運行環境文件
hive-default.xml.template 默認模板
hive-env.sh.template hive-env.sh默認配置
hive-exec-log4j.properties.template exec默認配置
hive-log4j.properties.template log默認配置
2、hive-site.xml
< property> <name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connectstring for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver classname for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username touse against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>test</value> <description>password touse against metastore database</description> </property>
3、hive-env.sh
配置Hive的配置文件路徑:export HIVE_CONF_DIR= your path
配置Hadoop的安裝路徑:HADOOP_HOME=your hadoop home
2.5 使用Derby數據庫的安裝方式
1、什么是Derby安裝方式
ApacheDerby是一個完全用java編寫的數據庫,所以可以跨平臺,但需要在JVM中運行
Derby是一個Open source的產品,基于Apache License 2.0分發
即將元數據存儲在Derby數據庫中,也是Hive默認的安裝方式。
2、安裝Hive
解壓Hive:tar zxvf hive-0.8.1.tar /home/test/Desktop
建立軟連接:ln –s hive-0.8.1 hive
添加環境變量
export HIVE_HOME=/home/test/Desktop/hive export PATH=….HIVE_HOME/bin:$PATH:.
3、配置Hive
進入hive/conf目錄
依據hive-env.sh.template,創建hive-env.sh文件
cp hive-env.sh.template hive-env.sh
修改hive-env.sh
指定hive配置文件的路徑
export HIVE_CONF_DIR=/home/test/Desktop/hive/conf
指定Hadoop路徑
HADOOP_HOME=/home/test/Desktop/hadoop
4、hive-site.xml
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=metastore_db;create=true</value> <description>JDBCconnect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.apache.derby.jdbc.EmbeddedDriver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>APP</value> <description>username to use against metastoredatabase</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>mine</value> <description>password to use against metastoredatabase</description> </property>
5、啟動hive
命令行鍵入
Hive
顯示
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Pleaseuse org.apache.hadoop.log.metrics.EventCounter in all the log4j.propertiesfiles. Logging initialized using configuration injar:file:/home/test/Desktop/hive-0.8.1/lib/hive-common-0.8.1.jar!/hive-log4j.properties Hive historyfile=/tmp/test/hive_job_log_test_201208260529_167273830.txt hive>
5、測試語句
建立測試表test
createtable test (key string); showtables;
2.6 使用MySQL數據庫的安裝方式
1、安裝MySQL
Ubuntu 采用apt-get安裝
sudo apt-get install mysql-server
建立數據庫hive
create database hive
創建hive用戶,并授權
grant all on hive.* to hive@'%' identified by 'hive'; flush privileges;
2、安裝Hive
解壓Hive:
tar zxvf hive-0.8.1.tar /home/test/Desktop
建立軟連接:
ln –s hive-0.8.1 hive
添加環境變量
exportHIVE_HOME=/home/test/Desktop/hive exportPATH=….HIVE_HOME/bin:$PATH:.
3、修改hive-site.xml
