溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何在Python3中使用SQLAlchemy和Sqlite3,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Sqlite3是Python3標準庫不需要另外安裝,只需要安裝SQLAlchemy即可。本文sqlalchemy版本為1.2.12
pip install sqlalchemy

除了第一步創建引擎時連接URL不一樣,其他操作其他mysql等數據庫和sqlite都是差不多的。
sqlite創建數據庫連接就是創建數據庫,而其他mysql等應該是需要數據庫已存在才能創建數據庫連接;建立數據庫連接本文中有時會稱為建立數據庫引擎。
以相對路徑形式,在當前目錄下創建數據庫格式如下:
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine('sqlite:///foo.db')以絕對路徑形式創建數據庫,格式如下:
#Unix/Mac - 4 initial slashes in total
engine = create_engine('sqlite:////absolute/path/to/foo.db')
#Windows
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
#Windows alternative using raw string
engine = create_engine(r'sqlite:///C:\path\to\foo.db')sqlite可以創建內存數據庫(其他數據庫不可以),格式如下:
# format 1
engine = create_engine('sqlite://')
# format 2
engine = create_engine('sqlite:///:memory:', echo=True)PostgreSQL:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')
# OurSQL
engine = create_engine('mysql+oursql://scott:tiger@localhost/foo')engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')我們以在當前目錄下創建foo.db為例,后續各步同使用此數據庫。
在create_engine中我們多加了兩樣東西,一個是echo=Ture,一個是check_same_thread=False。
echo=Ture----echo默認為False,表示不打印執行的SQL語句等較詳細的執行信息,改為Ture表示讓其打印。
check_same_thread=False----sqlite默認建立的對象只能讓建立該對象的線程使用,而sqlalchemy是多線程的所以我們需要指定check_same_thread=False來讓建立的對象任意線程都可使用。否則不時就會報錯:sqlalchemy.exc.ProgrammingError: (sqlite3.ProgrammingError) SQLite objects created in a thread can only be used in that same thread. The object was created in thread id 35608 and this is thread id 34024. [SQL: 'SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name = ?\n LIMIT ? OFFSET ?'] [parameters: [{}]] (Background on this error at: http://sqlalche.me/e/f405)
from sqlalchemy import create_engine
engine = create_engine('sqlite:///foo.db?check_same_thread=False', echo=True)
先建立基本映射類,后邊真正的映射類都要繼承它
