溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何在C語言中避免數組越界,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
所謂的數組越界,簡單地講就是指數組下標變量的取值超過了初始定義時的大小,導致對數組元素的訪問出現在數組的范圍之外,這類錯誤也是 C 語言程序中最常見的錯誤之一。
在 C 語言中,數組必須是靜態的。換而言之,數組的大小必須在程序運行前就確定下來。由于 C 語言并不具有類似 Java 等語言中現有的靜態分析工具的功能,可以對程序中數組下標取值范圍進行嚴格檢查,一旦發現數組上溢或下溢,都會因拋出異常而終止程序。也就是說,C 語言并不檢驗數組邊界,數組的兩端都有可能越界,從而使其他變量的數據甚至程序代碼被破壞。
因此,數組下標的取值范圍只能預先推斷一個值來確定數組的維數,而檢驗數組的邊界是程序員的職責。
一般情況下,數組的越界錯誤主要包括兩種:數組下標取值越界與指向數組的指針的指向范圍越界。
數組下標取值越界主要是指訪問數組的時候,下標的取值不在已定義好的數組的取值范圍內,而訪問的是無法獲取的內存地址。例如,對于數組 int a[3],它的下標取值范圍是 [0,2](即 a[0]、a[1] 與 a[2])。如果我們的取值不在這個范圍內(如 a[3]),就會發生越界錯誤。示例代碼如下所示:
int a[3];
int i=0;
for(i=0;i<4;i++)
{
a[i] = i;
}
for(i=0;i<4;i++)
{
printf("a[%d]=%d\n",i,a[i]);
}很顯然,在上面的示例程序中,訪問 a[3] 是非法的,將會發生越界錯誤。因此,我們應該將上面的代碼修改成如下形式:
int a[3];
int i=0;
for(i=0;i<3;i++)
{
a[i] = i;
}
for(i=0;i<3;i++)
{
printf("a[%d]=%d\n",i,a[i]);
}指向數組的指針的指向范圍越界是指定義數組時會返回一個指向第一個變量的頭指針,對這個指針進行加減運算可以向前或向后移動這個指針,進而訪問數組中所有的變量。但在移動指針時,如果不注意移動的次數和位置,會使指針指向數組以外的位置,導致數組發生越界錯誤。下面的示例代碼就是移動指針時沒有考慮到移動的次數和數組的范圍,從而使程序訪問了數組以外的存儲單元。
int i;
int *p;
int a[5];
/*數組a的頭指針賦值給指針p*/
p=a;
for(i=0;i<10;i++)
{
/*指針p指向的變量*/
*p=i+10;
/*指針p下一個變量*/
p++;
}在上面的示例代碼中,for 循環會使指針 p 向后移動 10 次,并且每次向指針指向的單元賦值。但是,這里數組 a 的下標取值范圍是 [0,4](即 a[0]、a[1]、a[2]、a[3] 與 a[4])。因此,后 5 次的操作會對未知的內存區域賦值,而這種向內存未知區域賦值的操作會使系統發生錯誤。正確的操作應該是指針移動的次數與數組中的變量個數相同,如下面的代碼所示:
int i;
int *p;
int a[5];
/*數組a的頭指針賦值給指針p*/
p=a;
for(i=0;i<5;i++)
{
/*指針p指向的變量*/
*p=i+10;
/*指針p下一個變量*/
p++;
}為了加深大家對數組越界的了解,下面通過一段完整的數組越界示例來演示編程中數組越界將會導致哪些問題。
#define PASSWORD "123456"
int Test(char *str)
{
int flag;
char buffer[7];
flag=strcmp(str,PASSWORD);
strcpy(buffer,str);
return flag;
}
int main(void)
{
int flag=0;
char str[1024];
while(1)
{
printf("請輸入密碼: ");
scanf("%s",str);
flag = Test(str);
if(flag)
{
printf("密碼錯誤!\n");
}
else
{
printf("密碼正確!\n");
}
}
return 0;
}上面的示例代碼模擬了一個密碼驗證的例子,它將用戶輸入的密碼與宏定義中的密碼“123456”進行比較。很顯然,本示例中最大的設計漏洞就在于 Test() 函數中的 strcpy(buffer,str) 調用。
由于程序將用戶輸入的字符串原封不動地復制到 Test() 函數的數組 char buffer[7] 中。因此,當用戶的輸入大于 7 個字符的緩沖區尺寸時,就會發生數組越界錯誤,這也就是大家所謂的緩沖區溢出(Buffer overflow)漏洞。但是要注意,如果這個時候我們根據緩沖區溢出發生的具體情況填充緩沖區,不但可以避免程序崩潰,還會影響到程序的執行流程,甚至會讓程序去執行緩沖區里的代碼。示例運行結果為:
請輸入密碼:12345
密碼錯誤!
