溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關使用Java對線程池進行配置時需要注意的問題,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
如果線程池內正在運行的線程數已經達到了核心線程數,任務將會被放到 BlockingQueue 內。
如果 BlockingQueue 已滿,線程池將會嘗試將線程數擴充到最大線程池容量。
如果當前線程池內線程數量已經達到最大線程池容量,則會執行拒絕策略拒絕任務提交。
流程如圖:
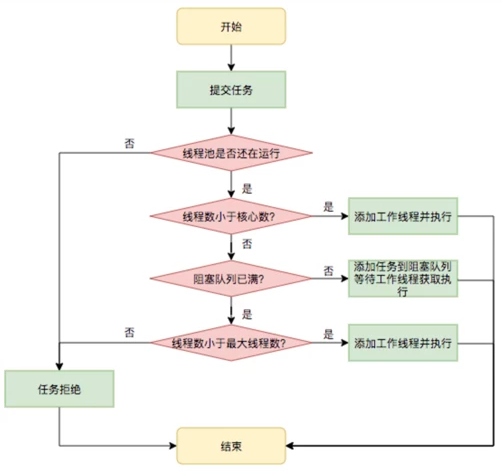
流程描述沒有問題,但如果某些點未經過推敲,容易導致誤解,而且描述中的情境太理想化,如果配置時不考慮運行時環境,也會出現一些非常詭異的問題。
轉載隨意,文章會持續修訂,請注明來源地址: https://zhenbianshu.github.io 。
線程池內線程數量小于等于 coreSize 的部分我稱為核心池,核心池是線程池的常駐部分,內部的線程一般不會被銷毀,我們提交的任務也應該絕大部分都由核心池內的線程來執行。
線程創建時機的誤解
有關核心池最常見的一個誤區是沒搞清楚核心池內線程的創建時機,這個問題,我覺得甩 10% 的鍋給 Doug Lea 大神應該不算過分,因為他在文檔里寫道 “If fewer than corePoolSize threads are running, try to start a new thread with the given command as its first task”,其中 "running" 這個詞就比較有歧義,因為在我們理解里 running 是指當前線程已被操作系統調度,擁有操作系統時間分片,或者被理解為正在執行某個任務。
基于以上的理解,我們很容易就認為如果任務的 QPS 非常低,線程池內線程數量永遠也達不到 coreSize。 即如果我們配置了 coreSize 為 1000,實際上 QPS 只有 1,單個任務耗時 1s,那么核心池大小就會一直是 1,即使有流量抖動,核心池也只會被擴容到 3。因為一個線程每秒執行執行一個任務,剛好不用創建新線程就足以應對 1QPS。
創建過程
但如果簡單設計一個測試,使用 jstack 打印出線程棧并數一下線程池內線程數量,會發現線程池內的線程數會隨著任務的提交而逐漸增大,直到達到 coreSize。
因為核心池的設計初衷是想它能作為常駐池,承載日常流量,所以它應該被盡快初始化,于是線程池的邏輯是在沒有達到 coreSize 之前,每一個任務都會創建一個新的線程,對應的源碼為:
public void execute(Runnable command) {
...
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { // workerCountOf() 方法是獲取線程池內線程數量
if (addWorker(command, true))
return;
c = ctl.get();
}
...
}而文檔里的 running 狀態也指的是線程已經被創建,我們也知道線程被創建后,會在一個 while 循環里嘗試從 BlockingQueue 里獲取并執行任務,說它正在 running 也不為過。
基于此,我們對一些高并發服務進行的預熱,其實并不是期望 JVM 能對熱點代碼做 JIT 等優化,對線程池、連接池和本地緩存的預熱才是重點。
BlockingQueue 是線程池內的另一個重要組件,首先它是線程池”生產者-消費者”模型的中間媒介,另外它也可以為大量突發的流量做緩沖,但理解和配置它也經常會出錯。
運行模型
最常見的錯誤是不理解線程池的運行模型。首先要明確的一點是線程池并沒有準確的調度功能,即它無法感知有哪些線程是處于空閑狀態的,并把提交的任務派發給空閑線程。線程池采用的是”生產者-消費者”模式,除了觸發線程創建的任務(線程的 firstTask)不會入 BlockingQueue 外,其他任務都要進入到 BlockingQueue,等待線程池內的線程消費,而任務會被哪個線程消費到完全取決于操作系統的調度。
對應的生產者源碼如下:
public void execute(Runnable command) {
...
if (isRunning(c) && workQueue.offer(command)) { isRunning() 是判斷線程池處理戚狀態
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
...
