溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
組函數:
– 類型和語法
– 使用 AVG, SUM, MIN, MAX, COUNT
– 組函數使用 DISTINCT 關鍵字
– 組函數中NULL 值
分組函數:作用于一組數據,并對一組數據返回一個值
組函數類型
AVG 平均值
COUNT 統計值
MAX 最大值
MIN 最小值
SUM 合計
STDDEV 標準差
VARIANCE 方差
組函數語法:
select group_function(column), ... from table [where condition] [order by column];
使用 AVG 和 和 SUM 函數
可以對數值型數據使用 AVG 和 SUM 函數
1、查詢job_id為REP的 平均工資,最高工資,工資總和
select avg(salary),max(salary),min(salary),sum(salary) from employees where job_id like '%REP%';

使用 MIN 和 和 MAX
可以對數值型、字符型和日期型使用 MIN 和 MAX 函數
2、查詢入職時最短和最長時間
select min(hire_date),max(hire_date) from employees;

使用 COUNT
1、統計一下department_id 為50的部門有多少人
select count(*) from employees where department_id =50;

2、如果有空值不會被計算進去
select count(commission_pct) from employees where department_id=80;

3、顯示 EMPLOYEES 表中不同的部門數
select count(distinct department_id) from employees;

組函數忽略空值
1、統計一下提成
select avg(commission_pct) from employees;

2、將所有的人都統計進來
select avg(nvl(commission_pct,0)) from employees;