<property> <name>javax.jdo.option.ConnectionURL </name> <value>jdbc:mysql://localhost:3306/hive </value> </property> <property> <name>javax.jdo.option.ConnectionDriverName </name> <value>com.mysql.jdbc.Driver </value> </property> <property> <name>javax.jdo.option.ConnectionPassword </name> <value>hive </value> </property> <property> <name>hive.hwi.listen.port </name> <value>9999 </value> <description>This is the port the Hive Web Interface will listenon </descript ion> </property> <property> <name>datanucleus.autoCreateSchema </name> <value>false </value> </property> <property> <name>datanucleus.fixedDatastore </name> <value>true </value> </property> <property> <name>hive.metastore.local </name> <value>true </value> <description>controls whether toconnect to remove metastore server or open a new metastore server in HiveClient JVM </description> </property>
4、啟動Hive
命令行鍵入:Hive
顯示
WARNING: org.apache.hadoop.metrics.jvm.EventCounter isdeprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all thelog4j.properties files. Logging initialized using configuration injar:file:/home/test/Desktop/hive-0.8.1/lib/hive-common-0.8.1.jar!/hive-log4j.properties Hive historyfile=/tmp/test/hive_job_log_test_201208260529_167273830.txt hive>
5、測試語句
建立測試表test
create table test (key string); show tables;
3 Hive內建操作符與函數開發
3.1 關系運算符
等值比較: =
不等值比較: <>
小于比較: <
小于等于比較: <=
大于比較: >
大于等于比較: >=
空值判斷: IS NULL
非空判斷: IS NOT NULL
LIKE比較: LIKE
JAVA的LIKE操作: RLIKE
REGEXP操作: REGEXP
等值比較: =
語法:A=B
操作類型:所有基本類型
描述: 如果表達式A與表達式B相等,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where 1=1;
不等值比較: <>
語法: A <> B
操作類型: 所有基本類型
描述: 如果表達式A為NULL,或者表達式B為NULL,返回NULL;如果表達式A與表達式B不相等,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where 1 <> 2;
小于比較: <
語法: A < B
操作類型: 所有基本類型
描述: 如果表達式A為NULL,或者表達式B為NULL,返回NULL;如果表達式A小于表達式B,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where 1 < 2;
小于等于比較: <=
語法: A <= B
操作類型: 所有基本類型
描述: 如果表達式A為NULL,或者表達式B為NULL,返回NULL;如果表達式A小于或者等于表達式B,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where 1 <= 1;
大于等于比較: >=
語法: A >= B
操作類型: 所有基本類型
描述: 如果表達式A為NULL,或者表達式B為NULL,返回NULL;如果表達式A大于或者等于表達式B,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where 1 >= 1;
空值判斷: IS NULL
語法: A IS NULL
操作類型: 所有類型
描述: 如果表達式A的值為NULL,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where null is null;
非空判斷: IS NOT NULL
語法: A IS NOT NULL
操作類型: 所有類型
描述: 如果表達式A的值為NULL,則為FALSE;否則為TRUE
舉例:hive> select 1 from dual where 1 is not null;
LIKE比較: LIKE
語法: A LIKE B
操作類型: strings
描述: 如果字符串A或者字符串B為NULL,則返回NULL;如果字符串A符合表達式B 的正則語法,則為TRUE;否則為FALSE。B中字符”_”表示任意單個字符,而字符”%”表示任意數量的字符。
舉例:hive> select 1 from dual where ‘key' like 'foot%';
hive> select 1 from dual where ‘key ' like'foot____';
注意:否定比較時候用 NOT A LIKE B
hive> select 1 from dual where NOT ‘key ' like 'fff%';
JAVA的LIKE操作: RLIKE
語法: A RLIKE B
操作類型: strings
描述: 如果字符串A或者字符串B為NULL,則返回NULL;如果字符串A符合JAVA正則表達式B的正則語法,則為TRUE;否則為FALSE。
舉例:hive> select 1 from dual where 'footbar’ rlike'^f.*r$’;
注意:判斷一個字符串是否全為數字:
hive>select 1 from dual where '123456' rlike '^\\d+$';
hive> select 1 from dual where '123456aa' rlike'^\\d+$';
REGEXP操作: REGEXP
語法: A REGEXP B
操作類型: strings
描述: 功能與RLIKE相同
舉例:hive> select 1 from dual where ‘key' REGEXP'^f.*r$';
3.2 邏輯運算與數學運算
加法操作: +
減法操作: -
乘法操作: *
除法操作: /
取余操作: %
位與操作: &
位或操作: |
位異或操作: ^
位取反操作: ~
邏輯與操作: AND
邏輯或操作: OR
邏輯非操作: NOT
取整函數: round
指定精度取整函數: round
向下取整函數: floor
向上取整函數: ceil