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()

然后創建真正的映射類,我們這里以一下User映射類為例,我們設置它映射到users表。
首先要明確,ORM中一般情況下表是不需要先存在的反而為了類與表對應無誤借助通過映射類來創建;當然表已戲存在了也無可以,在下一小結中你可以自己決定如果表存在時要如何操作是重新創建還是使用已有表,但使用已有表你需要確保和類的變量名與表的各字段名要對得上。
from sqlalchemy import Column, Integer, String
# 定義映射類User,其繼承上一步創建的Base
class User(Base):
# 指定本類映射到users表
__tablename__ = 'users'
# 如果有多個類指向同一張表,那么在后邊的類需要把extend_existing設為True,表示在已有列基礎上進行擴展
# 或者換句話說,sqlalchemy允許類是表的字集
# __table_args__ = {'extend_existing': True}
# 如果表在同一個數據庫服務(datebase)的不同數據庫中(schema),可使用schema參數進一步指定數據庫
# __table_args__ = {'schema': 'test_database'}
# 各變量名一定要與表的各字段名一樣,因為相同的名字是他們之間的唯一關聯關系
# 從語法上說,各變量類型和表的類型可以不完全一致,如表字段是String(64),但我就定義成String(32)
# 但為了避免造成不必要的錯誤,變量的類型和其對應的表的字段的類型還是要相一致
# sqlalchemy強制要求必須要有主鍵字段不然會報錯,如果要映射一張已存在且沒有主鍵的表,那么可行的做法是將所有字段都設為primary_key=True
# 不要看隨便將一個非主鍵字段設為primary_key,然后似乎就沒報錯就能使用了,sqlalchemy在接收到查詢結果后還會自己根據主鍵進行一次去重
# 指定id映射到id字段; id字段為整型,為主鍵,自動增長(其實整型主鍵默認就自動增長)
id = Column(Integer, primary_key=True, autoincrement=True)
# 指定name映射到name字段; name字段為字符串類形,
name = Column(String(20))
fullname = Column(String(32))
password = Column(String(32))
# __repr__方法用于輸出該類的對象被print()時輸出的字符串,如果不想寫可以不寫
def __repr__(self):
return "<User(name='%s', fullname='%s', password='%s')>" % (
self.name, self.fullname, self.password)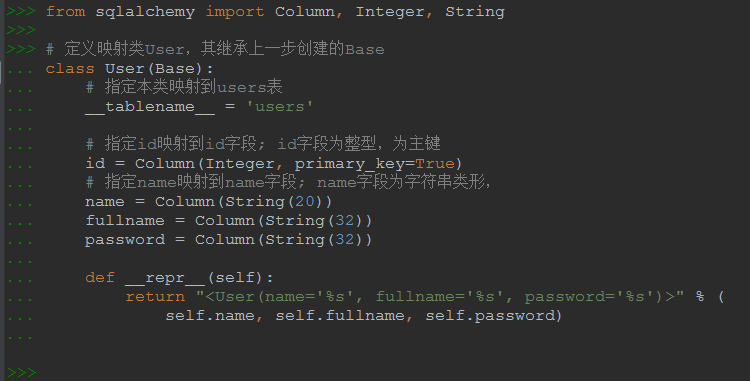
在上面的定義我__tablename__屬性是寫死的,但有時我們可能想通過外部給類傳遞表名,此時可以通過以下變通的方法來實現:
def get_dynamic_table_name_class(table_name):
# 定義一個內部類
class TestModel(Base):
# 給表名賦值
__tablename__ = table_name
__table_args__ = {'extend_existing': True}
username = Column(String(32), primary_key=True)
password = Column(String(32))