分組數據:GROUP BY
可以使用GROUP BY 子句將表中的數據分成若干組.
group by 后面不能使用列別名,select 后面有限制.
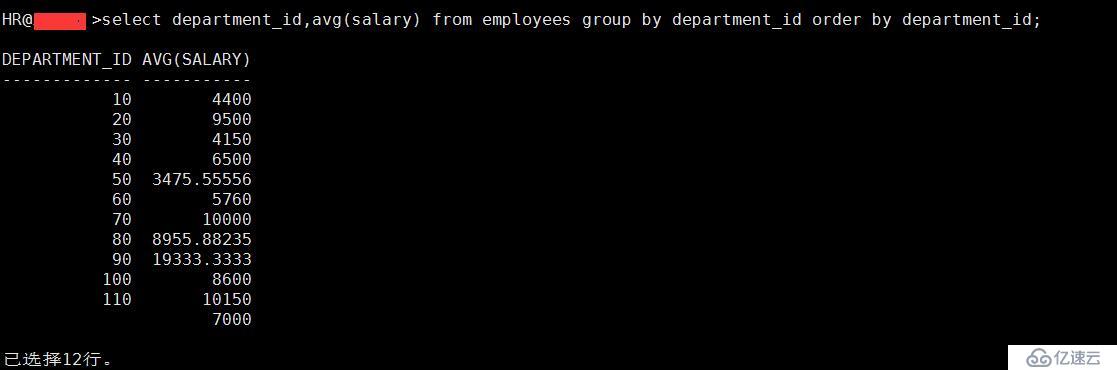
1、求出EMPLOYEES中各個部門的平均工資
select department_id,avg(salary) from employees group by department_id order by department_id;
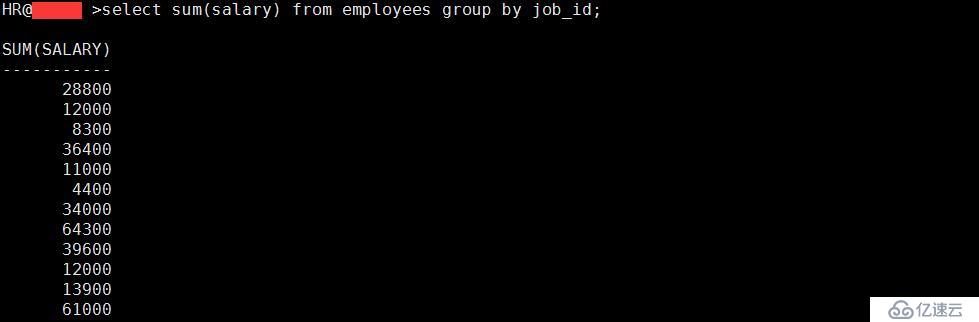
2、包含在 GROUP BY 子句中的列不必包含在SELECT 列表中。
select sum(salary) from employees group by job_id;
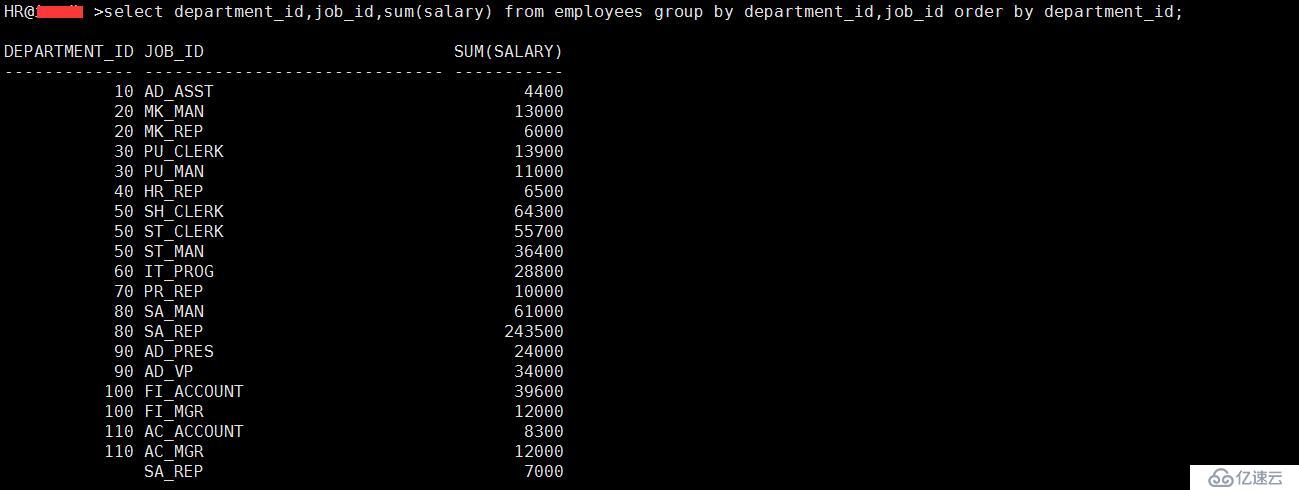
3、進行多組分列,按照部門和工作進行分組得到分組后工資的和
select department_id,job_id,sum(salary) from employees group by department_id,job_id order by department_id;
非法使用組函數
SELECT 列表中的列或表達式,未包含在組函數中的列,都必須包含于GROUP BY 子句中
錯誤:
select department_id, count(last_name) from employees;
或
select department_id, job_id, count(last_name) from employees group by department_id;
也就是說必須把department_id 和job_id 加入到group by 中
正確:
select department_id, count(last_name) from employees group by department_id;
或
select department_id, job_id, count(last_name) from employees group by department_id,job_id;
不能使用 WHERE 子句來過濾組
可以使用 HAVING 子句來過濾組
錯誤:
select department_id, avg(salary) from employees where avg(salary) > 8000 group by department_id;
過濾分組:HAVING 子句
使用 HAVING 子句過濾分組條件:
行已經被分組。
使用了組函數。
滿足HAVING 子句中條件的分組將被顯示
語法:
select column, group_function from table [where condition]
[group by group_by_expression]
[having group_condition]
[order by column];
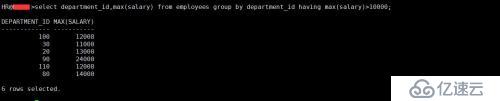
1、每個部門的最高薪水大于$10,000
select department_id,max(salary) from employees group by department_id having max(salary)>10000;
2.查找不是REP工作的工資總和大于13000的,并按照sum salary排序。
select job_id ,sum(salary) from employees where job_id not like '%REP%' group by job_id having sum(salary) > 13000
order by sum(salary);

嵌套組函數
按照部門分類顯示平均工資的最大值:
select max(avg(salary)) from employees group by department_id;

但是嵌套組函數好像不能在添加新的列了
練習題:
1、找出所有員工工資的最大值,最小值和以及平均值。并以此將各列的別名修改
為”Maximum”,”Minimum”,”Sum”,”Average”。并且要求將結果進行四舍五入。
select round(max(salary) ,0) "Maxinmum", round(min(salary),0) Minimum, round(sum(salary),0) Sum ,round(avg(salary),0) Average from employees;