向上取整函數: ceiling
取隨機數函數: rand
自然指數函數: exp
以10為底對數函數: log10
以2為底對數函數: log2
對數函數: log
冪運算函數: pow
冪運算函數: power
開平方函數: sqrt
二進制函數: bin
十六進制函數: hex
反轉十六進制函數: unhex
進制轉換函數: conv
絕對值函數: abs
正取余函數: pmod
正弦函數: sin
反正弦函數: asin
余弦函數: cos
反余弦函數: acos
positive函數: positive
negative函數: negative
UNIX時間戳轉日期函數: from_unixtime
獲取當前UNIX時間戳函數: unix_timestamp
日期轉UNIX時間戳函數: unix_timestamp
指定格式日期轉UNIX時間戳函數: unix_timestamp
日期時間轉日期函數: to_date
日期轉年函數: year
日期轉月函數: month
日期轉天函數: day
日期轉小時函數: hour
日期轉分鐘函數: minute
日期轉秒函數: second
日期轉周函數: weekofyear
日期比較函數: datediff
日期增加函數: date_add
日期減少函數: date_sub
If函數: if
非空查找函數: COALESCE
條件判斷函數:CASE
字符串長度函數:length
字符串反轉函數:reverse
字符串連接函數:concat
帶分隔符字符串連接函數:concat_ws
字符串截取函數:substr,substring
字符串截取函數:substr,substring
字符串轉大寫函數:upper,ucase
字符串轉小寫函數:lower,lcase
去空格函數:trim
左邊去空格函數:ltrim
右邊去空格函數:rtrim
正則表達式替換函數:regexp_replace
正則表達式解析函數:regexp_extract
URL解析函數:parse_url
json解析函數:get_json_object
空格字符串函數:space
重復字符串函數:repeat
首字符ascii函數:ascii
左補足函數:lpad
右補足函數:rpad
分割字符串函數: split
集合查找函數: find_in_set
Map類型構建: map
Struct類型構建: struct
array類型構建: array
array類型訪問: A[n]
map類型訪問: M[key]
struct類型訪問: S.x
Map類型長度函數: size(Map<K.V>)
array類型長度函數: size(Array<T>)
類型轉換函數
1、加法操作: +
語法: A + B
操作類型:所有數值類型
說明:返回A與B相加的結果。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。比如,int + int 一般結果為int類型,而int + double 一般結果為double類型
舉例:hive> select 1 + 9 from dual; 10
2、減法操作: -
語法: A – B
操作類型:所有數值類型
說明:返回A與B相減的結果。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。比如,int – int 一般結果為int類型,而int – double 一般結果為double類型
舉例:hive> select 10 – 5 from dual;5
3、乘法操作 : *
語法: A * B
操作類型:所有數值類型
說明:返回A與B相乘的結果。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。注意,如果A乘以B的結果超過默認結果類型的數值范圍,則需要通過cast將結果轉換成范圍更大的數值類型
舉例:hive> select 40 * 5 from dual;200
4、除法操作 : /
語法: A / B
操作類型:所有數值類型
說明:返回A除以B的結果。結果的數值類型為double
舉例:hive> select 40 / 5 from dual;8.0
注意: hive 中最高精度的數據類型是 double, 只精確到小數點后 16 位,在做除法運算的時候要 特別注意:
hive>select ceil(28.0/6.99999999999999) from dual limit 1; 4
hive>select ceil(28.0/6.99999999999999) from dual limit 1; 5
5、取余操作 : %
語法: A % B
操作類型:所有數值類型
說明:返回A除以B的余數。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。
舉例:hive> select 41 % 5 from dual; 1
hive> select 8.4 % 4 from dual; 0.40000000000000036
注意:精度在 hive 中是個很大的問題,類似這樣的操作最好通過round 指定精度
hive> select round(8.4 % 4 , 2) from dual;0.4
6、位與操作 : &
語法: A & B
操作類型:所有數值類型
說明:返回A和B按位進行與操作的結果。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。
舉例:hive> select 4 & 8 from dual;0
hive> select 6 & 4 from dual;4
7、位或操作 : |
語法: A | B
操作類型:所有數值類型
說明:返回A和B按位進行或操作的結果。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。
舉例:hive> select 4 | 8 from dual; 12
hive> select 6 | 8 from dual; 14
8、位異或操作 : ^
語法: A ^ B
操作類型:所有數值類型
說明:返回A和B按位進行異或操作的結果。結果的數值類型等于A的類型和B的類型的最小父類型(詳見數據類型的繼承關系)。
舉例:hive> select 4 ^ 8 from dual; 12
hive> select 6 ^ 4 from dual; 2
9、位取反操作 : ~
語法: ~A
操作類型:所有數值類型
說明:返回A按位取反操作的結果。結果的數值類型等于A的類型。
舉例:hive> select ~6 from dual; -7
hive> select ~4 from dual; -5
10、邏輯與操作 : AND
語法: A AND B
