溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在日常開發或維護中經常會遇到大表的情況,所謂的大表是指存儲了百萬級乃至千萬級條記錄的表。這樣的表過于龐大,導致數據庫在查詢和插入的時候耗時太長,性能低下,如果涉及聯合查詢的情況,性能會更加糟糕。分表和表分區的目的就是減少數據庫的負擔,提高數據庫的效率,通常點來講就是提高表的增刪改查效率。
一、什么是分表:
分表是將一個大表按照一定的規則分解成多張具有獨立存儲空間的實體表,我們可以稱為子表,每個表都對應三個文件,MYD數據文件,.MYI索引文件,.frm表結構文件。這些子表可以分布在同一塊磁盤上,也可以在不同的機器上。
1、根據分表技術對海量數據的優化方式目前有2種方法:
1、垂直分割:把一個數據量很大的表,根據某個字段的屬性或使用頻繁程度分類拆分為多個表,或者把一個業務系統的庫分到不同的實例上。
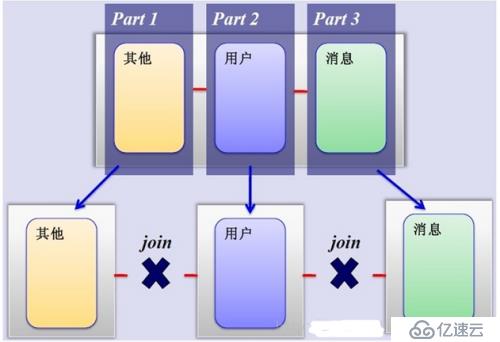
2、水平分割:根據一列或者多列的值把數據行放到多個獨立的表里,水平分表方式可以通過多個低配置主機整合起來,實現高性能。
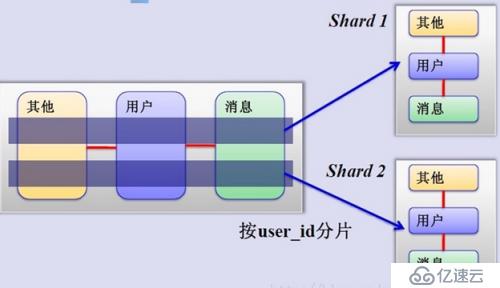
3、兩者的優缺點:
水平優點:拆分規則抽象好,JION操作基本可以數據庫做,不存在單表大數據、高并發的性能瓶頸,應用端改造較少,提高系統的穩定性和負載能力
缺點:分片事務一致性難以解決,在MyCAT2.0之前MySQL5.7之前,還是數據弱XA。數據多次擴展難度維護量大,夸庫JOIN性能差
垂直優點:拆分后業務清晰,拆分規則明確,系統之間整合或者拓展容易,數據庫維護簡單
缺點:部分業務無法使用JOIN,只能通過接口方式解決,提供系統能夠復雜度,受每種業務不同的限制存在性能瓶頸,不容易數據擴展跟性能提高。
事務處理復雜,垂直切分后按照業務的分類將表分散到不同的庫,會導致有些業務表過于龐大,存在單庫讀寫與存儲瓶頸。
二、什么是分區
分區就是把一張表的數據分成N多個區域,分區后,表面上還是一張表,但數據散列到多個位置根據數據量的大小,結合實際業務
1、分區方式有:
a、range分區:主要用于時間列分區、值范圍,行數據基于一個給定連續分區的列值放入分區。如銷售類的表,可以根據年來分區存放銷售記錄
b、list分區:面向離散的值,分區要指定的值,當插入指定的數據到指定分區表去,如指定某些值在特定分區里。
c、key分區:類似于按HASH分區,區別在于KEY分區只支持計算一列或多列,且MySQL服務器提供其自身的哈希函數。必須有一列或多列包含整數值。
d、hash分區:基于用戶定義的表達式的返回值來進行選擇的分區,該表達式使用將要插入到表中的這些行的列值進行計算。這個函數可以包含MySQL 中有效的、產生非負整數值的任何表達式。
三、分區實例:
創建redundant格式
如果表中存在主鍵或是唯一索引時,分區列必須是唯一索引的一個組成部分 唯一索引 create table t11( col1 int not null, col2 date not null, col3 int not null, col4 int not null, unique key (col1,col2)) partition by hash(col1) partitions 4; 哈希 create table t121( col1 int not null, col2 date not null, col3 int not null, col4 int not null, unique key (col1,col2)) partition by hash(year(col2)) partitions 4; 主鍵 create table t31( col1 int not null, col2 date not null, col3 int not null, col4 int not null, primary key (col1,col2)) partition by hash(col1) partitions 8; 主鍵和索引同時存在: create table t41( col1 int not null, col2 date not null, col3 int not null, col4 int not null, unique key(col4), primary key (col1)) partition by hash(col1) partitions 5; 唯一索引可以允許是null值,分區列只要是唯一索引的一個組成部分,不需要整個唯一索引列都是分區列 create table t223332( col1 int null, col2 date null, col3 int null, col4 int null) partition by hash(col3) partitions 4; 沒有主鍵或唯一索引,可以指定任何一個列為分區列 create table t223332( col1 int null, col2 date null, col3 int null, col4 int null, key(col4)) partition by hash(col3) partitions 4; rang 分區:主要用于時間列分區,如銷售類的表,可以根據年來分區存放銷售記錄 定義:行數據基于一個給定連續分區的列值放入分區, id 是主鍵 create table t3( id int)engine=innodb partition by range(id)( partition p0 values less than (10), partition p1 values less than (20) ); 查看數據文件 t3.frm t.par insert into t select 9; insert into t select 10; insert into t select 15; 查看分區狀態 use information_schema select * from PARITIONS where table_schema=''test and table_name='t3'\G; partition_method代表分區類型 當不滿足分區條件的時候報錯 table has no partition for value 40 alter table t add partition(partition p2 values less than maxalue); 主要用于時間列分區,如銷售類的表,可以根據年來分區存放銷售記錄(year(date))取年的時間 create table sales( money int not null,date datetime)engine=innodb partition by range (year(date))( partition p2008 values less than (2009), partition p2009 values less than (2010), partition p2010 values less than (2011) ); insert into sales select 100,'2008-01-01'; insert into sales select 100.'2008-02-01'; insert into sales select 