# 把動態設置表名的類返回去
return TestModel# 查看映射對應的表 User.__table__ # 創建數據表。一方面通過engine來連接數據庫,另一方面根據哪些類繼承了Base來決定創建哪些表 # checkfirst=True,表示創建表前先檢查該表是否存在,如同名表已存在則不再創建。其實默認就是True Base.metadata.create_all(engine, checkfirst=True) # 上邊的寫法會在engine對應的數據庫中創建所有繼承Base的類對應的表,但很多時候很多只是用來則試的或是其他庫的 # 此時可以通過tables參數指定方式,指示僅創建哪些表 # Base.metadata.create_all(engine,tables=[Base.metadata.tables['users']],checkfirst=True) # 在項目中由于model經常在別的文件定義,沒主動加載時上邊的寫法可能寫導致報錯,可使用下邊這種更明確的寫法 # User.__table__.create(engine, checkfirst=True) # 另外我們說這一步的作用是創建表,當我們已經確定表已經在數據庫中存在時,我完可以跳過這一步 # 針對已存放有關鍵數據的表,或大家共用的表,直接不寫這創建代碼更讓人心里踏實
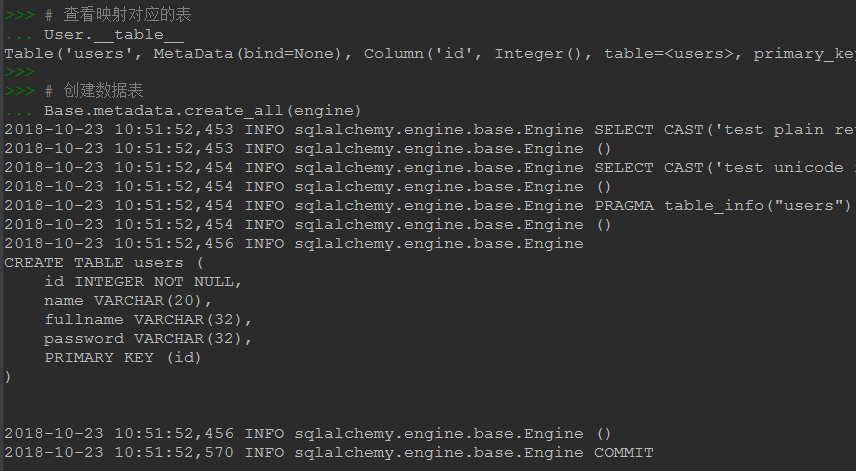
從上邊的討論可以知道,我們可以定義model然后根據model來創建數據表(當然也可以不創建),那可不可以反過來根據已有的表來自動生成model代碼呢,答案是可以的,使用sqlacodegen。
sqlacodegen安裝操作如下:
# 如果網絡通,直接pip安裝 pip install sqlacodegen # 如果網絡不通,先在網絡通的機器上使用pip下載sqlacodegen及期依賴包 pip download sqlacodegen # 上傳到真正要安裝的機器后再用pip安裝,依賴包也會自動安裝。版本可能會變化改成自己具體的包名 pip install sqlacodegen-2.1.0-py2.py3-none-any.whl
sqlacodegen生成model操作如下:
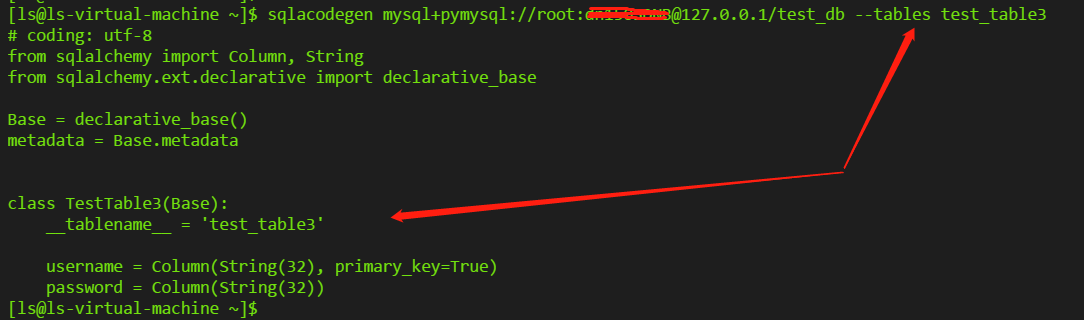
# linux應該被安裝在/usr/local/bin/sqlacodegen # mysql+pymysql示例 # 可使用--tables指定要生成model的表,不指定時為所有表都生成model # 可使用--outfile指定代碼輸出到的文件,不指定時輸出到stdout # 注意只有當表有主鍵時sqlacodegen才生成如下的class,不然會使用舊的生成Table()類實例的形式 # 更多說明可使用-h參看 sqlacodegen mysql+pymysql://user:password@localhost/dbname [--tables table_name1,table_name2] [--outfile model.py]
如我的一個示例操作如下,成功為指定表生成model:
增查改刪(CRUD)操作需要使用session進行操作
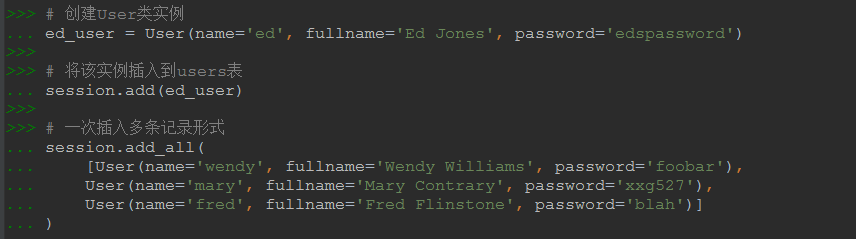
from sqlalchemy.orm import sessionmaker # engine是2.2中創建的連接 Session = sessionmaker(bind=engine) # 創建Session類實例 session = Session()

# 創建User類實例 ed_user = User(name='ed', fullname='Ed Jones', password='edspassword') # 將該實例插入到users表 session.add(ed_user) # 一次插入多條記錄形式 session.add_all( [User(name='wendy', fullname='Wendy Williams', password='foobar'), User(name='mary', fullname='Mary Contrary', password='xxg527'), User(name='fred', fullname='Fred Flinstone', password='blah')] ) # 當前更改只是在session中,需要使用commit確認更改才會寫入數據庫 session.commit()
query將轉成select xxx from xxx部分,filter/filter_by將轉成where部分,limit/order by/group by分別對應limit()/order_by()/group_by()方法。這句話非常的重要,理解后你將大量減少sql這么寫那在sqlalchemy該怎么寫的疑惑。