操作類型:boolean
說明:如果A和B均為TRUE,則為TRUE;否則為FALSE。如果A為NULL或B為NULL,則為NULL
舉例:hive> select 1 from dual where 1=1 and 2=2; 1
11、邏輯或操作 : OR
語法: A OR B
操作類型:boolean
說明:如果A為TRUE,或者B為TRUE,或者A和B均為TRUE,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where 1=2 or 2=2; 1
12、邏輯非操作 : NOT
語法: NOT A
操作類型:boolean
說明:如果A為FALSE,或者A為NULL,則為TRUE;否則為FALSE
舉例:hive> select 1 from dual where not 1=2;
13、取整函數 : round
語法: round(double a)
返回值: BIGINT
說明: 返回double類型的整數值部分 (遵循四舍五入)
舉例:hive> select round(3.1415926) from dual; 3
hive> select round(3.5) from dual; 4
hive> create table dual as select round(9542.158) fromdual;
hive> describe dual; _c0 bigint
14、指定精度取整函數 : round
語法: round(double a, int d)
返回值: DOUBLE
說明: 返回指定精度d的double類型
舉例: hive> selectround(3.1415926,4) from dual; 3.1416
15、向下取整函數 : floor
語法: floor(double a)
返回值: BIGINT
說明: 返回等于或者小于該double變量的最大的整數
舉例:hive> select floor(3.1415926) from dual; 3
hive> select floor(25) from dual; 25
16、向上取整函數 : ceil
語法: ceil(double a)
返回值: BIGINT
說明: 返回等于或者大于該double變量的最小的整數
舉例:hive> select ceil(3.1415926) from dual; 4
hive> select ceil(46) from dual; 46
17、向上取整函數 : ceiling
語法: ceiling(double a)
返回值: BIGINT
說明: 與ceil功能相同
舉例:hive> select ceiling(3.1415926) from dual; 4
hive> select ceiling(46) from dual; 46
18、取隨機數函數 : rand
語法: rand(),rand(int seed)
返回值: double
說明: 返回一個0到1范圍內的隨機數。如果指定種子seed,則會等到一個穩定的隨機數序列
舉例:hive> select rand() from dual; 0.5577432776034763
19、自然指數函數 : exp
語法: exp(double a)
返回值: double
說明: 返回自然對數e的a次方
舉例:hive> select exp(2) from dual; 7.38905609893065
20、自然對數函數: ln
語法: ln(double a)
返回值: double
說明: 返回a的自然對數
21、以 10 為底對數函數 :log10
語法: log10(double a)
返回值: double
說明: 返回以10為底的a的對數
舉例:hive> select log10(100) from dual;2.0
22、以 2 為底對數函數 :log2
語法: log2(double a)
返回值: double
說明: 返回以2為底的a的對數
舉例:hive> select log2(8) from dual; 3.0
23、對數函數 : log
語法: log(double base, double a)
返回值: double
說明: 返回以base為底的a的對數
舉例:hive> select log(4,256) from dual; 4.0
24、冪運算函數 : pow
語法: pow(double a, double p)
返回值: double
說明: 返回a的p次冪
舉例:hive> select pow(2,4) from dual; 16.0
25、開平方函數 : sqrt
語法: sqrt(double a)
返回值: double
說明: 返回a的平方根
舉例:hive> select sqrt(16) from dual; 4.0
26、二進制函數 : bin
語法: bin(BIGINT a)
返回值: string
說明: 返回a的二進制代碼表示
舉例:hive> select bin(7) from dual; 111
27、十六進制函數 : hex
語法: hex(BIGINT a)
返回值: string
說明: 如果變量是int類型,那么返回a的十六進制表示;如果變量是string類型,則返回該字符串的十六進制表示
舉例:hive> select hex(17) from dual; 11
hive> select hex(‘abc’) from dual; 616263
28、反轉十六進制函數 : unhex
語法: unhex(string a)
返回值: string
說明: 返回該十六進制字符串所代碼的字符串
舉例: hive> selectunhex(‘616263’) from dual; abc
hive> select unhex(‘11’) from dual; -
hive> select unhex(616263) from dual; abc
29、進制轉換函數 : conv
語法: conv(BIGINT num, int from_base, int to_base)
返回值: string
說明: 將數值num從from_base進制轉化到to_base進制
舉例:hive> select conv(17,10,16) from dual; 11
hive> select conv(17,10,2) from dual; 10001
30、絕對值函數 : abs
語法: abs(double a) abs(int a)
返回值: double int
說明: 返回數值a的絕對值
舉例:hive> select abs(-3.9) from dual; 3.9
hive> select abs(10.9) from dual; 10.9
