溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據是互聯網公司的核心資產,所以好多公司在架構設計上不僅要保證業務系統的高可用,同時還要考慮數據存儲的高可用以及安全性。在職公司是一家創業型公司,之前的應用系統是由.Net 和SQLserver組合的架構,由于存在業務量的增長,技術部門采用Java重構整個應用系統。數據庫選擇開源數據庫MYSQL,從剛開始都現在踩了相當多的坑,在此給大家分享一下。
環境介紹:
磁盤類型:SSD
操作系統:CentOS6.5 64位
軟件版本:5.5.50-MariaDB-wsrep
1、數據庫高可用方案選型
目前針對mysql的高可用方案還是比較多,例如主從、MMM或者MHA等 ,我們初期考慮使用Keepalived+Mysql(雙主熱備)方案,但是由于阿里云不能很好的支持虛擬IP,所以想著使用其他方案,最好有集群解決方案,最后選用MariaDBGalera Cluster。3個節點組成一個集群,前端使用阿里云SLB實現負載均衡,減輕數據庫壓力。
MariaDB Galera Cluster主要功能
同步復制
真正的multi-master,即所有節點可以同時讀寫數據庫
自動的節點成員控制,失效節點自動被清除
新節點加入數據自動復制
真正的并行復制,行級
用戶可以直接連接集群,使用感受上與MySQL完全一致
優勢:
因為是多主,所以不存在Slavelag(延遲)
不存在丟失事務的情況
同時具有讀和寫的擴展能力
更小的客戶端延遲
節點間數據是同步的,而Master/Slave模式是異步的,不同slave上的binlog可能是不同的
線上環境數據庫架構圖
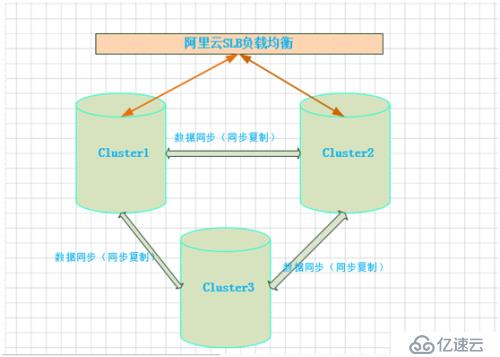
1、cluster1與cluster2由SLB調度,實現數據庫負載均衡,應用程序可以連接cluster1和cluster2寫入和讀取。Slave3主要實現數據校驗和備份。
踩過的坑:
1、數據容量規劃嚴重不合理
由于是創業公司,研發人員和運維人員經驗不足,在整個系統設計服務器采購時磁盤容量規劃不合理,數據增長迅速,容量不足,最后采取添加硬盤,由于服務器是使用的阿里云主機,所以想著磁盤擴容比較簡單,從阿里云控制臺購買磁盤容量后,重啟主機(遠程連接reboot重啟),用fdisk等命令檢查磁盤,發現擴容的部分沒有生效,折騰好久,最后給阿里云售后打電話解決,更改硬件配置需要在阿里云控制臺重啟。
2、mysql獨立表空間和共享表空間
這個坑也是在上面容量使用上發現的,因為部分mysql默認使用獨立表空間,而5.5.50-MariaDB-wsrep是默認使用共享表空間,由于前期經驗不足,沒有更改這些,每天業務量比較大,所以數據量增長比較快,有一天發現mysql目錄下. Ibdata文件已經是80多G,查找相關資料是獨立表空間以及共享表空間問題,里面包含redo log以及每個表的數據和索引等。由于我們的數據存在時效性,所以超過一個月的就轉移到歷史庫,然后將主庫相關表刪除,而共享表空間對這種大量刪除的支持不是很好,所以我們將整個數據庫的表空間進行轉換。下面簡單介紹一下獨立表空間和共享表空間,
共享表空間: 某一個數據庫的所有的表數據,索引文件全部放在一個文件中,默認這個共享表空間的文件路徑在data目錄下。默認的文件名為:ibdata1 初始化為10M。
獨立表空間: 每一個表都將會生成以獨立的文件方式來進行存儲,每一個表都有一個.frm表描述文件,還有一個.ibd文件。其中這個文件包括了單獨一個表的數據內容以及索引內容,默認情況下它的存儲位置也是在表的位置之中。
兩者之間的優缺點
共享表空間:
優點:
可以放表空間分成多個文件存放到各個磁盤上(表空間文件大小不受表大小的限制,如一個表可以分布在不同步的文件上)。數據和文件放在一起方便管理。
缺點:
所有的數據和索引存放到一個文件中以為著將有一個很常大的文件,雖然可以把一個大文件分成多個小文件,但是多個表及索引在表空間中混合存儲,這樣對于一個表做了大量刪除操作后表空間中將會有大量的空隙,特別是對于統計分析,日值系統這類應用最不適合用共享表空間。
innodb_file_per_table=1 為使用獨占表空間
innodb_file_per_table=0 為使用共享表空間
獨立表空間優點:
1.每個表都有自已獨立的表空間。
2.每個表的數據和索引都會存在自已的表空間中。
3.可以實現單表在不同的數據庫中移動。
4.空間可以回收(除drop table操作處,表空不能自已回收)
a) Drop table操作自動回收表空間,如果對于統計分析或是日值表,刪除大量數據后可以通過:alter table TableNameengine=innodb;回縮不用的空間。
b) 對于使innodb-plugin的Innodb使用turncate table也會使空間收縮。
c) 對于使用獨立表空間的表,不管怎么刪除,表空間的碎片不會太嚴重的影響性能,而且還有機會處理。
缺點:
單表增加過大,如超過100個G。
3、 共享表空間向獨立表空間的轉換
由于我們的數據有時效性,所以需要數據轉移和對原來庫的表刪除,需要將
默認的共享表空間轉換成獨立表空間。
轉換方案:
1、將數據mysqldump邏輯備份,更改配置文件,重啟數據庫,將之前的數據庫drop掉,導入新的數據。
2、 直接更改配置文件重啟數據庫。
兩者的區別
方案1是比較徹底的做法,但是數據量比較大是整個過程就會很慢,因為mysqldump的邏輯備份是備份成SQL整個過程比較費時間。而方案2 是比較折中的解決方案,這樣做對已經創建的數據表結構不會有影響,后期創建的表結構才會使用獨立表空間。
對我們來說方案1更徹底,數據量有200多G,由于我們的多數記錄表是按月分表,部分數據可以成為冷數據(一般情況下不會更改)。所以我們將這些冷數據先備份出來,導入到其他庫檢驗完整性,然后將部分業務停掉處理那些業務邏輯等數據。
4、 mysqldump數據分庫備份