filter_by相當于where部分,外另可用filter。他們的區別是filter_by參數寫法類似sql形式,filter參數為python形式。
更多匹配寫法見:https://docs.sqlalchemy.org/en/13/orm/tutorial.html#common-filter-operators
our_user = session.query(User).filter_by(name='ed').first()
our_user
# 比較ed_user與查詢到的our_user是否為同一條記錄
ed_user is our_user
# 只獲取指定字段
# 但要注意如果只獲取部分字段,那么返回的就是元組而不是對象了
# session.query(User.name).filter_by(name='ed').all()
# like查詢
# session.query(User).filter(User.name.like("ed%")).all()
# 正則查詢
# session.query(User).filter(User.name.op("regexp")("^ed")).all()
# 統計數量
# session.query(User).filter(User.name.like("ed%")).count()
# 調用數據庫內置函數
# 以count()為例,都是直接func.func_name()這種格式,func_name與數據庫內的寫法保持一致
# from sqlalchemy import func
# session.query(func.count(User3.name)).one()
# 字段名為字符串形式
# column_name = "name"
# session.query(User).filter(User3.__table__.columns[column_name].like("ed%")).all()
# 獲取執行的sql語句
# 獲取記錄數的方法有all()/one()/first()等幾個方法,如果沒加這些方法,得到的只是一個將要執行的sql對象,并沒真正提交執行
# from sqlalchemy.dialects import mysql
# sql_obj = session.query(User).filter_by(name='ed')
# sql_command = sql_obj.statement.compile(dialect=mysql.dialect(), compile_kwargs={"literal_binds": True})
# sql_result = sql_obj.all()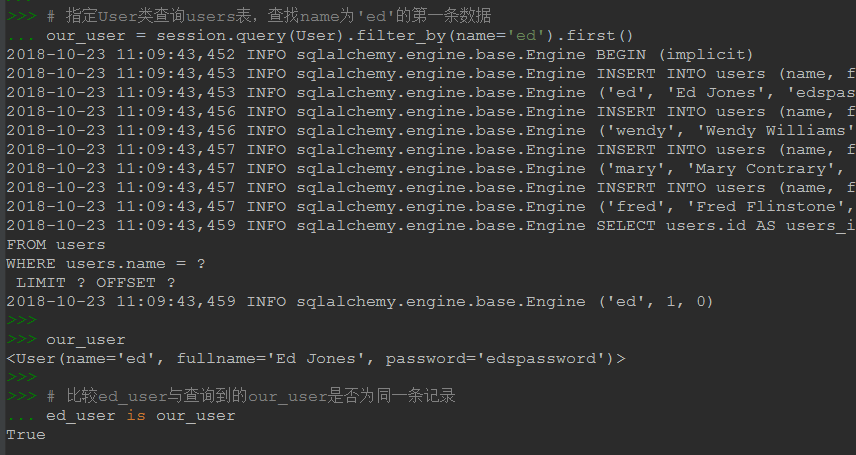
另外要注意該鏈接Common Filter Operators節中形如equals的query.filter(User.name == 'ed'),在真正使用時都得改成session.query(User).filter(User.name == 'ed')形式,不然只后看到報錯“NameError: name 'query' is not defined”。
我們上邊的sql直接是our_user = session.query(User).filter_by(name='ed').first()形式,但到實際中時User部分和name=‘ed'這部分是通過參數傳過來的,使用參數傳遞時就要注意以下兩個問題。
首先,是參數不要使用引號括起來。比如如下形式是錯誤的(使用引號),將報錯sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such column
table_and_column_name = "User" filter = "name='ed'" our_user = session.query(table_and_column_name).filter_by(filter).first()
其次,對于有等號參數需要變換形式。如下去掉了引號,對table_and_column_name沒問題,但filter = (name='ed')這種寫法在python是不允許的