31、正取余函數 : pmod
語法: pmod(int a, int b),pmod(double a, double b)
返回值: int double
說明: 返回正的a除以b的余數
舉例:hive> select pmod(9,4) from dual; 1
hive> select pmod(-9,4) from dual; 3
32、正弦函數 : sin
語法: sin(double a)
返回值: double
說明: 返回a的正弦值
舉例:hive> select sin(0.8) from dual; 0.7173560908995228
33、反正弦函數 : asin
語法: asin(double a)
返回值: double
說明: 返回a的反正弦值
舉例:hive> select asin(0.7173560908995228) from dual; 0.8
34、余弦函數 : cos
語法: cos(double a)
返回值: double
說明: 返回a的余弦值
舉例:hive> select cos(0.9) from dual; 0.6216099682706644
35、反余弦函數 : acos
語法: acos(double a)
返回值: double
說明: 返回a的反余弦值
舉例:hive> select acos(0.6216099682706644) from dual; 0.9
36、positive 函數 : positive
語法: positive(int a), positive(double a)
返回值: int double
說明: 返回a
舉例: hive> selectpositive(-10) from dual; -10
hive> select positive(12) from dual; 12
37、negative 函數 : negative
語法: negative(int a), negative(double a)
返回值: int double
說明: 返回-a
舉例:hive> select negative(-5) from dual; 5
hive> select negative(8) from dual; -8
38、UNIX 時間戳轉日期函數 : from_unixtime
語法: from_unixtime(bigint unixtime[, string format])
返回值: string
說明: 轉化UNIX時間戳(從1970-01-01 00:00:00 UTC到指定時間的秒數)到當前時區的時間格式
舉例:hive> select from_unixtime(1323308943,'yyyyMMdd')from dual; 20111208
39、獲取當前 UNIX 時間戳函數 : unix_timestamp
語法: unix_timestamp()
返回值: bigint
說明: 獲得當前時區的UNIX時間戳
舉例:hive> select unix_timestamp() from dual; 1323309615
40、日期轉 UNIX 時間戳函數 : unix_timestamp
語法: unix_timestamp(string date)
返回值: bigint
說明: 轉換格式為"yyyy-MM-ddHH:mm:ss"的日期到UNIX時間戳。如果轉化失敗,則返回0。
舉例:hive> select unix_timestamp('2011-12-07 13:01:03')from dual; 1323234063
41、指定格式日期轉 UNIX 時間戳函數 :unix_timestamp
語法: unix_timestamp(string date, string pattern)
返回值: bigint
說明: 轉換pattern格式的日期到UNIX時間戳。如果轉化失敗,則返回0。
舉例:hive> select unix_timestamp('2011120713:01:03','yyyyMMdd HH:mm:ss') from dual; 1323234063
42、日期時間轉日期函數 : to_date
語法: to_date(string timestamp)
返回值: string
說明: 返回日期時間字段中的日期部分。
舉例:hive> select to_date('2011-12-08 10:03:01') fromdual;
43、日期轉年函數 : year
語法: year(string date)
返回值: int
說明: 返回日期中的年。
舉例:hive> select year('2011-12-08 10:03:01') fromdual;2011
hive> select year('2012-12-08') from dual; 2012
44、日期轉月函數 : month
語法: month (string date)
返回值: int
說明: 返回日期中的月份。
舉例:hive> select month('2011-12-08 10:03:01') fromdual;12
hive> select month('2011-08-08') from dual; 8
45、日期轉天函數 : day
語法: day (string date)
返回值: int
說明: 返回日期中的天。
舉例:hive> select day('2011-12-08 10:03:01') from dual; 8
hive> select day('2011-12-24') from dual; 24
46、日期轉小時函數 : hour
語法: hour (string date)
返回值: int
說明: 返回日期中的小時。
舉例:hive> select hour('2011-12-08 10:03:01') fromdual;10
47、日期轉分鐘函數 : minute
語法: minute (string date)
返回值: int
說明: 返回日期中的分鐘。
舉例:hive> select minute('2011-12-08 10:03:01') fromdual; 3
48、日期轉秒函數 : second
語法: second (string date)
返回值: int
說明: 返回日期中的秒。
舉例:hive> select second('2011-12-08 10:03:01') fromdual; 1
49、日期轉周函數 : weekofyear
語法: weekofyear (string date)
返回值: int
說明: 返回日期在當前的周數。
舉例:hive> select weekofyear('2011-12-08 10:03:01') fromdual;49
50、日期比較函數 : datediff