2、以 job_id 進行分組,查看每個工種的工資的最大值,最小值,和,以及平均值
select job_id,max(salary),min(salary),sum(salary),avg(salary) from employees group by job_id;
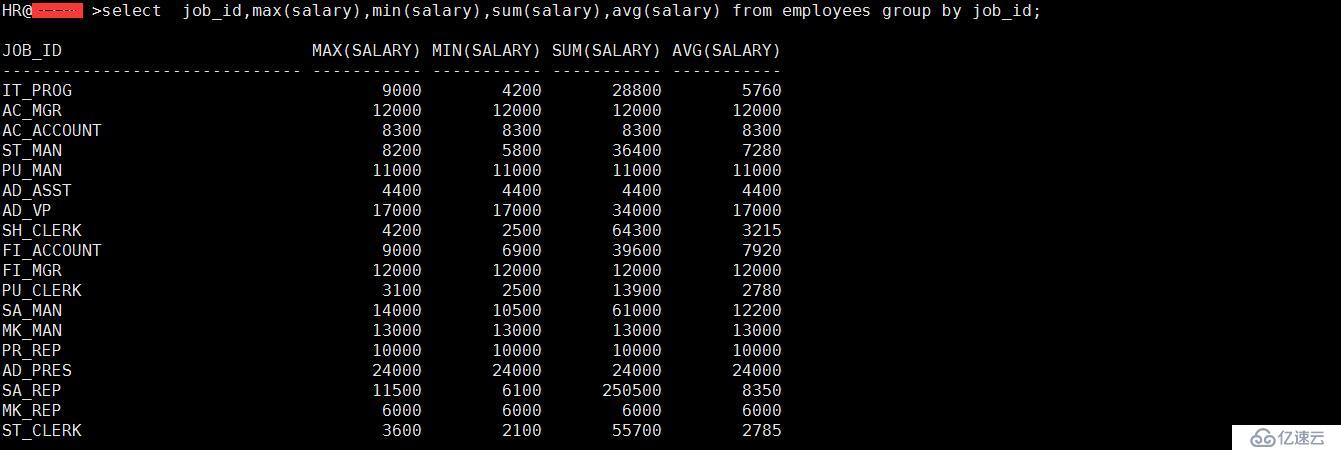
3、寫一個查詢語句,統計每一個工種的員工數
select job_id,count(employee_id)from employees group by job_id;
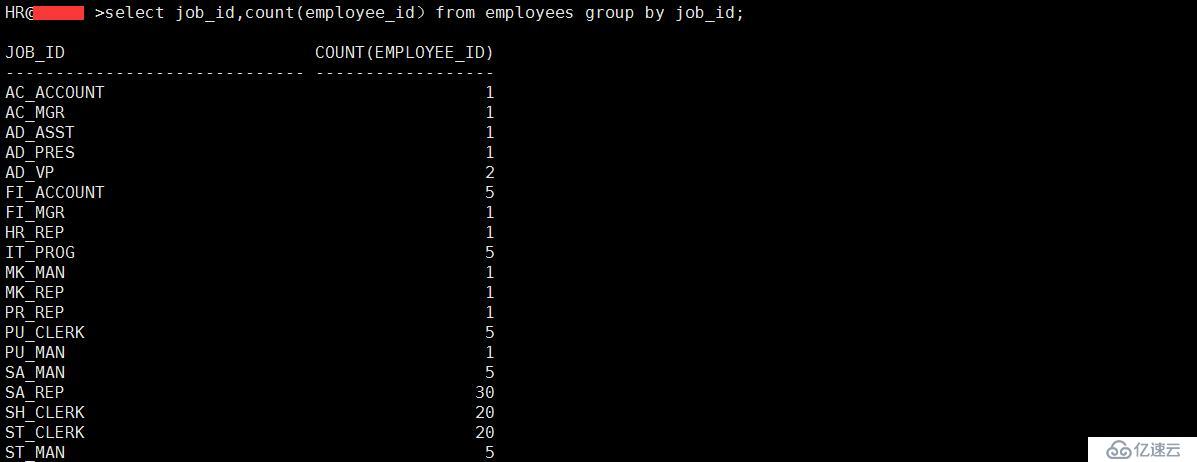
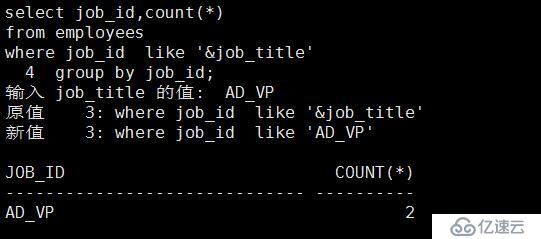
4、讓HR部門的同事可以輸入一個工種,然后 SQL 返回該工種的員工數量。
select job_id,count(*) from employees where job_id like '&job_title' group by job_id;
5、直接顯示出所有經理的總人數。并將該列標記為"Number of Managers".提示:使用 MANAGER_ID 這一列來確定經理的數量
select count(distinct manager_id) "Number of Managers" from employees;

6、查出薪水最高的和薪水最低的差值,并將該列標記為 DIFFERENCE
select max(salary) - min(salary) "DIFFERENCE" from employees;

