溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Hadoop模式架構是怎么樣的,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
一、Hadoop 1.0的模型:
|
split 0->map-[sort]->[1,3..]| /merge
| ==> reducer-->part 0=>HDFS replication
split 1->map-[sort]->[2,6..]|—————————————
| ==> reducre--->part 1 =>HDFS replication
split 2->map-[sort]->[4,2..]|
|
|
//INPUT HDFS| //output HDFS
//啟動有3個map,reducer只啟動了2個,sort:本地排序后發送給reducer
相同的key發送到同一個reducer
//merge:把多個數據流整合為一個數據流
工作流程:
Client--->Job--->Hadoop MapReduce master
|
|
V
/ \
Job parts Job parts
| |
VV
[Input]-- map1reduceA---->[Output]
[Data ]---map2 =》reduceB---->[Data ]
\__map3
//其中map1,2,3和reduceA,B是交叉使用的。也就是說map1可以同時對應reduceA和reduceB,其他的也都可以
//MapReduce將需要處理的任務分成兩個部分,Map和Reduce
Client App
(MapReduce Client)----> Job Tracker
|
____________________|_____________________________
[task tracker1] [task tracker1] [task tracker1]
map reduce reduce reduce map map reduce map
JobTracker:有任務列表,以及狀態信息
JobA---->[map task1]
JobB[map task2]
JobC[map task3]
...[reduce task 1]
[reduce task 2]
//任何一個task tracker能夠運行的任務數量是有限的,可以進行定義
//任務槽:決定可以運行多少個job
Jobtracker:
1.負責任務分發
2.檢查Task tracker狀態,tracker故障重啟等
3.監控任務的狀態
Job tracker存在單點故障的問題,在hadoop2.0后這幾個功能分別實現了
Mapreduce 2.0之后切割為兩部分
二、HadooP 1.0 和 2.0
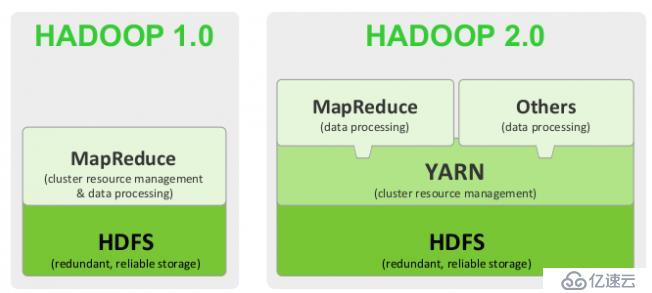
1.0: pig:data flow,Hive:sql ,
2.0: MR:batch批處理,Pig:data flow,Hive:sql
RT:stream graph:實時流式圖形處理
Tez:execution engine//執行引擎
MRv1:cluster resouce manager,Data procession
MRV2:
1.YARN:Cluster resource manager
Yet Another Resource Negotiator,另一種資源協調者
2.MRv2:Data procession
MR:batch作業
Tez:execution engine //提供運行時環境
可以直接在YARN之上的程序有:
MapReduce:Batch,Tez,HBase,Streaming,Graph,SPark,HPC MPI[高性能],Weave
Hadoop2.0
clinet-->RM--->node1/node2/node n...
Resouce Manager: RM是獨立的
node上運行的有[node manager+App Master+ Container]
Node manager:NM,運行在各node上,周期向RM報告node信息,
clinet請求作業:node上的Application master決定要啟動幾個mapper幾個 reducer
mapper和reducer 稱為 Container //作業都在容器內運行。
Application master只有一個,且同一個任務的APP M只在一個節點上,但是Container會分別運行在多個節點上,并周期向APP M報告其處理狀態
APP M向RM報告任務運行狀況,在任務執行完畢后,RM會把APP M關閉
某一個任務故障后,由App M進行管理,而不是RM管理
2.0工作模型
A 【NM/Container 1/APP M(B)】
\/
【RM】 -- 【NM/Container 2/APP M(A)】