語法: datediff(string enddate, string startdate)
返回值: int
說明: 返回結束日期減去開始日期的天數。
舉例:hive> select datediff('2012-12-08','2012-05-09')from dual; 213
51、日期增加函數 : date_add
語法: date_add(string startdate, int days)
返回值: string
說明: 返回開始日期startdate增加days天后的日期。
舉例:hive> select date_add('2012-12-08',10) from dual;
52、日期減少函數 : date_sub
語法: date_sub (string startdate, int days)
返回值: string
說明: 返回開始日期startdate減少days天后的日期。
舉例:hive> select date_sub('2012-12-08',10) from dual;
53、If 函數 : if
語法: if(boolean testCondition, T valueTrue, TvalueFalseOrNull)
返回值: T
說明: 當條件testCondition為TRUE時,返回valueTrue;否則返回valueFalseOrNull
舉例:hive> select if(1=2,100,200) from dual; 200
hive> select if(1=1,100,200) from dual;100
54、非空查找函數 : COALESCE
語法: COALESCE(T v1, T v2, …)
返回值: T
說明: 返回參數中的第一個非空值;如果所有值都為NULL,那么返回NULL
舉例:hive> select COALESCE(null,'100','50′)from dual; 100
55、條件判斷函數: CASE
語法 : CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
返回值 : T
說明:如果 a 等于 b ,那么返回 c ;如果 a 等于 d ,那么返回 e ;否則返回 f
舉例:hive> Select case 100 when 50 then 'tom' when 100then 'mary' else 'tim' end from dual; mary
56、字符串長度函數: length
語法: length(string A)
返回值: int
說明:返回字符串A的長度
舉例:hive> select length('abcedfg') from dual; 7
57、字符串反轉函數: reverse
語法: reverse(string A)
返回值: string
說明:返回字符串A的反轉結果
舉例:hive> select reverse(abcedfg’) from dual; gfdecba
58、字符串連接函數: concat
語法: concat(string A, string B…)
返回值: string
說明:返回輸入字符串連接后的結果,支持任意個輸入字符串
舉例:hive> select concat(‘abc’,'def’,'gh’) from dual;
abcdefgh
59、帶分隔符字符串連接函數: concat_ws
語法: concat_ws(string SEP, string A, string B…)
返回值: string
說明:返回輸入字符串連接后的結果,SEP表示各個字符串間的分隔符
舉例:hive> select concat_ws(',','abc','def','gh') fromdual;
abc,def,gh
60、字符串截取函數: substr,substring
語法: substr(string A, int start),substring(string A, intstart)
返回值: string
說明:返回字符串A從start位置到結尾的字符串
舉例:hive> select substr('abcde',3) from dual; cde
hive> select substring('abcde',3) from dual; cde
hive> selectsubstr('abcde',-1) from dual; e
61、字符串截取函數: substr,substring
語法: substr(string A, int start, int len),substring(stringA, int start, int len)
返回值: string
說明:返回字符串A從start位置開始,長度為len的字符串
舉例:hive> select substr('abcde',3,2) from dual; cd
hive> select substring('abcde',3,2) from dual; cd
hive>select substring('abcde',-2,2) from dual; de
62、字符串轉大寫函數: upper,ucase
語法: upper(string A) ucase(string A)
返回值: string
說明:返回字符串A的大寫格式
舉例:hive> select upper('abSEd') from dual; ABSED
hive> select ucase('abSEd') from dual; ABSED
63、字符串轉小寫函數: lower,lcase
語法: lower(string A) lcase(string A)
返回值: string
說明:返回字符串A的小寫格式
舉例:hive> select lower('abSEd') from dual; absed
hive> select lcase('abSEd') from dual; absed
64、去空格函數: trim
語法: trim(string A)
返回值: string
說明:去除字符串兩邊的空格
舉例:hive> select trim(' abc ') from dual; abc
65、左邊去空格函數: ltrim
語法: ltrim(string A)
返回值: string
說明:去除字符串左邊的空格
舉例:hive> select ltrim(' abc ') from dual; abc
64、右邊去空格函數: rtrim
語法: rtrim(string A)
返回值: string
說明:去除字符串右邊的空格
舉例:hive> select rtrim(' abc ') from dual; abc
65、正則表達式替換函數: regexp_replace
