溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“C/C++的性能如何優化”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“C/C++的性能如何優化”吧!
先敬上代碼:
#include <stdlib.h>
#define CACHE_LINE __attribute__((aligned(64)))
struct S1
{
int r1;
int r2;
int r3;
S1 ():r1 (1), r2 (2), r3 (3){}
} CACHE_LINE;
void add(const S1 smember[],int members,long &total) {
int idx = members;
do {
total += smember[idx].r1;
total += smember[idx].r2;
total += smember[idx].r3;
}while(--idx);
}
int main (int argc, char *argv[]) {
const int SIZE = 204800;
S1 *smember = (S1 *) malloc (sizeof (S1) * SIZE);
long total = 0L;
int loop = 10000;
while (--loop) { // 方便對比測試
add(smember,SIZE,total);
}
return 0;
}注:代碼邏輯比較簡單就是做一個累加操作,僅僅是為了演示。
編譯+運行:
g++ cache_line.cpp -o cache_line ; task_set -c 1 ./cache_line
下圖是示例cache_line在CPU 1核心上運行,CPU利用率達到99.7%,此時CPU基本上是滿載的,那么我們如何知道這個cpu運行cache_line 服務過程中是否做的都是有用功,是否還有優化空間?

有的同學可能說,可以用perf 進行分析尋找熱點函數。確實是可以使用perf,但是perf只能知道某個函數是熱點(或者是某些匯編指令),但是沒法確認引起熱點的是CPU中的哪些操作存在瓶頸,比如取指令、解碼、.....
如果你還在為判斷是CPU哪些操作導致服務性能瓶頸而不知所措,那么這篇文章將會你給你授道解惑。本文主要通過介紹自頂向下分析方法(TMAM)方法論來快速、精準定位CPU性能瓶頸以及相關的優化建議,幫助大家提升服務性能。為了讓大家更好的理解本文介紹的方法,需要準備些知識。
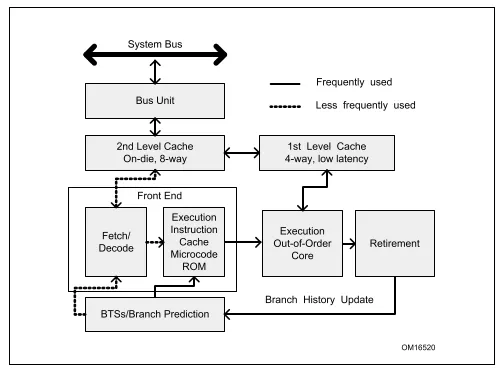
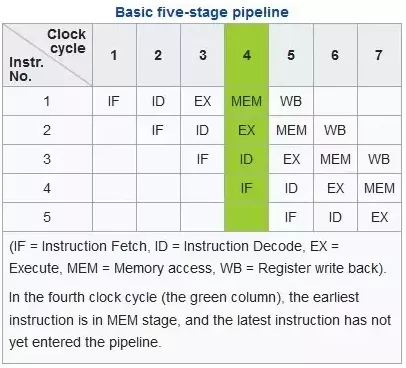