/\
B 【NM/Container 3 /A&A 】
//任務 A運行了3個container,在兩個節點上
//任務B運行了1個container,在一個節點上
Mapreduce status:container向APP M報告 //container包括map和reducer任務
Job submission:
node status:NM周期向RM報告
Resouce Request :由App M向RM申請,然后APP M就可以使用其他node 的container
client請求-->RM查找空閑node,空閑node上運行APP M-->APP M向RM申請運行container資源,RM向NM提請container,RM分配好coantainer后,告訴給APP M
APP M使用container運行任務。Container在運行過程中,不斷向APP M反饋自己的狀態和進度,APP M向RM報告運行狀態。
APP M報告運行完成,RM收回container和關閉APP M
RM:resource manager
NM:node manager
AM:application master
container:mr任務運行
Hadoop 發展路線:
2003 nutch //蜘蛛程序
2004-2006:Mapreduce + GFS,論文
2011:hadoop 1.0.0
2013:hadoop 2.0
http://hadoop.apache.org/
可以直接在YARN之上的程序有:
MapReduce:Batch,Tez,HBase,Streaming,Graph,SPark,HPC MPI[高性能],Weave
三、Hadoop 2.0生態系統與基本組件
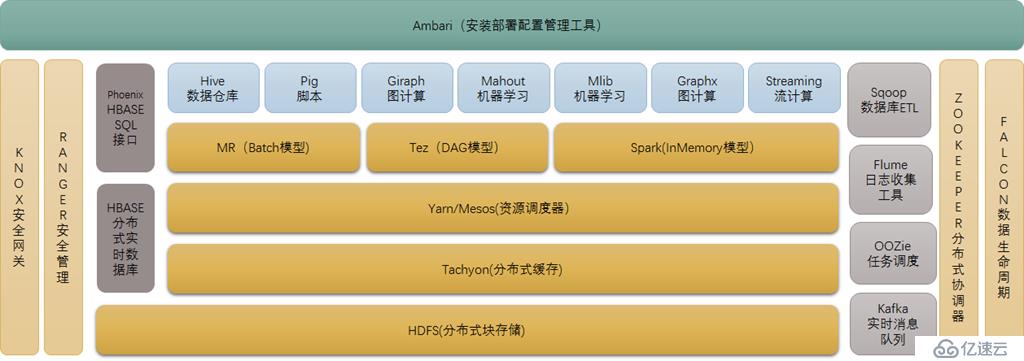
//在YARN之上是依賴于YARN的,其他的都是可以獨立使用的
源自于Google的GFS論文,發表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop體系中數據存儲管理的基礎。它是一個高度容錯的系統,能檢測和應對硬件故障,用于在低成本的通用硬件上運行。
HDFS簡化了文件的一致性模型,通過流式數據訪問,提供高吞吐量應用程序數據訪問功能,適合帶有大型數據集的應用程序。
它提供了一次寫入多次讀取的機制,數據以塊的形式,同時分布在集群不同物理機器上。
源自于google的MapReduce論文,發表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一種分布式計算模型,用以進行大數據量的計算。它屏蔽了分布式計算框架細節,將計算抽象成map和reduce兩部分,
其中Map對數據集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。
MapReduce非常適合在大量計算機組成的分布式并行環境里進行數據處理。
4. HBASE(分布式列存數據庫)
源自Google的Bigtable論文,發表于2006年11月,HBase是Google Bigtable克隆版
HBase是一個建立在HDFS之上,面向列的針對結構化數據的可伸縮、高可靠、高性能、分布式和面向列的動態模式數據庫。
HBase采用了BigTable的數據模型:增強的稀疏排序映射表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。
HBase提供了對大規模數據的隨機、實時讀寫訪問,同時,HBase中保存的數據可以使用MapReduce來處理,它將數據存儲和并行計算完美地結合在一起。
HBase:山寨版的BitTable,列式存儲,SQL為行式存儲。
列祖:把多個常用的列存放在一個中。
cell:行和列的交叉位置,每個cell在存儲時,可以多版本共存,之前的版本不會被刪除,可以追溯老版本。
可以指定保存幾個版本。每個cell都是鍵值對,任何一個行多一個字段或者少一個字段,都是可以的,沒有強schema約束
HBASE是工作在HDFS之上,轉化為chunk的
需要用到大數據塊時,讀取到HBase中,進行讀取和修改,然后覆蓋或者寫入HDFS
從而實現隨機讀寫。HDFS是不支持隨機讀寫的
HBase接口:
HBase基于分布式實現:需要另起一套集群,嚴重依賴于ZooKeeper解決腦裂
HDFS本身就有冗余功能,每個chunk存儲為了多個副本
HBase作為面向列的數據庫運行在HDFS之上,HDFS缺乏隨即讀寫操作,HBase正是為此而出現。
HBase以Google BigTable為藍本,以鍵值對的形式存儲。項目的目標就是快速在主機內數十億行數據中定位所需的數據并訪問它。
HBase是一個數據庫,一個NoSql的數據庫,像其他數據庫一樣提供隨即讀寫功能,Hadoop不能滿足實時需要,HBase正可以滿足。
如果你需要實時訪問一些數據,就把它存入HBase。