請輸入密碼:123456
密碼正確!
請輸入密碼:1234567
密碼正確!
請輸入密碼:aaaaaaa
密碼正確!
請輸入密碼:0123456
密碼錯誤!
請輸入密碼:
在示例代碼中,flag 變量實際上是一個標志變量,其值將決定著程序是進入“密碼錯誤”的流程(非 0)還是“密碼正確”的流程(0)。當我們輸入錯誤的字符串“1234567”或者“aaaaaaa”,程序也都會輸出“密碼正確”。但在輸入“0123456”的時候,程序卻輸出“密碼錯誤”,這究竟是為什么呢?
其實,原因很簡單。當調用 Test() 函數時,系統將會給它分配一片連續的內存空間,而變量 char buffer[7] 與 int flag 將會緊挨著進行存儲,用戶輸入的字符串將會被復制進 buffer[7] 中。如果這個時候,我們輸入的字符串數量超過 6 個(注意,有字符串截斷符也算一個),那么超出的部分將破壞掉與它緊鄰著的 flag 變量的內容。
當輸入的密碼不是宏定義的“123456”時,字符串比較將返回 1 或 -1。我們都知道,內存中的數據按照 4 字節(DWORD)逆序存儲,所以當 flag 為 1 時,在內存中存儲的是 0x01000000。如果我們輸入包含 7 個字符的錯誤密碼,如“aaaaaaa”,那么字符串截斷符 0x00 將寫入 flag 變量,這樣溢出數組的一個字節 0x00 將恰好把逆序存放的 flag 變量改為 0x00000000。在函數返回后,一旦 main 函數的 flag 為 0,就會輸出“密碼正確”。這樣,我們就用錯誤的密碼得到了正確密碼的運行效果。
而對于“0123456”,因為在進行字符串的大小比較時,它小于“123456”,flag的值是 -1,在內存中將按照補碼存放負數,所以實際存儲的不是 0x01000000 而是 0xffffffff。那么字符串截斷后符 0x00 淹沒后,變成 0x00ffffff,還是非 0,所以沒有進入正確分支。
其實,本示例只是用一個字節淹沒了鄰接變量,導致程序進入密碼正確的處理流程,使設計的驗證功能失效。
在 C 語言中,為了提高運行效率,給程序員更大的空間,為指針操作帶來更多的方便,C 語言內部本身不檢查數組下標表達式的取值是否在合法范圍內,也不檢查指向數組元素的指針是不是移出了數組的合法區域。因此,在編程中使用數組時就必須格外謹慎,在對數組進行讀寫操作時都應當進行相應的檢查,以免對數組的操作超過數組的邊界,從而發生緩沖區溢出漏洞。
要避免程序因數組越界所發生的錯誤,首先就需要從數組的邊界定義開始。盡量顯式地指定數組的邊界,即使它已經由初始化值列表隱式指定。示例代碼如下所示:
int a[]={1,2,3,4,5,6,7,8,9,10};很顯然,對于上面的數組 a[],雖然編譯器可以根據始化值列表來計算出數組的長度。但是,如果我們顯式地指定該數組的長度,例如:
int a[10]={1,2,3,4,5,6,7,8,9,10};它不僅使程序具有更好的可讀性,并且大多數編譯器在數組長度小于初始化值列表的長度時還會發生相應警告。
當然,也可以使用宏的形式來顯式指定數組的邊界(實際上,這也是最常用的指定方法),如下面的代碼所示:
#define MAX 10
…
int a[MAX]={1,2,3,4,5,6,7,8,9,10};除此之外,在 C99 標準中,還允許我們使用單個指示符為數組的兩段“分配”空間,如下面的代碼所示:
int a[MAX]={1,2,3,4,5,[MAX-5]=6,7,8,9,10};在上面的 a[MAX] 數組中,如果 MAX 大于 10,數組中間將用 0 值元素進行填充(填充的個數為 MAX-10,并從 a[5] 開始進行 0 值填充);如果 MAX 小于 10,“[MAX-5]”之前的 5 個元素(1,2,3,4,5)中將有幾個被“[MAX-5]”之后的 5 個元素(6,7,8,9,10)所覆蓋,示例代碼如下所示:
#define MAX 10
#define MAX1 15
#define MAX2 6
int main(void)
{
int a[MAX]={1,2,3,4,5,[MAX-5]=6,7,8,9,10};
int b[MAX1]={1,2,3,4,5,[MAX1-5]=6,7,8,9,10};
int c[MAX2]={1,2,3,4,5,[MAX2-5]=6,7,8,9,10};