現代的計算機一般都是馮諾依曼計算機模型都有5個核心的組件:運算、存儲、控制、輸入、輸出。本文介紹的方法與CPU有關,CPU執行過程中涉及到取指令、解碼、執行、回寫這幾個最基礎的階段。最早的CPU執行過程中是一個指令按照以上步驟依次執行完之后,才能輪到第二條指令即指令串行執行,很顯然這種方式對CPU各個硬件單元利用率是非常低的,為了提高CPU的性能,Intel引入了多級流水、亂序執行等技術提升性能。一般intel cpu是5級流水線,也就是同一個cycle 可以處理5個不同操作,一些新型CPU中流水線多達15級,下圖展示了一個5級流水線的狀態,在7個CPU指令周期中指令1,2,3已經執行完成,而指令4,5也在執行中,這也是為什么CPU要進行指令解碼的目的:將指令操作不同資源的操作分解成不同的微指令(uops),比如ADD eax,[mem1] 就可以解碼成兩條微指令,一條是從內存[mem1]加載數據到臨時寄存器,另外一條就是執行運算,這樣就可以在加載數據的時候運算單元可以執行另外一條指令的運算uops,多個不同的資源單元可以并行工作。
CPU內部還有很多種資源比如TLB、ALU、L1Cache、register、port、BTB等而且各個資源的執行速度各不相同,有的速度快、有的速度慢,彼此之間又存在依賴關系,因此在程序運行過程中CPU不同的資源會出現各種各樣的約束,本文運用TMAM更加客觀的分析程序運行過程中哪些內在CPU資源出現瓶頸。
TMAM 即 Top-down Micro-architecture Analysis Methodology自頂向下的微架構分析方法。這是Intel CPU 工程師歸納總結用于優化CPU性能的方法論。TMAM 理論基礎就是將各類CPU各類微指令進行歸類從大的方面先確認可能出現的瓶頸,再進一步下鉆分析找到瓶頸點,該方法也符合我們人類的思維,從宏觀再到細節,過早的關注細節,往往需要花費更多的時間。這套方法論的優勢在于:
即使沒有硬件相關的知識也能夠基于CPU的特性優化程序
系統性的消除我們對程序性能瓶頸的猜測:分支預測成功率低?CPU緩存命中率低?內存瓶頸?
快速的識別出在多核亂序CPU中瓶頸點
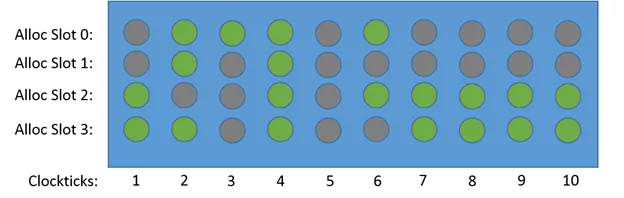
TMAM 評估各個指標過程中采用兩種度量方式一種是cpu時鐘周期(cycle[6]),另外一種是CPU pipeline slot[4]。該方法中假定每個CPU 內核每個周期pipeline都是4個slot即CPU流水線寬是4。下圖展示了各個時鐘周期四個slot的不同狀態,注意只有Clockticks 4 ,cycle 利用率才是100%,其他的都是cycle stall(停頓、氣泡)。
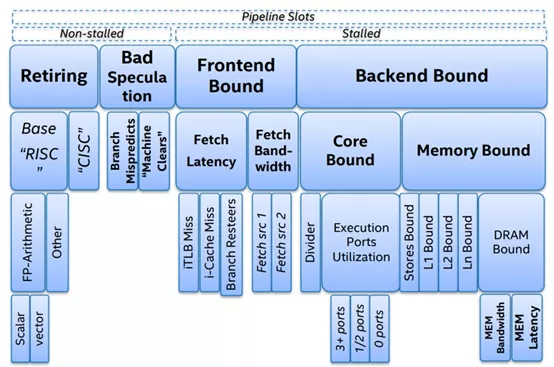
TMAM將各種CPU資源進行分類,通過不同的分類來識別使用這些資源的過程中存在瓶頸,先從大的方向確認大致的瓶頸所在,然后再進行深入分析,找到對應的瓶頸點各個擊破。在TMAM中最頂層將CPU的資源操作分為四大類,接下來介紹下這幾類的含義。
