溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據庫出現如下的報錯
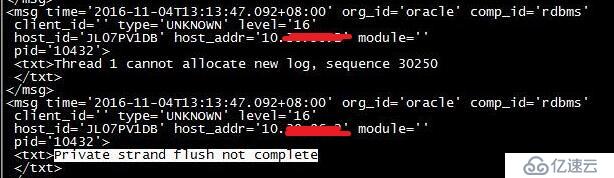
分析:
當數據庫切換日志時,所有private strand都必須刷新到當前日志,然后才能繼續。此信息表示我們在嘗試切換時,還沒有完全將所有 redo信息寫入到日志中。這有點類似于“checkpoint not complete”,不同的是,它僅涉及到正在被寫入日志的redo。在寫入所有redo前,無法切換日志。
Private Strands 是10gR2才有的,它用于處理redo的latch( redo allocation latch)。 是一種允許進程利用多個allocation latch更高效地將redo寫入redo buffer cache的機制,它與9i中出現的 log_parallelism 參數相關。提出Strand的概念是為了確保實例的redo生成率達到最佳,并能確保在出現某種redo爭用時,可以動態調整strand的數量進行補償。初始分配的strand數量取決于CPU的數量,最少兩個strand,其中一個strand用于active的redo生成。
對于大型的oltp系統,redo生成量非常大,因此當前臺進程遇到redo爭用時,這些strand會被激活。 shared strand總是與多個private strand共存 。 Oracle 10g的redo(和undo)機制有一些重大變化,目的是為了減少爭用。 此機制不再實時記錄redo,而是先記錄在一個private area,并在commit時flush到redo log buffer中去 。 在這種新機制引入后,一旦用戶進程申請到private strand,redo不再保存到pga中,因此 不再需要redo copy latch這個過程 。
如果新事務申請不到private strand的redo allocation latch,則會繼續遵循舊的redo buffer機制,申請寫入shared strand中 。 對于這個新的機制,在進行redo被寫出到logfile時,LGWR需要將shared strand與private strand的內容寫出。當redo flush發生時,所有的public strands的 redo allocation latch需要被獲取,所有的public strands的redo copy latch需要被檢查,所有包含活動事務的private strands需要被持有。
其實,對于這個現象也可以忽略,除非 “cannot allocate new log”信息和“advanced to log sequence”信息之間有明顯的時間差。
如果想要在alert.log中避免出現Private strand flush not complete事件,那么可以通過增加參數db_writer_processes的值來實現,因為DBWn會觸發LGWR將redo寫入到logfile,如果有多個DBWn進程一起寫,可以加速redo buffer cache寫入redo logfile。
解決:
可以使用以下命令修改:
SQL> alter system set db_writer_processes=4 scope=spfile ; -- 該參數時靜態參數,必需重啟數據庫后生效
注意,DBWR進程數應該與邏輯CPU數相當。另外地,當oracle發現一個DB_WRITER_PROCESS不能完成工作時,也會自動增加其數量,前提是已經在初始化參數中設定過最大允許的值。
如果系統支持 AIO(disk_async_io=true) ,一般不用設置多dbwr 或io slaves。
如果在有多個cpu的情況下建議使用DB_WRITER_PROCESSES,因為這樣的情況下不用去模擬異步模式,但要注意進程數量不能大于cpu數量。而在只有一個cpu的情況下建議使用DBWR_IO_SLAVES來模擬異步模式,以便提高數據庫性能。
如果"cannot allocate new log" 與"advanced to log sequence"有明顯的時間間隔,應考慮增加db_writer_processes
mos文檔建議增加db_write_processes,通過增加db_write_processes來增加臟塊的寫出速率。個人認為和io的關系應該
最大.也有部分的bug會導致該提示拋出.增加redo group和增大redo file的size,從而減少log switch的次數,可能效果會更好一些.
還有出現這樣“cannot allocate new log”的信息
這是個比較常見的錯誤。通常來說是因為在日志被寫滿時會切換日志組,這個時候會觸發一次checkpoint,DBWR會把內存中的臟塊往數據文件中寫,只要沒寫結束就不會釋放這個日志組。如果歸檔模式被開啟的話,還會伴隨著ARCH寫歸檔的過程。如果redo log產生的過快,當CPK或歸檔還沒完成,LGWR已經把其余的日志組寫滿,又要往當前的日志組里面寫redolog的時候,這個時候就會發生沖突,數據庫就會被掛起。并且一直會往alert.log中寫類似上面的錯誤信息。
分析原因:
服務器有三個日志組g1、g2、g3.當g1寫完時,要往g2上寫,這時候g1要進行歸檔,還要進行checkpoint。然后另外兩個日志組繼續寫。當g2和g3都寫完之后,又要往g1上寫,但是問題來了,g1還沒有完成歸檔和checkpoint操作。所以這時就會報警。
解決方法:
多加幾個日志組,并且每個日志組空間大一點,這樣就可以延緩時間,會留給g1充分的時間來完成歸檔和checkpoint任務。就不會有報錯。
操作步驟:
首先查看下數據庫的日志組狀態
查看在線日志組:SQL> select * from v$log;
查看日志組中的成員:SQL> select * from v$logfile;
查看日志組的具體狀態:SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
------------------------------------------------
1 28825 52428800 1 INACTIVE
2 28826 52428800 1 ACTIVE
3 28827 52428800 1 CURRENT
CURRENT: 表示是當前的日志。
INACTIVE:臟數據已經寫入數據塊。該狀態可以drop。
ACTIVE: 臟數據還沒有寫入數據塊。
日志只有50M太小
擴充下日志組大小
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/pvdb/redo04.log')size 500M;
Database altered.
SQL> alter database add logfile group 5('/u01/app/oracle/oradata/pvdb/redo05.log') size 500M;
Database altered.
SQL> alter database add logfile group 6 ('/u01/app/oracle/oradata/pvdb/redo06.log')size 500M;
Database altered.
切換日志組
SQL> alter system switch logfile;
System altered.
SQL> alter system switch logfile;
System altered.
注意:alter system switch logfile 和alter system archive log current這兩個切換的區別。
alter system switch logfile 是不等待歸檔完成就switch logfile。如果database尚未開啟archive log mode。那用這個切換是毋庸置疑了。另外,也是對單實例database和RAC模式下當前實例執行日志切換。
而alter system archive log current則需要等待歸檔完成才switch logfile。會對其中所有實例執行日志切換。
整體上說來,在自動歸檔的庫里,兩個命令的所產生的結果幾乎一樣。有區別的是alter system archive log current所用的時間會比alter system switch logfile 的長。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