int i=0;
int j=0;
int z=0;
printf("a[MAX]:\n");
for(i=0;i<MAX;i++)
{
printf("a[%d]=%d ",i,a[i]);
}
printf("\nb[MAX1]:\n");
for(j=0;j<MAX1;j++)
{
printf("b[%d]=%d ",j,b[j]);
}
printf("\nc[MAX2]:\n");
for(z=0;z<MAX2;z++)
{
printf("c[%d]=%d ",z,c[z]);
}
printf("\n");
return 0;
}運行結果為:
a[MAX]:
a[0]=1 a[1]=2 a[2]=3 a[3]=4 a[4]=5 a[5]=6 a[6]=7 a[7]=8 a[8]=9 a[9]=10
b[MAX1]:
b[0]=1 b[1]=2 b[2]=3 b[3]=4 b[4]=5 b[5]=0 b[6]=0 b[7]=0 b[8]=0 b[9]=0 b[10]=6 b[11]=7 b[12]=8 b[13]=9 b[14]=10
c[MAX2]:
c[0]=1 c[1]=6 c[2]=7 c[3]=8 c[4]=9 c[5]=10
要避免數組越界,除了上面所闡述的顯式指定數組的邊界之外,還可以在數組使用之前進行越界檢查,檢查數組的界限和字符串(也以數組的方式存放)的結束,以保證數組索引值位于合法的范圍之內。例如,在寫處理數組的函數時,一般應該有一個范圍參數;在處理字符串時總檢查是否遇到空字符‘\0'。
來看下面一段代碼示例:
#define ARRAY_NUM 10
int *TestArray(int num,int value)
{
int *arr=NULL;
arr=(int *)malloc(sizeof(int)*ARRAY_NUM);
if(arr!=NULL)
{
arr[num]=value;
}
else
{
/*處理arr==NULL*/
}
return arr;
}從上面的“int*TestArray(int num,int value)”函數中不難看出,其中存在著一個很明顯的問題,那就是無法保證 num 參數是否越界(即當 num>=ARRAY_NUM 的情況)。因此,應該對 num 參數進行越界檢查,示例代碼如下所示:
int *TestArray(int num,int value)
{
int *arr=NULL;
/*越界檢查(越上界)*/
if(num<ARRAY_NUM)
{
arr=(int *)malloc(sizeof(int)*ARRAY_NUM);
if(arr!=NULL)
{
arr[num]=value;
}
else
{
/*處理arr==NULL*/
}
}
return arr;
}這樣通過“if(num<ARRAY_NUM)”語句進行越界檢查,從而保證 num 參數沒有越過這個數組的上界。現在看起來,TestArray() 函數應該沒什么問題,也不會發生什么越界錯誤。
但是,如果仔細檢查,TestArray() 函數仍然還存在一個致命的問題,那就是沒有檢查數組的下界。由于這里的 num 參數類型是 int 類型,因此可能為負數。如果 num 參數所傳遞的值為負數,將導致在 arr 所引用的內存邊界之外進行寫入。
當然,你可以通過向“if(num<ARRAY_NUM)”語句里面再加一個條件進行測試,如下面的代碼所示:
if(num>=0&&num<ARRAY_NUM)
{
}但是,這樣的函數形式對調用者來說是不友好的(由于 int 類型的原因,對調用者來說仍然可以傳遞負數,至于在函數中怎么處理那是另外一件事情),因此,最佳的解決方案是將 num 參數聲明為 size_t 類型,從根本上防止它傳遞負數,示例代碼如下所示:
int *TestArray(size_t num,int value)
{
int *arr=NULL;
/*越界檢查(越上界)*/
if(num<ARRAY_NUM)
{
arr=(int *)malloc(sizeof(int)*ARRAY_NUM);
if(arr!=NULL)
{
arr[num]=value;
}
else
{
/*處理arr==NULL*/
}
}
return arr;