Retiring表示運行有效的uOps 的pipeline slot,即這些uOps[3]最終會退出(注意一個微指令最終結果要么被丟棄、要么退出將結果回寫到register),它可以用于評估程序對CPU的相對比較真實的有效率。理想情況下,所有流水線slot都應該是"Retiring"。100% 的Retiring意味著每個周期的 uOps Retiring數將達到最大化,極致的Retiring可以增加每個周期的指令吞吐數(IPC)。需要注意的是,Retiring這一分類的占比高并不意味著沒有優化的空間。例如retiring中Microcode assists的類別實際上是對性能有損耗的,我們需要避免這類操作。
Bad Speculation表示錯誤預測導致浪費pipeline 資源,包括由于提交最終不會retired的 uOps 以及部分slots是由于從先前的錯誤預測中恢復而被阻塞的。由于預測錯誤分支而浪費的工作被歸類為"錯誤預測"類別。例如:if、switch、while、for等都可能會產生bad speculation。
Front-End 職責:
取指令
將指令進行解碼成微指令
將指令分發給Back-End,每個周期最多分發4條微指令
Front-End Bound表示處理其的Front-End 的一部分slots沒法交付足夠的指令給Back-End。Front-End 作為處理器的第一個部分其核心職責就是獲取Back-End 所需的指令。在Front-End 中由預測器預測下一個需要獲取的地址,然后從內存子系統中獲取對應的緩存行,在轉換成對應的指令,最后解碼成uOps(微指令)。Front-End Bound 意味著,會導致部分slot 即使Back-End 沒有阻塞也會被閑置。例如因為指令cache misses引起的阻塞是可以歸類為Front-End Bound。
Back-End 的職責:
接收Front-End 提交的微指令
必要時對Front-End 提交的微指令進行重排
從內存中獲取對應的指令操作數
執行微指令、提交結果到內存
Back-End Bound 表示部分pipeline slots 因為Back-End缺少一些必要的資源導致沒有uOps交付給Back-End。
Back-End 處理器的核心部分是通過調度器亂序地將準備好的uOps分發給對應執行單元,一旦執行完成,uOps將會根據程序的順序返回對應的結果。例如:像cache-misses 引起的阻塞(停頓)或者因為除法運算器過載引起的停頓都可以歸為此類。此類別可以在進行細分為兩大類:Memory-Bound 、Core Bound。
歸納總結一下就是:
Front End Bound = Bound in Instruction Fetch -> Decode (Instruction Cache, ITLB)
Back End Bound = Bound in Execute -> Commit (Example = Execute, load latency)
Bad Speculation = When pipeline incorrectly predicts execution (Example branch mispredict memory ordering nuke)