}對應的消費者源碼如下:
private Runnable getTask() {
for (;;) {
...
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
...
}
}BlockingQueue 的緩沖作用
基于”生產者-消費者”模型,我們可能會認為如果配置了足夠的消費者,線程池就不會有任何問題。其實不然,我們還必須考慮并發量這一因素。
設想以下情況:有 1000 個任務要同時提交到線程池內并發執行,在線程池被初始化完成的情況下,它們都要被放到 BlockingQueue 內等待被消費,在極限情況下,消費線程一個任務也沒有執行完成,那么這 1000 個請求需要同時存在于 BlockingQueue 內,如果配置的 BlockingQueue Size 小于 1000,多余的請求就會被拒絕。
那么這種極限情況發生的概率有多大呢?答案是非常大,因為操作系統對 I/O 線程的調度優先級是非常高的,一般我們的任務都是由 I/O 的準備或完成(如 tomcat 受理了 http 請求)開始的,所以很有可能被調度到的都是 tomcat 線程,它們在一直往線程池內提交請求,而消費者線程卻調度不到,導致請求堆積。
我負責的服務就發生過這種請求被異常拒絕的情況,壓測時 QPS 2000,平均響應時間為 20ms,正常情況下,40 個線程就可以平衡生產速度,不會堆積。但在 BlockingQueue Size 為 50 時,即使線程池 coreSize 為 1000,還會出現請求被線程池拒絕的情況。
這種情況下,BlockingQueue 的重要的意義就是它是一個能長時間存儲任務的容器,能以很小的代價為線程池提供緩沖。根據上文可知,線程池能支持 BlockingQueue Size 個任務同時提交,我們把最大同時提交的任務個數,稱為并發量,配置線程池時,了解并發量異常重要。
我們常用 QPS 來衡量服務壓力,所以配置線程池參數時也經常參考這個值,但有時候 QPS 和并發量有時候相關性并沒有那么高,QPS 還要 搭配任務執行時間 來 推算 峰值并發量。
比如請求間隔嚴格相同的接口,平均 QPS 為 1000,它的并發量峰值是多少呢?我們并沒有辦法估算,因為如果任務執行時間為 1ms,那么它的并發量只有 1;而如果任務執行時間為 1s,那么并發量峰值為 1000。
可是知道了任務執行時間,就能算出并發量了嗎?也不能,因為如果請求的間隔不同,可能 1min 內的請求都在一秒內發過來,那這個并發量還要乘以 60,所以上面才說知道了 QPS 和任務執行時間,并發量也只能靠推算。
計算并發量,我一般的經驗值是 QPS*平均響應時間 ,再留上一倍的冗余,但如果業務重要的話,BlockingQueue Size 設置大一些也無妨(1000 或以上),畢竟每個任務占用的內存量很有限。
GC
除了上面提到的各種情況下,GC 也是一個很重要的影響因素。
我們都知道 GC 是 Stop the World 的,但這里的 World 指的是 JVM,而一個請求 I/O 的準備和完成是操作系統在進行的,JVM 停止了,但操作系統還是會正常受理請求,在 JVM 恢復后執行,所以 GC 是會堆積請求的。
上文中提到的并發量計算一定要考慮到 GC 時間內堆積的請求同時被受理的情況,堆積的請求數可以通過 QPS*GC時間 來簡單得出,還有一定要記得留出冗余。
業務峰值
除此之外,配置線程池參數時,一定要考慮業務場景。
假如接口的流量大部分來自于一個定時程序,那么平均 QPS 就沒有了任何意義,線程池設計時就要考慮給 BlockingQueue 的 Size 設置一個大一些的值;而如果流量非常不平均,一天內只有某一小段時間才有高流量的話,而且線程資源緊張的情況下,就要考慮給線程池的 maxSize 留下較大的冗余;在流量尖刺明顯而響應時間不那么敏感時,也可以設置較大的 BlockingQueue,允許任務進行一定程度的堆積。
當然除了經驗和計算外,對服務做定時的壓測無疑更能幫助掌握服務真實的情況。
關于使用Java對線程池進行配置時需要注意的問題就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





