溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹執行一句SQL的情況有哪些,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
零、數據庫驅動
MySQL 驅動在底層幫我們做了對數據庫的連接,只有建立了連接了,才能夠有后面的交互。
一、數據庫連接池
數據庫連接池有 Druid、C3P0、DBCP
采用連接池大大節省了不斷創建與銷毀線程的開銷,這就是有名的「池化」思想,不管是線程池還是 HTTP 連接池,都能看到它的身影
二、SQL 接口
MySQL 中處理請求的線程在獲取到請求以后獲取 SQL 語句去交給 SQL 接口去處理。
三、查詢解析器
將 SQL 接口傳遞過來的 SQL 語句進行解析,翻譯成 MySQL 自己能認識的語言。
四、MySQL 查詢優化器
MySQL 會依據成本最小原則來選擇使用對應的索引
成本 = IO 成本 + CPU 成本
IO成本 : 即從磁盤把數據加載到內存的成本,默認情況下,讀取數據頁的 IO 成本是 1,MySQL 是以頁的形式讀取數據的,即當用到某個數據時,并不會只讀取這個數據,而會把這個數據相鄰的數據也一起讀到內存中,這就是有名的程序局部性原理,所以 MySQL 每次會讀取一整頁,一頁的成本就是 1。所以 IO 的成本主要和頁的大小有關
CPU 成本:將數據讀入內存后,還要檢測數據是否滿足條件和排序等 CPU 操作的成本,顯然它與行數有關,默認情況下,檢測記錄的成本是 0.2。
MySQL 優化器 會計算 「IO 成本 + CPU」 成本最小的那個索引來執行
五、存儲引擎
查詢優化器會調用存儲引擎的接口,去執行 SQL,也就是說真正執行 SQL 的動作是在存儲引擎中完成的。
數據是被存放在內存或者是磁盤中的
每次在執行 SQL 的時候都會將其數據加載到內存中,這塊內存就是 InnoDB 中一個非常重要的組件:緩沖池 Buffer Pool
六、執行器
執行器最終最根據一系列的執行計劃去調用存儲引擎的接口去完成 SQL 的執行

七、Buffer Pool
Buffer Pool (緩沖池)是 InnoDB 存儲引擎中非常重要的內存結構,起到一個緩存的作用
Buffer Pool 就是我們第一次在查詢的時候會將查詢的結果存到 Buffer Pool 中,這樣后面再有請求的時候就會先從緩沖池中去查詢,如果沒有再去磁盤中查找,然后在放到 Buffer Pool 中
Buffer Pool中被使用的數據回被加鎖。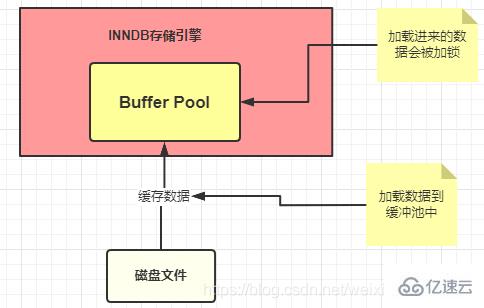
八、三個日志文件
1、undo 日志文件:記錄數據被修改前的樣子
作用:利用undo 日志文件完成事務回滾
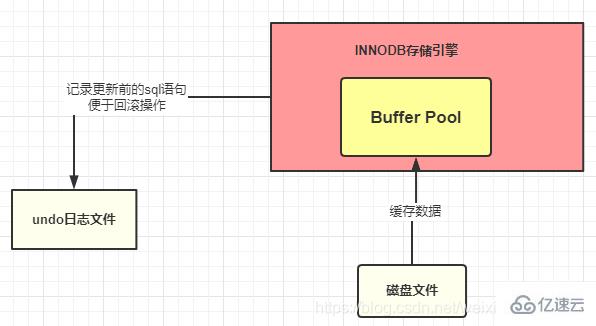
2、redo 日志文件:記錄數據被修改后的樣子
redo 記錄的是數據修改之后的值,不管事務是否提交都會記錄下來
MySQL 為了提高效率,所以將這些操作都先放在內存中去完成,更新后的數據會記錄在 redo log buffer 中,然后會在某個時機將其持久化到磁盤中。
3、bin log 日志文件: 記錄整個操作過程
| 性質 | redo Log | bin Log |
|---|---|---|
| 文件大小 | redo log 的大小是固定的(配置中也可以設置,一般默認的就足夠了) | bin log 可通過配置參數max_bin log_size設置每個bin log文件的大小(但是一般不建議修改)。 |
| 實現方式 | redo log是InnoDB引擎層實現的(也就是說是 Innodb 存儲引起過獨有的) | bin log是 MySQL 層實現的,所有引擎都可以使用 bin log日志 |
| 記錄方式 | redo log 采用循環寫的方式記錄,當寫到結尾時,會回到開頭循環寫日志。 | bin log 通過追加的方式記錄,當文件大小大于給定值后,后續的日志會記錄到新的文件上 |
| 使用場景 | redo log適用于崩潰恢復(crash-safe)(這一點其實非常類似與 Redis 的持久化特征) | bin log適用于主從復制和數據恢復 |
bin log 記錄的是整個操作記錄(這個對于主從復制具有非常重要的意義)
以上是“執行一句SQL的情況有哪些”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