Retiring = Pipeline is retiring uops
一個微指令狀態可以按照下圖決策樹進行歸類:
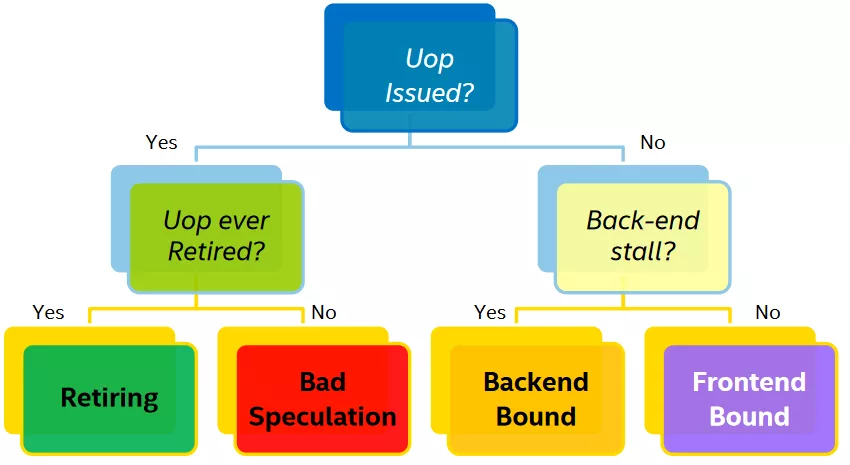
上圖中的葉子節點,程序運行一定時間之后各個類別都會有一個pipeline slot 的占比,只有Retiring 的才是我們所期望的結果,那么每個類別占比應該是多少才是合理或者說性能相對來說是比較好,沒有必要再繼續優化?intel 在實驗室里根據不同的程序類型提供了一個參考的標準:
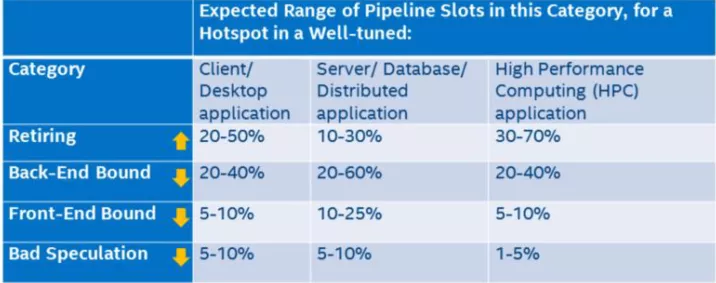
只有Retiring 類別是越高越好,其他三類都是占比越低越好。如果某一個類別占比比較突出,那么它就是我們進行優化時重點關注的對象。
目前有兩個主流的性能分析工具是基于該方法論進行分析的:Intel vtune(收費而且還老貴~),另外一個是開源社區的pm-tools。
有了上面的一些知識之后我們在來看下開始的示例的各分類情況:
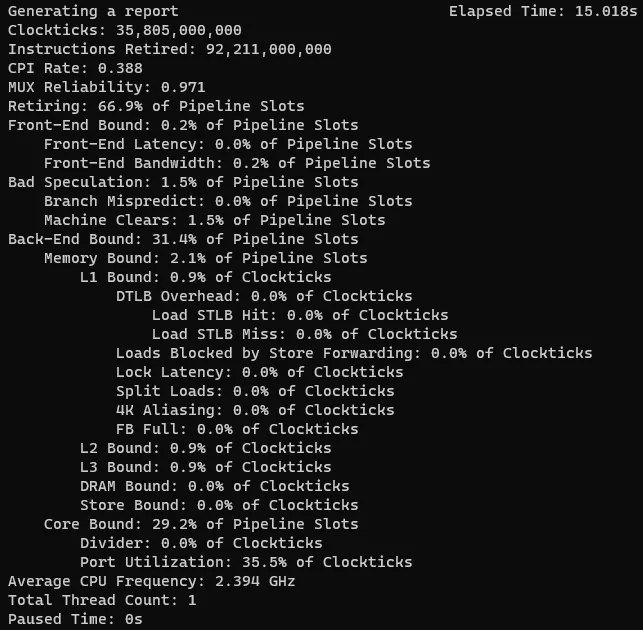
雖然各項指標都在前面的參照表的范圍之內,但是只要retiring 沒有達到100%都還是有可優化空間的。上圖中顯然瓶頸在Back-End。
使用Vtune或者pm-tools 工具時我們應該關注的是除了retired之外的其他三個大分類中占比比較高,針對這些較為突出的進行分析優化。另外使用工具分析工程中需要關注MUX Reliability (多元分析可靠性)這個指標,它越接近1表示當前結果可靠性越高,如果低于0.7 表示當前分析結果不可靠,那么建議加長程序運行時間以便采集足夠的數據進行分析。下面我們來針對三大分類進行分析優化。
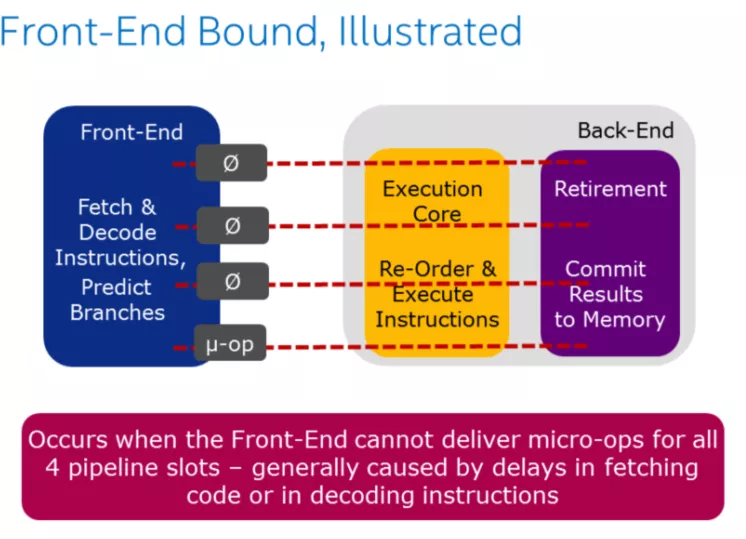
上圖中展示了Front-End的職責即取指令(可能會根據預測提前取指令)、解碼、分發給后端pipeline, 它的性能受限于兩個方面一個是latency、bandwidth。對于latency,一般就是取指令(比如L1 ICache、iTLB未命中或解釋型編程語言python\java等)、decoding (一些特殊指令或者排隊問題)導致延遲。當Front-End 受限了,pipeline利用率就會降低,下圖非綠色部分表示slot沒有被使用,ClockTicks 1 的slot利用率只有50%。對于BandWidth 將它劃分成了MITE,DSB和LSD三個子類,感興趣的同學可以通過其他途徑了解下這三個子分類。
3.3.1.1 于Front-End的優化建議:代碼盡可能減少代碼的footprint7:
C/C++可以利用編譯器的優化選項來幫助優化,比如GCC -O* 都會對footprint進行優化或者通過指定-fomit-frame-pointer也可以達到效果;
充分利用CPU硬件特性:宏融合(macro-fusion)