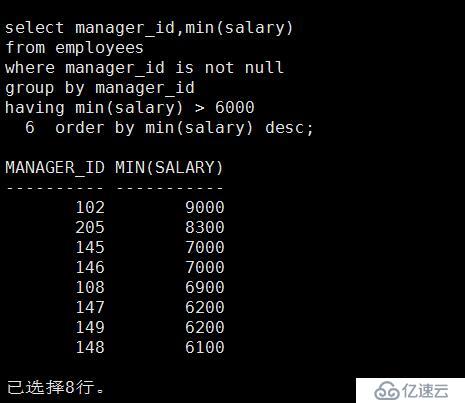
7、請查詢出每個經理手下工資最低的員工,那些沒有經理的員工需要排除,并且需要排除那些最低薪水
小于等于6000 組。最后將結構根據薪水以降序排列。
select manager_id,min(salary)
from employees
where manager_id is not null
group by manager_id
having min(salary) > 6000
order by min(salary) desc;
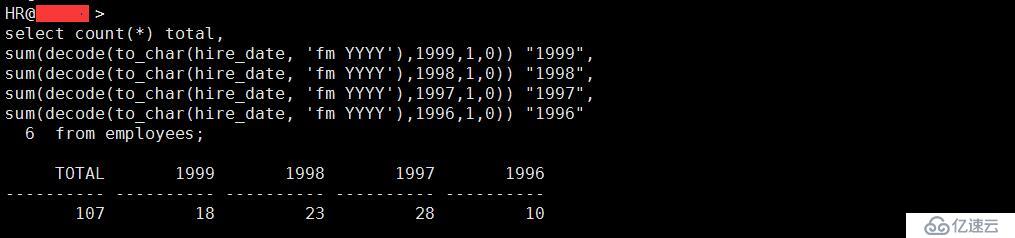
8、請編寫一條 SQL 語句,查看員工的總數,以及在 1996,1997,1998,1999 這幾年被雇傭的員工數量,并為各列取合適的別名。
select count(*) total,
sum(decode(to_char(hire_date, 'fm YYYY'),1999,1,0)) "1999",
sum(decode(to_char(hire_date, 'fm YYYY'),1998,1,0)) "1998",
sum(decode(to_char(hire_date, 'fm YYYY'),1997,1,0)) "1997",
sum(decode(to_char(hire_date, 'fm YYYY'),1996,1,0)) "1996"
from employees;
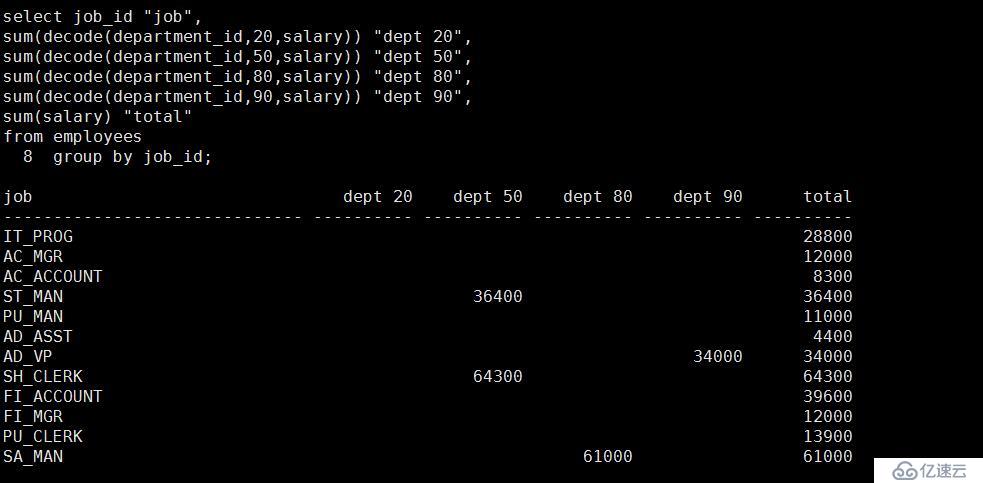
9、請通過一個矩陣顯示出所需要的結果,要求是根據部門編號(20,50,80,90)算出對應的工種的工
資,以及該工種的工資總和,對于部門號是 20,50,80,90 這幾列來說,請給出一個合適的別名。
select job_id "job",
sum(decode(department_id,20,salary)) "dept 20",
sum(decode(department_id,50,salary)) "dept 50",
sum(decode(department_id,80,salary)) "dept 80",
sum(decode(department_id,90,salary)) "dept 90",
sum(salary) "total"
from employees
group by job_id;
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





