溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Flume和Sqoop是Hadoop數據集成和收集系統,兩者的定位不一樣,下面根據個人的經驗與理解和大家做一個介紹:
Flume由cloudera開發出來,有兩大產品:Flume-og和Flume-ng,Flume-og的架構過于復雜,在尋問當中會有數據丟失,所以放棄了。現在我們使用的是Flume-ng,主要是日志采集,這個日志可以是TCP的系統的日志數據,可以是文件數據(就是通常我們在Intel服務器,通過其中的機構傳過來的接口,或者通過防火墻采集過來的日志),在HDFS上去存儲,可以和kafka進行集成,這就是Flume的功能。
Flume架構是分布式,可以根據需要進行擴展Flume的節點和數量。它的擴展有兩個含義:一個是橫向的,根據原數據源的個數、種類不同進行擴展;第二個就是縱向的,可以增加更多的匯聚層,去做更多的過程的數據處理,而不是數據加載進來之后再進行轉換。
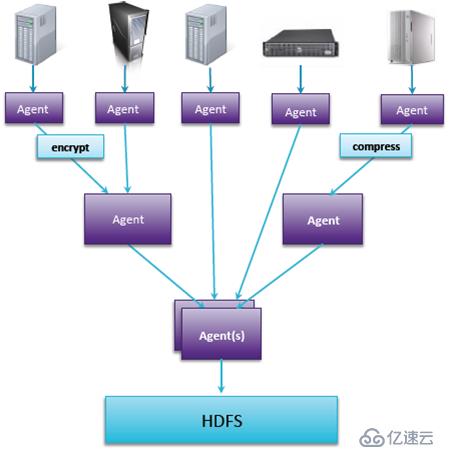
Flume的性能高可靠并且高可用的,可靠性主要體現在兩個方面:一方面就是有一份數據比較重要,為了保證數據傳輸的可靠性,可以兩個agent指向這份數據,而且兩個agent可以進行示范切換,如果其中一個失敗,另一個還可以進行傳輸。另一方面就是在agent的內部可以做緩存通透區,接收到數據可以存到磁盤,放到數據庫,縱使agent出問題,數據依然存在。
Flume是做日志采集的,但是更多的數據是從結構化數據庫過來的,這時我們就需要Sqoop。Sqoop是關系型數據庫和HDFS之間的一個橋梁,可以實現數據在關系型數據庫與HDFS之間的一個傳送。那么我們什么時候將數據傳遞到HDFS呢?主要是把新增交易,新增賬戶加載過來,寫的時候除了hdfs,還可以寫hive,甚至可以直接去建表。而且可以在源數據庫設立是導整個數據庫,還是導某一個表,或者導特定的列,這都是常見的在數據倉庫中進行的ETL.
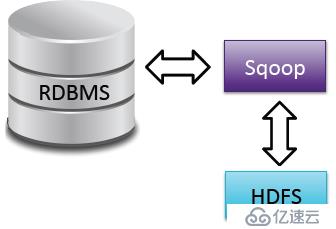
sqoop允許增量導入,增量有兩種,一種是直接追加(比如新增訂單、交易可以追加);另一種是狀態的改變,比如一個客戶之前是白名單客戶,還款很好,但是如果某個月逾期,加入黑名單,后期還款了又回到白名單,狀態在不停改變,那么就不能再和交易等一樣做追加,這個時候需要做的就是拉鏈。需要一個修改的日期,那么這個狀態有沒有修改,如果修改了,那么之前加載的怎么辦?可以通過sqoop進行配置,加載的時候讓它們在Hadoop里面進行更新。我們知道HDFS文件不能更新,這個時候進行文件合并,通過合并的方式把文本的數據清除。
數據什么時候導出呢?導出數據就在于Hadoop里面分析好的數據,我們可能需要下載一個數據集市,基于這個集市把數據導出來,所以sqoop也可以把數據導出。sqoop導出的機制是:默認的是mysql,mysql 效率較低,那么選擇第二種方式---直接模式,利用數據庫本身提供的一些導出工具。但是這些導出工具的效率還不夠高,更高的就是專業的定制的連接器,目前定制的連接器有MySQL、Postgres、Netezza、Teradata、Oracle。
以上就是根據自己的一些學習和工作經驗總結的關于Flume和Sqoop的相關知識,有些具體的知識這里沒有多涉及,如果想了解的可以自己去學習。我自己平常也會去關注“大數據cn”和“大數據時代學習中心”這些微信公眾號,里面分享的一些資訊和知識點對我有很大的幫助,推薦大家去看看,期望共同進步!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