宏融合特性可以將2條指令合并成一條微指令,它能提升Front-End的吞吐。 示例:像我們通常用到的循環:
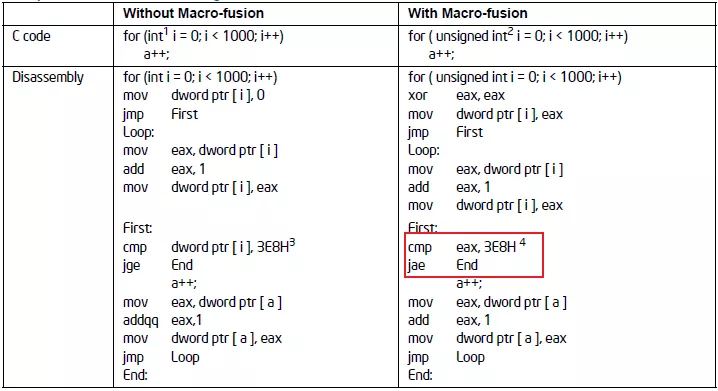
所以建議循環條件中的類型采用無符號的數據類型可以使用到宏融合特性提升Front-End 吞吐量。
調整代碼布局(co-locating-hot-code):
①充分利用編譯器的PGO 特性:-fprofile-generate -fprofile-use
②可以通過__attribute__ ((hot)) __attribute__ ((code))來調整代碼在內存中的布局,hot的代碼
在解碼階段有利于CPU進行預取。
其他優化選項,可以參考:GCC優化選項GCC通用屬性選項
分支預測優化
① 消除分支可以減少預測的可能性能:比如小的循環可以展開比如循環次數小于64次(可以使用GCC選項 -funroll-loops)
② 盡量用if 代替:?,不建議使用a=b>0? x:y因為這個是沒法做分支預測的
③ 盡可能減少組合條件,使用單一條件比如:if(a||b) {}else{}這種代碼CPU沒法做分支預測的
④對于多case的switch,盡可能將最可能執行的case 放在最前面
⑤ 我們可以根據其靜態預測算法投其所好,調整代碼布局,滿足以下條件:
前置條件,使條件分支后的的第一個代碼塊是最有可能被執行的
bool is_expect = true;
if(is_expect) {
// 被執行的概率高代碼盡可能放在這里
} else {
// 被執行的概率低代碼盡可能放在這里
}
后置條件,使條件分支的具有向后目標的分支不太可能的目標
do {
// 這里的代碼盡可能減少運行
} while(conditions);這一類別的優化涉及到CPU Cache的使用優化,CPU cache[14]它的存在就是為了彌補超高速的 CPU與DRAM之間的速度差距。CPU 中存在多級cache(register\L1\L2\L3) ,另外為了加速virtual memory address 與 physical address 之間轉換引入了TLB。
如果沒有cache,每次都到DRAM中加載指令,那這個延遲是沒法接受的。
3.3.2.1 優化建議:
調整算法減少數據存儲,減少前后指令數據的依賴提高指令運行的并發度
根據cache line調整數據結構的大小
避免L2、L3 cache偽共享
(1)合理使用緩存行對齊
CPU的緩存是彌足珍貴的,應該盡量的提高其使用率,平常使用過程中可能存在一些誤區導致CPU cache有效利用率比較低。下面來看一個不適合進行緩存行對齊的例子:
#include <stdlib.h>
#define CACHE_LINE
struct S1
{
int r1;
int r2;
int r3;
S1 ():r1 (1), r2 (2), r3 (3){}
} CACHE_LINE;
int main (int argc, char *argv[])
{
// 與前面一致