你可以用Hadoop作為靜態數據倉庫,HBase作為數據存儲,放那些進行一些操作會改變的數據
5. Zookeeper(分布式協作服務)
源自Google的Chubby論文,發表于2006年11月,Zookeeper是Chubby克隆版
解決分布式環境下的數據管理問題:統一命名,狀態同步,集群管理,配置同步等。
Hadoop的許多組件依賴于Zookeeper,它運行在計算機集群上面,用于管理Hadoop操作。
6. HIVE(數據倉庫)小蜜蜂
由facebook開源,最初用于解決海量結構化的日志數據統計問題。
Hive定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行。通常用于離線分析。
HQL用于運行存儲在Hadoop上的查詢語句,Hive讓不熟悉MapReduce開發人員也能編寫數據查詢語句,然后這些語句被翻譯為Hadoop上面的MapReduce任務。
Hive:幫忙轉換成MapReduce任務//MapReduce:是bat程序,速度較慢
HQ與SQl語句接近,適合在離線下進行數據的操作,在真實的生產環境中進行實時的在線查詢或操作很“慢”
Hive在Hadoop中扮演數據倉庫的角色。
你可以用 HiveQL進行select,join,等等操作。
如果你有數據倉庫的需求并且你擅長寫SQL并且不想寫MapReduce jobs就可以用Hive代替。
熟悉SQL的朋友可以使用Hive對離線的進行數據處理與分析工作
7.Pig(ad-hoc腳本)
由yahoo!開源,設計動機是提供一種基于MapReduce的ad-hoc(計算在query時發生)數據分析工具
Pig定義了一種數據流語言—Pig Latin,它是MapReduce編程的復雜性的抽象,Pig平臺包括運行環境和用于分析Hadoop數據集的腳本語言(Pig Latin)。
其編譯器將Pig Latin翻譯成MapReduce程序序列將腳本轉換為MapReduce任務在Hadoop上執行。通常用于進行離線分析。
Pig:腳本編程語言接口 一種操作hadoop的輕量級腳本語言,最初又雅虎公司推出,不過現在正在走下坡路了。
不過個人推薦使用Hive
8.Sqoop(數據ETL/同步工具)
Sqoop是SQL-to-Hadoop的縮寫,主要用于傳統數據庫和Hadoop之前傳輸數據。數據的導入和導出本質上是Mapreduce程序,充分利用了MR的并行化和容錯性。
Sqoop利用數據庫技術描述數據架構,用于在關系數據庫、數據倉庫和Hadoop之間轉移數據。
9.Flume(日志收集工具)
Cloudera開源的日志收集系統,具有分布式、高可靠、高容錯、易于定制和擴展的特點。
它將數據從產生、傳輸、處理并最終寫入目標的路徑的過程抽象為數據流,在具體的數據流中,數據源支持在Flume中定制數據發送方,從而支持收集各種不同協議數據。
同時,Flume數據流提供對日志數據進行簡單處理的能力,如過濾、格式轉換等。此外,Flume還具有能夠將日志寫往各種數據目標(可定制)的能力。
總的來說,Flume是一個可擴展、適合復雜環境的海量日志收集系統。當然也可以用于收集其他類型數據
Mahout起源于2008年,最初是Apache Lucent的子項目,它在極短的時間內取得了長足的發展,現在是Apache的頂級項目。
Mahout的主要目標是創建一些可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程序。
Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的數據挖掘方法。
除了算法,Mahout還包含數據的輸入/輸出工具、與其他存儲系統(如數據庫、MongoDB 或Cassandra)集成等數據挖掘支持架構。
11. Oozie(工作流調度器)
Oozie是一個可擴展的工作體系,集成于Hadoop的堆棧,用于協調多個MapReduce作業的執行。它能夠管理一個復雜的系統,基于外部事件來執行,外部事件包括數據的定時和數據的出現。
Oozie工作流是放置在控制依賴DAG(有向無環圖 Direct Acyclic Graph)中的一組動作(例如,Hadoop的Map/Reduce作業、Pig作業等),其中指定了動作執行的順序。
Oozie使用hPDL(一種XML流程定義語言)來描述這個圖。
12. Yarn(分布式資源管理器)
- 資源管理:包括應用程序管理和機器資源管理
- 資源雙層調度
- 容錯性:各個組件均有考慮容錯性
- 擴展性:可擴展到上萬個節點
13. Mesos(分布式資源管理器)
Mesos誕生于UC Berkeley的一個研究項目,現已成為Apache項目,當前有一些公司使用Mesos管理集群資源,比如Twitter。
與yarn類似,Mesos是一個資源統一管理和調度的平臺,同樣支持比如MR、steaming等多種運算框架。
14. Tachyon(分布式內存文件系統)