語法: regexp_replace(string A, string B, string C)
返回值: string
說明:將字符串A中的符合java正則表達式B的部分替換為C。注意,在有些情況下要使用轉義字符,類似oracle中的regexp_replace函數。
舉例:hive> select regexp_replace('foobar', 'oo|ar', '')from dual; fb
66、正則表達式解析函數: regexp_extract
語法: regexp_extract(string subject, string pattern, intindex)
返回值: string
說明:將字符串subject按照pattern正則表達式的規則拆分,返回index指定的字符。
舉例:hive> select regexp_extract('foothebar','foo(.*?)(bar)', 1) from dual; the
hive> select regexp_extract('foothebar','foo(.*?)(bar)', 2) from dual; bar
hive> select regexp_extract('foothebar','foo(.*?)(bar)', 0) from dual; foothebar
注意,在有些情況下要使用轉義字符,下面的等號要用雙豎線轉 義,這是 java 正則表達式的規則。
select data_field,
regexp_extract(data_field,'.*?bgStart\\=([^&]+)',1)as aaa,
regexp_extract(data_field,'.*?contentLoaded_headStart\\=([^&]+)',1)as bbb,
regexp_extract(data_field,'.*?AppLoad2Req\\=([^&]+)',1)as ccc
from pt_nginx_loginlog_st
where pt = '2012-03-26' limit 2;
67、URL 解析函數: parse_url
語法: parse_url(string urlString, string partToExtract [,string keyToExtract])
返回值: string
說明:返回URL中指定的部分。partToExtract的有效值為:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
舉例:
hive>selectparse_url('http://facebook.com/path2/p.php?k1=v1&k2=v2#Ref1', 'HOST') fromdual; facebook.com
hive> selectparse_url('http://facebook.com/path2/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k1') from dual; v1
68、json 解析函數: get_json_object
語法: get_json_object(string json_string, string path)
返回值: string
說明:解析json的字符串json_string,返回path指定的內容。如果輸入的json字符串無效,那么返回NULL。
舉例:
hive> select get_json_object('{"store":
> {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}],
> "bicycle":{"price":19.95,"color":"red"}
> },
> "email":"amy@only_for_json_udf_test.net",
> "owner":"amy"
> }
> ','$.owner') from dual;
amy
69、空格字符串函數: space
語法: space(int n)
返回值: string
說明:返回長度為n的字符串
舉例:
hive> select space(10) from dual;
hive> select length(space(10)) from dual; 10
70、重復字符串函數: repeat
語法: repeat(string str, int n)
返回值: string
說明:返回重復n次后的str字符串
舉例:hive> select repeat('abc',5) from dual;abcabcabcabcabc
71、首字符 ascii 函數: ascii
語法: ascii(string str)
返回值: int
說明:返回字符串str第一個字符的ascii碼
舉例:hive> select ascii('abcde') from dual; 97
72、左補足函數: lpad
語法: lpad(string str, int len, string pad)
返回值: string
說明:將str進行用pad進行左補足到len位
舉例:hive> select lpad('abc',10,'td') from dual;tdtdtdtabc
注意:與 GP , ORACLE 不同, pad 不能默認
73、右補足函數: rpad
語法: rpad(string str, int len, string pad)
返回值: string
說明:將str進行用pad進行右補足到len位
舉例:hive> select rpad('abc',10,'td') from dual;abctdtdtdt
74、分割字符串函數 : split
語法: split(stringstr, string pat)
返回值: array
說明: 按照pat字符串分割str,會返回分割后的字符串數組
舉例:
hive> select split('abtcdtef','t') from dual;
["ab","cd","ef"]
75、集合查找函數 : find_in_set
語法: find_in_set(string str, string strList)
返回值: int
說明: 返回str在strlist第一次出現的位置,strlist是用逗號分割的字符串。如果沒有找該str字符,則返回0
舉例:hive> select find_in_set('ab','ef,ab,de') fromdual;2
hive> select find_in_set('at','ef,ab,de') from dual;0
76、集合統計函數
語法: count(*), count(expr), count(DISTINCT expr[, expr_.])