}下面這個是測試效果:

做了緩存行對齊:
#include <string.h>
#include <stdio.h>
#define CACHE_LINE __attribute__((aligned(64)))
struct S1 {
int r1;
int r2;
int r3;
S1(): r1(1),r2(2),r3(3){}
} CACHE_LINE;
int main(int argc,char* argv[]) {
// 與前面一致
}測試結果:

通過對比兩個retiring 就知道,這種場景下沒有做cache 對齊緩存利用率高,因為在單線程中采用了緩存行導致cpu cache 利用率低,在上面的例子中緩存行利用率才3*4/64 = 18%。緩存行對齊使用原則:
多個線程存在同時寫一個對象、結構體的場景(即存在偽共享的場景)
對象、結構體過大的時候
將高頻訪問的對象屬性盡可能的放在對象、結構體首部
(2)偽共享
前面主要是緩存行誤用的場景,這里介紹下如何利用緩存行解決SMP 體系下的偽共享(false shared)。多個CPU同時對同一個緩存行的數據進行修改,導致CPU cache的數據不一致也就是緩存失效問題。為什么偽共享只發生在多線程的場景,而多進程的場景不會有問題?這是因為linux 虛擬內存的特性,各個進程的虛擬地址空間是相互隔離的,也就是說在數據不進行緩存行對齊的情況下,CPU執行進程1時加載的一個緩存行的數據,只會屬于進程1,而不會存在一部分是進程1、另外一部分是進程2。
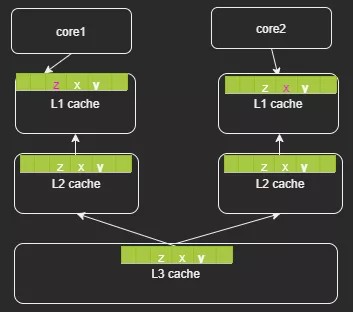
(上圖中不同型號的L2 cache 組織形式可能不同,有的可能是每個core 獨占例如skylake)
偽共享之所以對性能影響很大,是因為他會導致原本可以并行執行的操作,變成了并發執行。這是高性能服務不能接受的,所以我們需要對齊進行優化,方法就是CPU緩存行對齊(cache line align)解決偽共享,本來就是一個以空間換取時間的方案。比如上面的代碼片段:
#define CACHE_LINE __attribute__((aligned(64)))
struct S1 {
int r1;
int r2;
int r3;
S1(): r1(1),r2(2),r3(3){}
} CACHE_LINE;所以對于緩存行的使用需要根據自己的實際代碼區別對待,而不是人云亦云。
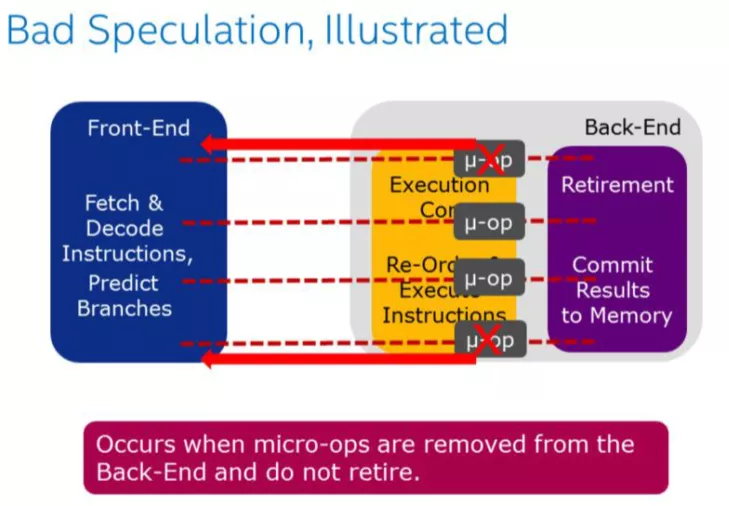
當Back-End 刪除了微指令,就出現Bad Speculation,這意味著Front-End 對這些指令所作的取指令、解碼都是無用功,所以為什么說開發過程中應該盡可能的避免出現分支或者應該提升分支預測準確度能夠提升服務的性能。雖然CPU 有BTB記錄歷史預測情況,但是這部分cache 是非常稀缺,它能緩存的數據非常有限。