有經驗的運維或者DBA肯定不會用mysqldump備份大量的數據因為很慢,但是我們由于經驗不足在此又踩了一個坑。用腳本和定時任務的方式實現數據備份,每周6晚上2點備份,前期數據量比較小整個業務系統正常,后面當數據突破100多G后,就出現一個比較奇怪的事情,每周六早上應用系統總是異常,研發人員都很郁悶,感覺跟見鬼一樣,經過多次出現該問題后就考慮數據備份,研究任務執行情況,發現確實是數據備份問題,后面就采取xtrabackup備份。
腳本:
#/bin/bash
MYUSER=mysqlback
MYPASS=databack***
#SOCKET=/data/3306/mysql.sock
MYLOGIN="mysql -u$MYUSER -p$MYPASS "
MYDUMP="mysqldump -u$MYUSER -p$MYPASS -B"
DATABASE="$($MYLOGIN -e "show databases;"|egrep -vi"Data|_schema|mysql")"
for dbname in $DATABASE
do
MYDIR=/data/backup/$dbname
[ ! -d $MYDIR ] &&mkdir -p $MYDIR
$MYDUMP $dbname|gzip>$MYDIR/${dbname}_$(date +%F).sql.gz
done5、共享表空間轉換獨立表空間更改數據庫配置報錯
配置文件: [server] # this is only for the mysqld standalone daemon [mysqld] skip-name-resolve character-set-server=utf8 datadir=/data/mysql wait_timeout=1800 interactive_timeout = 288000 max_allowed_packet = 1000M #max_connections=3000 max_connections=3000 character-set-server=utf8 #innodb_buffer_pool_size = 1000M innodb_additional_mem_pool_size = 200M innodb_flush_log_at_trx_commit=2 innodb_autoextend_increment=800M #innodb_log_buffer_size = 200M innodb_log_file_size = 100M key_buffer_size=800M read_buffer_size=600M thread_cache_size=64 innodb_file_per_table=1 #獨立表空間 #innodb_flush_log_at_trx_commit=2 #innodb_log_file_size=1G #(日志文件) innodb_buffer_pool_size=6G
為了適當的優化數據庫性能,所以將參數做了適當的調整,這時比較坑的問題就出現了,數據庫集群只能啟動其中的一臺,另外的兩臺都是報錯,這時肯定是查看日志解決問題,看下面日志是配置文件參數設置問題導致,將更改配置文件逐個檢查,最后發現是有3個innodb_buffer_pool_size參數不一致(3臺服務器集群 基本配置差不多,區別就是一臺上面還有其他應用程序在運行,所以就將其設置的小一點,導致整個系統啟動異常)
部分日志:
InnoDB: Error: log file ./ib_logfile0 is of different size 0 104857600 bytes
InnoDB: than specified in the .cnf file 0 1073741824 bytes!
InnoDB: Possible causes for this error:
(a) Incorrect log file is used or log file size is changed
(b) In case default size is used this log file is from 10.0
(c) Log file is corrupted or there was not enough disk space
In case (b) you need to set innodb_log_file_size = 48M
170412 23:53:26 [ERROR] Plugin 'InnoDB' init function returned error.
170412 23:53:26 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed.
170412 23:53:26 [Note] Plugin 'FEEDBACK' is disabled.
170412 23:53:26 [ERROR] Unknown/unsupported storage engine: innodb
170412 23:53:26 [ERROR] Aborting
170412 23:53:28 [Note] WSREP: Closing send monitor...
170412 23:53:28 [Note] WSREP: Closed send monitor.
170412 23:53:28 [Note] WSREP: gcomm: terminating thread
170412 23:53:28 [Note] WSREP: gcomm: joining thread
170412 23:53:28 [Note] WSREP: gcomm: closing backend
170412 23:53:29 [Note] WSREP: view(view_id(NON_PRIM,1d5436dc,2) memb {
1d5436dc,0
} joined {
} left {
} partitioned {
effca7a8,0免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