Tachyon(/'tki:n/ 意為超光速粒子)是以內存為中心的分布式文件系統,擁有高性能和容錯能力,
能夠為集群框架(如Spark、MapReduce)提供可靠的內存級速度的文件共享服務。
Tachyon誕生于UC Berkeley的AMPLab。
15. Tez(DAG計算模型)
Tez是Apache最新開源的支持DAG作業的計算框架,它直接源于MapReduce框架,核心思想是將Map和Reduce兩個操作進一步拆分,
即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,
這樣,這些分解后的元操作可以任意靈活組合,產生新的操作,這些操作經過一些控制程序組裝后,可形成一個大的DAG作業。
目前hive支持mr、tez計算模型,tez能完美二進制mr程序,提升運算性能。
16. Spark(內存DAG計算模型)
Spark是一個Apache項目,它被標榜為“快如閃電的集群計算”。它擁有一個繁榮的開源社區,并且是目前最活躍的Apache項目。
最早Spark是UC Berkeley AMP lab所開源的類Hadoop MapReduce的通用的并行計算框架。
Spark提供了一個更快、更通用的數據處理平臺。和Hadoop相比,Spark可以讓你的程序在內存中運行時速度提升100倍,或者在磁盤上運行時速度提升10倍
17. Giraph(圖計算模型)
Apache Giraph是一個可伸縮的分布式迭代圖處理系統, 基于Hadoop平臺,靈感來自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
最早出自雅虎。雅虎在開發Giraph時采用了Google工程師2010年發表的論文《Pregel:大規模圖表處理系統》中的原理。后來,雅虎將Giraph捐贈給Apache軟件基金會。
目前所有人都可以下載Giraph,它已經成為Apache軟件基金會的開源項目,并得到Facebook的支持,獲得多方面的改進。
18. GraphX(圖計算模型)
Spark GraphX最先是伯克利AMPLAB的一個分布式圖計算框架項目,目前整合在spark運行框架中,為其提供BSP大規模并行圖計算能力。
19. MLib(機器學習庫)
Spark MLlib是一個機器學習庫,它提供了各種各樣的算法,這些算法用來在集群上針對分類、回歸、聚類、協同過濾等。
20. Streaming(流計算模型)
Spark Streaming支持對流數據的實時處理,以微批的方式對實時數據進行計算
21. Kafka(分布式消息隊列)
Kafka是Linkedin于2010年12月份開源的消息系統,它主要用于處理活躍的流式數據。
活躍的流式數據在web網站應用中非常常見,這些數據包括網站的pv、用戶訪問了什么內容,搜索了什么內容等。
這些數據通常以日志的形式記錄下來,然后每隔一段時間進行一次統計處理。
22. Phoenix(hbase sql接口)
Apache Phoenix 是HBase的SQL驅動,Phoenix 使得Hbase 支持通過JDBC的方式進行訪問,并將你的SQL查詢轉換成Hbase的掃描和相應的動作。
23. ranger(安全管理工具)
Apache ranger是一個hadoop集群權限框架,提供操作、監控、管理復雜的數據權限,它提供一個集中的管理機制,管理基于yarn的hadoop生態圈的所有數據權限。
24. knox(hadoop安全網關)
Apache knox是一個訪問hadoop集群的restapi網關,它為所有rest訪問提供了一個簡單的訪問接口點,能完成3A認證(Authentication,Authorization,Auditing)和SSO(單點登錄)等
25. falcon(數據生命周期管理工具)
Apache Falcon 是一個面向Hadoop的、新的數據處理和管理平臺,設計用于數據移動、數據管道協調、生命周期管理和數據發現。它使終端用戶可以快速地將他們的數據及其相關的處理和管理任務“上載(onboard)”到Hadoop集群。
26.Ambari(安裝部署配置管理工具)
Apache Ambari 的作用來說,就是創建、管理、監視 Hadoop 的集群,是為了讓 Hadoop 以及相關的大數據軟件更容易使用的一個web工具。
注意:Hadoop盡量不要運行在虛擬機上,因為對IO影響比較大
Hadoop Distribution:
社區版:Apache Hadoop
第三方發行版:
Cloudera:hadoop源創始人:CDH //iso鏡像,最成型的
Hortonworks:原有的hadoop人員:HDP //iso鏡像,非開源
Intel:IDH
MapR:
Amazon Elastic Map Reduce(EMR)
推薦使用Apache hadoop或者CDH
以上是“Hadoop模式架構是怎么樣的”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