分支預測在Font-End中用于加速CPU獲取指定的過程,而不是等到需要讀取指令的時候才從主存中讀取指令。Front-End可以利用分支預測提前將需要預測指令加載到L2 Cache中,這樣CPU 取指令的時候延遲就極大減小了,所以這種提前加載指令時存在誤判的情況的,所以我們應該避免這種情況的發生,c++常用的方法就是:
在使用if的地方盡可能使用gcc的內置分支預測特性(其他情況可以參考Front-End章節)
#define likely(x) __builtin_expect(!!(x), 1) //gcc內置函數, 幫助編譯器分支優化
#define unlikely(x) __builtin_expect(!!(x), 0)
if(likely(condition)) {
// 這里的代碼執行的概率比較高
}
if(unlikely(condition)) {
// 這里的代碼執行的概率比較高
}
// 盡量避免遠調用避免間接跳轉或者調用
在c++中比如switch、函數指針或者虛函數在生成匯編語言的時候都可能存在多個跳轉目標,這個也是會影響分支預測的結果,雖然BTB可改善這些但是畢竟BTB的資源是很有限的。(intel P3的BTB 512 entry ,一些較新的CPU沒法找到相關的數據)
這里我們再看下最開始的例子,采用上面提到的優化方法優化完之后的評測效果如下:
g++ cache_line.cpp -o cache_line -fomit-frame-pointer; task_set -c 1 ./cache_line
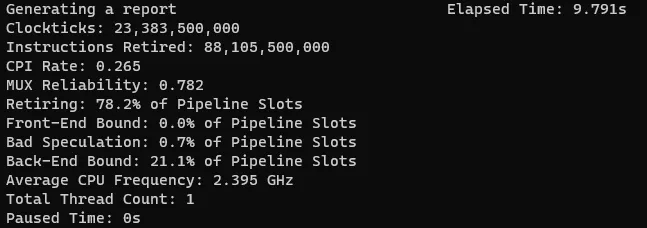
耗時從原來的15s 降低到現在9.8s,性能提升34%:retiring 從66.9% 提升到78.2% ;Back-End bound 從31.4%降低到21.1%
[1] CPI(cycle per instruction) 平均每條指令的平均時鐘周期個數
[2] IPC (instruction per cycle) 每個CPU周期的指令吞吐數
[3] uOps 現代處理器每個時鐘周期至少可以譯碼 4 條指令。譯碼過程產生很多小片的操作,被稱作微指令(micro-ops, uOps)
[4] pipeline slot pipeline slot 表示用于處理uOps 所需要的硬件資源,TMAM中假定每個 CPU core在每個時鐘周期中都有多個可用的流水線插槽。流水線的數量稱為流水線寬度。
[5] MIPS(MillionInstructions Per Second) 即每秒執行百萬條指令數 MIPS= 1/(CPI×時鐘周期)= 主頻/CPI
[6]cycle 時鐘周期:cycle=1/主頻
[7] memory footprint 程序運行過程中所需要的內存大小.包括代碼段、數據段、堆、調用棧還包括用于存儲一些隱藏的數據比如符號表、調試的數據結構、打開的文件、映射到進程空間的共享庫等。
到此,相信大家對“C/C++的性能如何優化”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





