溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下redis學習之NoSQL是什么意思,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
1、互聯網時代背景下大機遇,為什么用NoSQL
1.1單機MySQL的美好年代
在90年代,一個網站的訪問量一般都不大,用單個數據庫完全可以輕松應付。
在那個時候,更多的都是靜態網頁,動態交互類型的網站不多。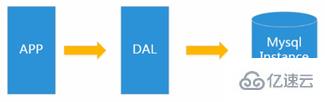
DAL dal是數據訪問層的英文縮寫,即為數據訪問層(Data Access Layer)
上述架構下,我們來看看數據存儲的瓶頸是什么?
1.數據量的總大小一個機器放不下時
2.數據的索引(B+ Tree)一個機器的內存放不下時
3.訪問量(讀寫混合)一個實例不能承受
如果滿足了上述1or3個,進化…
1.2.Memcached(緩存)+MySQL+垂直拆分
后來,隨著訪問量的上升,幾乎大部分使用MySQL架構的網站在數據庫上都開始出現了性能問題,web程序不再僅僅專注在功能上,同時也在追求性能。程序員們開始大量的使用緩存技術來緩解數據庫的壓力,優化數據庫的結構和索引。開始比較流行的是通過文件緩存來緩解數據庫壓力,但是當訪問量繼續增大的時候,多臺web機器通過文件緩存不能共享,大量的小文件緩存也帶了了比較高的IO壓力。在這個時候,Memcached就自然的成為一個非常時尚的技術產品。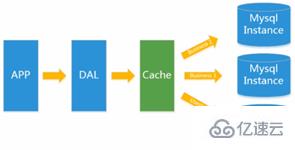
相當于之前dao層直接訪問數據庫,現在中間插入了一個cache層。頻繁的數據庫訪問造成了性能的降低,我們把其中的一些內容放入緩存中,減輕壓力。
1.3.Mysql主從讀寫分離
由于數據庫的寫入壓力增加,Memcached 只能緩解數據庫的讀取壓力。讀寫集中在一個數據庫上讓數據庫不堪重負,大部分網站開始使用主從復制技術來達到讀寫分離,以提高讀寫性能和讀庫的可擴展性。Mysql的master-slave模 式成為這個時候的網站標配了。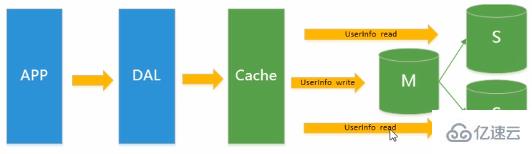
解釋:主庫有一條記錄更新,為了保證數據的完整性,需要復制到從庫中。讀寫分離:Master/slaver。我們可以將寫的操作放在主庫中,讀的操作放在從庫中。
1.4.分表分庫+水平拆分+mysql集群
在Memcached的高速緩存,MySQL的主從復制, 讀寫分離的基礎之上,這時MySQL主庫的寫壓力開始出現瓶頸,而數據量的持續猛增,由于MyISAM使用表鎖,在高并發下會出現嚴重的鎖問題,大量的高并發MySQL應用開始使用InnoDB引擎代替MyISAM。
同時,開始流行使用分表分庫來緩解寫壓力和數據增長的擴展問題。這個時候,分表分庫成了一個熱門技術,是面試的熱門問題也是業界討論的熱門技術問題。也就在這個時候,MySQL推出了還不太穩定的表分區,這也給技術實力一般的公司帶來了希望。雖然MySQL推出了MySQL Cluster集群,但性能也不能很好滿足互聯網的要求,只是在高可靠性上提供了非常大的保證。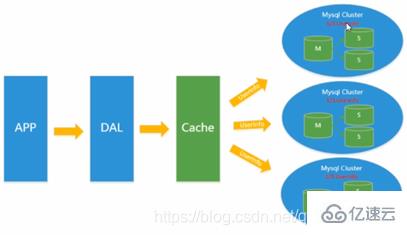
表鎖和行鎖?
分庫分表 1-3000進1號庫。3001-6000進2號庫。等等
1.5.MySQL的擴展性瓶頸
MySQL數據庫也經常存儲一些大文本字段,導致數據庫表非常的大,在做數據庫恢復的時候就導致非常的慢,不容易快速恢復數據庫。比如1000萬4KB大小的文本就接近40GB的大小, 如果能把這些數據從MySQL省去,MySQL將變得非常的小。關系數據庫很強大,但是它并不能很好的應付所有的應用場景。MySQL的擴展性差(需要復雜的技術來實現),大數據下IO壓力大,表結構更改困難,正是當前使用MySOL的開發人員面臨的問題。
1.6.今天是什么樣子? ?