}在 C 語言中,sizeof 這個其貌不揚的家伙經常會讓無數程序員叫苦連連。同時,它也是各大公司爭相選用的面試必備題目。簡單地講,sizeof 是一個單目操作符,不是函數。其作用就是返回一個操作數所占的內存字節數。其中,操作數可以是一個表達式或括在括號內的類型名,操作數的存儲大小由操作數的類型來決定。例如,對于數組 int a[5],可以使用“sizeof(a)”來獲取數組的長度,使用“sizeof(a[0])”來獲取數組元素的長度。
但需要注意的是,sizeof 操作符不能用于函數類型、不完全類型(指具有未知存儲大小的數據類型,如未知存儲大小的數組類型、未知內容的結構或聯合類型、void 類型等)與位字段。例如,以下都是不正確形式:
/*若此時max定義為intmax();*/
sizeof(max)
/*若此時arr定義為char arr[MAX],且MAX未知*/
sizeof(arr)
/*不能夠用于void類型*/
sizeof(void)
/*不能夠用于位字段*/
struct S
{
unsigned int f1 : 1;
unsigned int f2 : 5;
unsigned int f3 : 12;
};
sizeof(S.f1);了解 sizeof 操作符之后,現在來看下面的示例代碼:
void Init(int arr[])
{
size_t i=0;
for(i=0;i<sizeof(arr)/sizeof(arr[0]);i++)
{
arr[i]=i;
}
}
int main(void)
{
int i=0;
int a[10];
Init(a);
for(i=0;i<10;i++)
{
printf("%d\n",a[i]);
}
return 0;
}從表面看,上面代碼的輸出結果應該是“0,1,2,3,4,5,6,7,8,9”,但實際結果卻出乎我們的意料,如圖 1 所示。
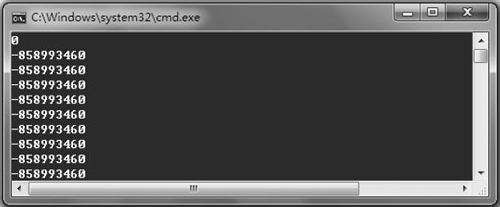
是什么原因導致這個結果呢?
很顯然,上面的示例代碼在“void Init(int arr[])”函數中接收了一個“int arr[]”類型的形參,并且在main函數中向它傳遞一個“a[10]”實參。同時,在 Init() 函數中通過“sizeof(arr)/sizeof(arr[0])”來確定這個數組元素的數量和初始化值。
在這里出現了一個很大問題:由于 arr 參數是一個形參,它是一個指針類型,其結果是“sizeof(arr)=sizeof(int*)”。在 IA-32 中,“sizeof(arr)/sizeof(arr[0])”的結果為 1。因此,最后的結果如圖 1 所示。
對于上面的示例代碼,我們可以通過傳入數組的長度的方式來解決這個問題,示例代碼如下:
void Init(int arr[],size_t arr_len)
{
size_t i=0;
for(i=0;i<arr_len;i++)
{
arr[i]=i;
}
}
int main(void)
{
int i=0;
int a[10];
Init(a,10);
for(i=0;i<10;i++)
{
printf("%d\n",a[i]);
}
return 0;
}除此之外,我們還可以通過指針的方式來解決上面的問題,示例代碼如下所示:
void Init(int (*arr)[10])
{
size_t i=0;
for(i=0;i< sizeof(*arr)/sizeof(int);i++)
{
(*arr)[i]=i;
}
}
int main(void)
{
int i=0;
int a[10];
Init(&a);
for(i=0;i<10;i++)
{
printf("%d\n",a[i]);
}
return 0;
}現在,Init() 函數中的 arr 參數是一個指向“arr[10]”類型的指針。需要特別注意的是,這里絕對不能夠使用“void Init(int(*arr)[])”來聲明函數,而是必須指明要傳入的數組的大小,否則“sizeof(*arr)”無法計算。但是在這種情況下,再通過 sizeof 來計算數組大小已經沒有意義了,因為此時數組大小已經指定為 10 了。
關于如何在C語言中避免數組越界就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