100.'2008-01-02'; insert into sales select 100,'2009-03-01'; insert into sales select 100,'2010-01-01'; list 分區:面向離散的值,分區要指定的值,當插入指定的數據到指定分區表去, create table t_list (a int,b int)engine=innodb partition by list(b)(partition p0 values in(1,3,5,7,9), partition p1 values in (0,2,4,6,8)); insert into t4 select 1, 3; insert into t4 select 1, 5; insert into t4 select 1, 8; insert into t4 select 1, 6; table has no partition for values10 值得注意的是,LIST分區沒有類似如“VALUES LESS THAN MAXVALUE”這樣的包含其他值在內的定義。將要匹配的任何值都必須在值列表中找到。 LIST分區除了能和RANGE分區結合起來生成一個復合的子分區,與HASH和KEY分區結合起來生成復合的子分區也是可能的。 注意:innodb myisam區別 在用insert插入多行數據的過程中遇到分區為定義的值,myisam、innodb存儲引擎的處理完全不同, myisam 一條不成功,之前的成功值,會進入表中 innodb只要一條不成功,所有都不成功 create table t(a int,b int)engine=myisam partition by list(b)(partition p0 values in (1,3,5,7,9),partition p1 values in (0,2,4,6,8)); insert into t values (1,2),(2,4),(6,19),(5,3); insert into t values (1,2),(2,4),(6,19),(5,3); ERROR 1526 (HY000): Table has no partition for value 19 select * from t; +------+------+ | a | b | +------+------+ | 1 | 2 | | 2 | 4 | +------+------+ 2 rows in set (0.00 sec) create table tt(a int,b int)engine=innodb partition by list(b)(partition p0 values in (1,3,5,7,9),partition p1 values in (0,2,4,6,8)); insert into tt values (1,2),(2,4),(6,19),(5,3); insert into tt values (1,2),(2,4),(6,19),(5,3); ERROR 1526 (HY000): Table has no partition for value 19 select * from tt; Empty set (0.00 sec) hash 分區:根據用戶的表達式的返回值來進行分區,返回值不能是負數 要在create table 語句上添加一個partition by hash(expr)句子,其中expr是一個返回一個整數的表達式,它可以僅僅是數字段類型為mysql整型的列名字 后面在添加一個partitions num子句,num是一個非負數 create table t_hash(a int,b date)engine=innodb partition by hash(YEAR(b)) partitions 4; insert into t_hash select 1,'2010-04-01'; create table tt_hash(a int,b date)engine=innodb partition by hash (a) partitions 4; ####################################### columns分區 區別于其他分區,分區條件必須是整型,如果不是整型也應該需要通過函數將其轉化為整型 columns分時是rang list分區的進化 支持整型類型 日期類型date datetime其余的日期類型不予支持 字符串類型 char varcha binary varbinary ,blok和text類型的不予支持 create table tt_column_range(a int,b int)engine=innodb partition by range columns(a,b)( partition p0 values less than (0,10), partition p1 values less than (10,20), partition p2 values less than (20,30), partition p3 values less than (30,40), partition p4 values less than (40,50) ); 子分區:MYSQL數據庫允許在rang和list的分區上再進行hask或者key子分區, create table ts(a int,b date)engine=innodb partition by range(year(b)) subpartition by hash(to_days(b)) subpartitions 3( partition p0 values less than (2013), partition p0 values less than (2014), partition p1 values less than (2015) partition p2 values less than maxvalue); create table ts(a int,b date partition by range(year(b)) subpartition by hash(to_days(b))( partition p0 values less than(2014)( subpartition s0, subpartition s1) partition p1 values less than (2015)( subpartition s2, subpartition s3 ) partition p2 values less than maxvalue( subpartition s4 subpartition s5 ) ) 每個子分區必須包含分區的名字。 子分區的名字唯一的。 分區中null值 create table t3( id int)engine=innodb partition by range(id)( partition p0 values less than (10), partition p1 values less than (20); ); null值 放最左邊的。
總結:了解基礎的分表的原則、方法,實際還需要根據業務結合,達到業務架構最優。
如有不妥,歡迎指正!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