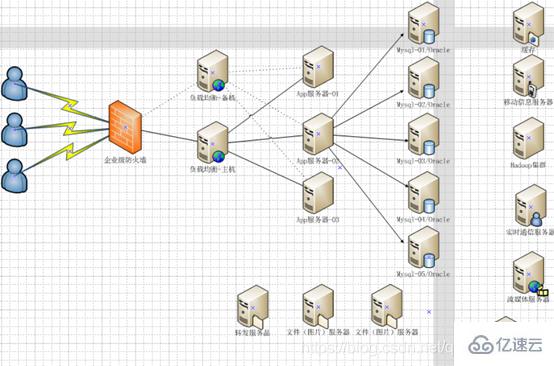
防火墻-nginx-Tomcat集群
1.7.為什么用NoSQL
今天我們可以通過第三方平臺( 如: Google,Facebook等) 可以很容易的訪問和抓取數據。用戶的個人信息,社交網絡,地理位置,用戶生成的數據和用戶操作日志已經成倍的增加。我們如果要對這些用戶數據進行挖掘,那SQL數據庫已經不適合這些應用了,NoSQL數據庫的發展也卻能很好的處理這些大的數據。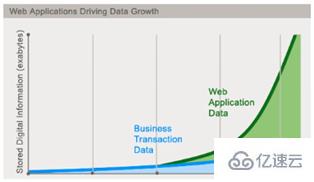
2.是什么
NoSQL(NoSQL = Not Only SQL),意即“不僅僅是SQL”,泛指非關系型的數據庫。隨著互聯網web2.0網站的興起,傳統的關系數據庫在應付web2.0網站,特別是超大規模和高并發的SNS類型的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關系型的數據庫則由于其本身的特點得到了非常迅速的發展。NoSQL 數據庫的產生就是為了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題,包括超大規模數據的存儲。
(例如谷歌或Facebook每天為他們的用戶收集萬億比特的數據)。這些類型的數據存儲不需要固定的模式,無需多余操作就可以橫向擴展。
3.能干嘛
易擴展
NoSQL數據庫種類繁多,但是一個共同的特點都是去掉關系數據庫的關系型特性。數據之間無關系,這樣就非常容易擴展。也無形之間,在架構的層面上帶來了可擴展的能力。
大數據量高性能
NoSQL數據庫都具有非常高的讀寫性能,尤其在大數據量下,同樣表現優秀。
這得益于它的無關系性,數據庫的結構簡單。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一種大粒度的Cache,在針對web2.0的交互頻繁的應用,Cache性能不高。
而NoSQL的Cache是記錄級的,是一種細粒度的Cache,所以NoSQL在這個層面上來說就要性能高很多了。
多樣靈活的數據模型
NoSQL無需事先為要存儲的數據建立字段,隨時可以存儲自定義的數據格式。
而在關系數據庫里,增刪字段是一件非常麻煩的事情。如果是非常大數據量的表,增加字段簡直就是一個噩夢。
傳統RDBMS VS NOSQL
RDBMS
高度組織化結構化數據
結構化查詢語言(SQL)
數據和關系都存儲在單獨的表中
數據操縱語言,數據定義語言
嚴格的一致性
基礎事務
NoSQL
代表著不僅僅是SQL
沒有聲明性查詢語言
沒有預定義的模式
鍵-值對存儲,列存儲,文檔存儲,圖形數據庫
最終一致性,而非ACID屬性
非結構化和不可預知的數據:
CAP定理
高性能,高可用性和可伸縮性
4.有哪些NoSQL
Redis(數據類型和高速緩存,各方面都比較優秀)
Memcached(高速緩存)
MongDB(最類似關系型數據庫)
5.怎么玩
KV
Cache
Persistence
談談你對Redis的理解,就說KV-CACHE-PERSISITENCE
3V + 3高
大數據時代的3V:
海量Volume
多樣Variety
實時Velocity
系統上出現一些問題的描述,淘寶雙十一海量的數據。一條微博,文字域,視頻域和背景域等等。多樣化。12306實時性要求高。做不到絕對的實時
互聯網需求的3高:
高并發
高可括
高性能
系統要支持高并發,如12306.四種方式獲得線程。
可擴展性,橫向和縱向。橫向,一臺機器不夠,再加機器。
性能要求高
看完了這篇文章,相信你對“redis學習之NoSQL是什么意思”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