table_and_column_name = User # 下面這條語句不符合語法 filter = (name='ed') our_user = session.query(table_and_column_name).filter_by(filter).first()
對參數中帶等號的這種形式,現在能想到的只有使用filter代替filter_by,即將sql語句中的=號轉變為python語句中的==。正確寫法如下:
table_and_column_name = User filter = (User.name=='ed') our_user = session.query(table_and_column_name).filter(filter).first()
# 要修改需要先將記錄查出來
mod_user = session.query(User).filter_by(name='ed').first()
# 將ed用戶的密碼修改為modify_paswd
mod_user.password = 'modify_passwd'
# 確認修改
session.commit()
# 但是上邊的操作,先查詢再修改相當于執行了兩條語句,和我們印象中的update不一致
# 可直接使用下邊的寫法,傳給服務端的就是update語句
# session.query(User).filter_by(name='ed').update({User.password: 'modify_passwd'})
# session.commit()
# 以同schema的一張表更新另一張表的寫法
# 在跨表的update/delete等函數中synchronize_session=False一定要有不然報錯
# session.query(User).filter_by(User.name=User1.name).update({User.password: User2.password}, synchronize_session=False)
# 以一schema的表更新另一schema的表的寫法
# 寫法與同一schema的一樣,只是定義model時需要使用__table_args__ = {'schema': 'test_database'}等形式指定表對應的schema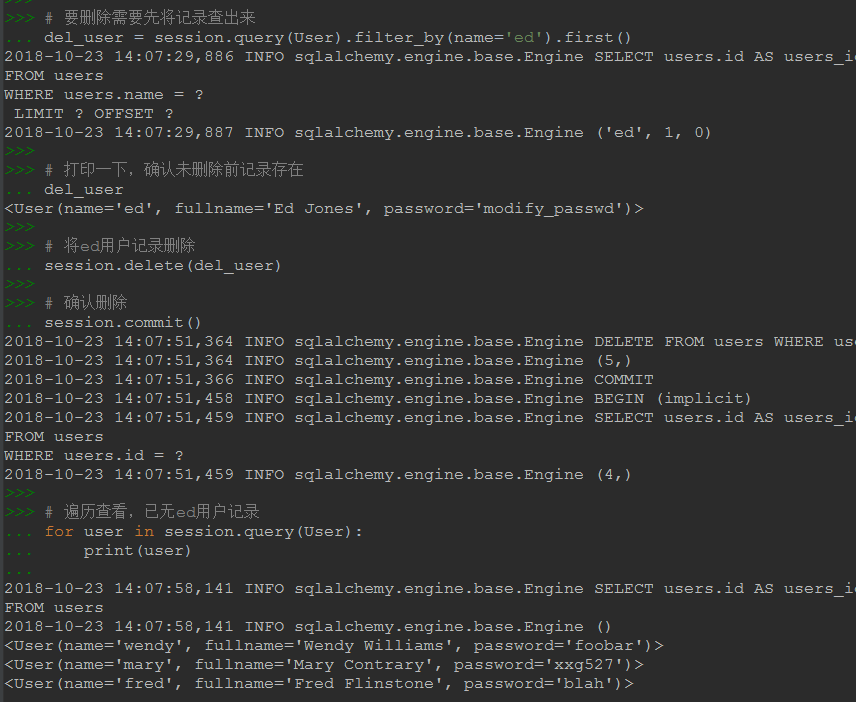
# 要刪除需要先將記錄查出來 del_user = session.query(User).filter_by(name='ed').first() # 打印一下,確認未刪除前記錄存在 del_user # 將ed用戶記錄刪除 session.delete(del_user) # 確認刪除 session.commit() # 遍歷查看,已無ed用戶記錄 for user in session.query(User): print(user) # 但上邊的寫法,先查詢再刪除,相當于給mysql服務端發了兩條語句,和我們印象中的delete語句不一致 # 可直接使用下邊的寫法,傳給服務端的就是delete語句 # session.query(User).filter_by(name='ed').first().delete()
雖然使用框架規定形式可以在一定程度上解決各數據庫的SQL差異,比如獲取前兩條記錄各數據庫形式如下。
# mssql/access select top 2 * from table_name; # mysql select * from table_name limit 2; # oracle select * from table_name where rownum <= 2;
但框架存消除各數據庫SQL差異的同時會引入各框架CRUD的差異,而開發人員往往就有一定的SQL基礎,如果一個框架強制用戶只能使用其規定的CRUD形式那反而增加用戶的學習成本,這個框架注定不能成為成功的框架。直接地執行SQL而不是使用框架設定的CRUD雖然不是一種被鼓勵的操作但也不應被視為一種見不得人的行為。
# 正常的SQL語句 sql = "select * from users" # sqlalchemy使用execute方法直接執行SQL records = session.execute(sql)
上述內容就是如何在Python3中使用SQLAlchemy和Sqlite3,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