返回值: int
說明: count(*)統計檢索出的行的個數,包括NULL值的行;count(expr)返回指定字段的非空值的個數;count(DISTINCTexpr[, expr_.])返回指定字段的不同的非空值的個數
舉例:hive> select count(*) from dual; 20
hive> select count(distinct t) from dual; 10
77、總和統計函數 : sum
語法: sum(col), sum(DISTINCT col)
返回值: double
說明: sum(col)統計結果集中col的相加的結果;sum(DISTINCT col)統計結果中col不同值相加的結果
舉例:hive> select sum(t) from dual; 100
hive> select sum(distinct t) from dual; 70
78、平均值統計函數 : avg
語法: avg(col), avg(DISTINCT col)
返回值: double
說明: avg(col)統計結果集中col的平均值;avg(DISTINCT col)統計結果中col不同值相加的平均值
舉例:hive> select avg(t) from dual; 50
hive> select avg (distinct t) from dual; 30
79、最小值統計函數 : min
語法: min(col)
返回值: double
說明: 統計結果集中col字段的最小值
舉例:hive> select min(t) from dual; 20
80、最大值統計函數 : max
語法: maxcol)
返回值: double
說明: 統計結果集中col字段的最大值
舉例:hive> select max(t) from dual; 120
81、Map 類型構建 : map
語法: map (key1, value1, key2, value2, …)
說明:根據輸入的key和value對構建map類型
舉例:
hive> Create table alex_testas select map('100','tom','200','mary') as t from dual;
hive> describe alex_test;
t map<string,string>
hive> select t from alex_test;
{"100":"tom","200":"mary"}
82、Struct 類型構建 : struct
語法: struct(val1, val2, val3, …)
說明:根據輸入的參數構建結構體struct類型
舉例:
hive> create table alex_test as selectstruct('tom','mary','tim') as t from dual;
hive> describe alex_test;
t struct<col1:string,col2:string,col3:string>
hive> select t from alex_test;
{"col1":"tom","col2":"mary","col3":"tim"}
83、array 類型構建 : array
語法: array(val1, val2, …)
說明:根據輸入的參數構建數組array類型
舉例:
hive> create table alex_test as selectarray("tom","mary","tim") as t from dual;
hive> describe alex_test;
t array<string>
hive> select t from alex_test;
["tom","mary","tim"]
84、array 類型訪問 : A[n]
語法: A[n]
操作類型: A為array類型,n為int類型
說明:返回數組A中的第n個變量值。數組的起始下標為0。比如,A是個值為['foo','bar']的數組類型,那么A[0]將返回'foo',而A[1]將返回'bar'
舉例:
hive> create table alex_test as selectarray("tom","mary","tim") as t from dual;
hive> select t[0],t[1],t[2] from alex_test; tom mary tim
85、map 類型訪問 : M[key]
語法: M[key]
操作類型: M為map類型,key為map中的key值
說明:返回map類型M中,key值為指定值的value值。比如,M是值為{'f' -> 'foo', 'b' -> 'bar', 'all' -> 'foobar'}的map類型,那么M['all']將會返回'foobar'
舉例:
hive> Create table alex_test as selectmap('100','tom','200','mary') as t from dual;
hive> select t['200'],t['100'] from alex_test; mary tom
86、struct 類型訪問 : S.x
語法: S.x
操作類型: S為struct類型
說明:返回結構體S中的x字段。比如,對于結構體struct foobar {int foo, int bar},foobar.foo返回結構體中的foo字段
舉例:
hive> create table alex_test as selectstruct('tom','mary','tim') as t from dual;
hive> describe alex_test;
t struct<col1:string,col2:string,col3:string>
hive> select t.col1,t.col3from alex_test;
tom tim
87、Map 類型長度函數 :size(Map<K.V>)
語法: size(Map<K.V>)
返回值: int
說明: 返回map類型的長度
舉例:hive> select size(map('100','tom','101','mary'))from dual; 2
88、array 類型長度函數 :size(Array<T>)
語法: size(Array<T>)
返回值: int
說明: 返回array類型的長度
舉例:hive> select size(array('100','101','102','103'))from dual; 4
89、類型轉換函數
類型轉換函數: cast
語法: cast(expr as <type>)
返回值: Expected "=" to follow "type"
說明: 返回array類型的長度
舉例:hive> select cast(1 as bigint) from dual; 1
4 Hive JDBC
4.1 基本操作對象的介紹
1、Connection
說明:與Hive連接的Connection對象
Hive的連接
jdbc:hive://IP:10000/default“
獲取Connection的方法
DriverManager.getConnection("jdbc:hive://IP:10000/default","", "");2、Statement
說明: 用于執行語句
創建方法
Statementstmt = con.createStatement();
主要方法
executeQuery execute
3、ResultSet
說明:用來存儲結果集
創建方法
stmt.executeQuery
主要方法
getString()
4、特殊類型的處理
Array
Map
Struct
4.2 datafile寫操作
try {
Class.forName(driverName);
Connection con =DriverManager.getConnection("jdbc:hive://IP:10000/default","", "");
Statement stmt =con.createStatement();
String sql = "show tables";
// show tables
System.out.println("Running:" + sql);
ResultSet res =stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}4.3 基于Hive的數據庫連接池
使用DataSource作為數據源的實現
DBConnectionManager采用單例模式
提供獲得連接,關閉連接的方法
setupDataSource() DBConnectionManagergetInstance() close(Connectionconn) synchronizedConnection getConnection()
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





